
|
Getting your Trinity Audio player ready...
|
By Mariya Dimitrova, Georgi Zhelezov, Teodor Georgiev and Lyubomir Penev
The use of written language to record new knowledge is one of the advancements of civilisation that has helped us achieve progress. However, in the era of Big Data, the amount of published writing greatly exceeds the physical ability of humans to read and understand all written information.
More than ever, we need computers to help us process and manage written knowledge. Unlike humans, computers are “naturally fluent” in many languages, such as the formats of the Semantic Web. These standards were developed by the World Wide Web Consortium (W3C) to enable computers to understand data published on the Internet. As a result, computers can index web content and gather data and metadata about web resources.
To help manage knowledge in different domains, humans have started to develop ontologies: shared conceptualisations of real-world objects, phenomena and abstract concepts, expressed in machine-readable formats. Such ontologies can provide computers with the necessary basic knowledge, or axioms, to help them understand the definitions and relations between resources on the Web. Ontologies outline data concepts, each with its own unique identifier, definition and human-legible label.
Matching data to its underlying ontological model is called ontology population and involves data handling and parsing that gives it additional context and semantics (meaning). Over the past couple of years, Pensoft has been working on an ontology population tool, the Pensoft Annotator, which matches free text to ontological terms.
The Pensoft Annotator is a web application, which allows annotation of text input by the user, with any of the available ontologies. Currently, they are the Environment Ontology (ENVO) and the Relation Ontology (RO), but we plan to upload many more. The Annotator can be run with multiple ontologies, and will return a table of matched ontological term identifiers, their labels, as well as the ontology from which they originate (Fig. 1). The results can also be downloaded as a Tab-Separated Value (TSV) file and certain records can be removed from the table of results, if desired. In addition, the Pensoft Annotator allows to exclude certain words (“stopwords”) from the free text matching algorithm. There is a list of default stopwords, common for the English language, such as prepositions and pronouns, but anyone can add new stopwords.
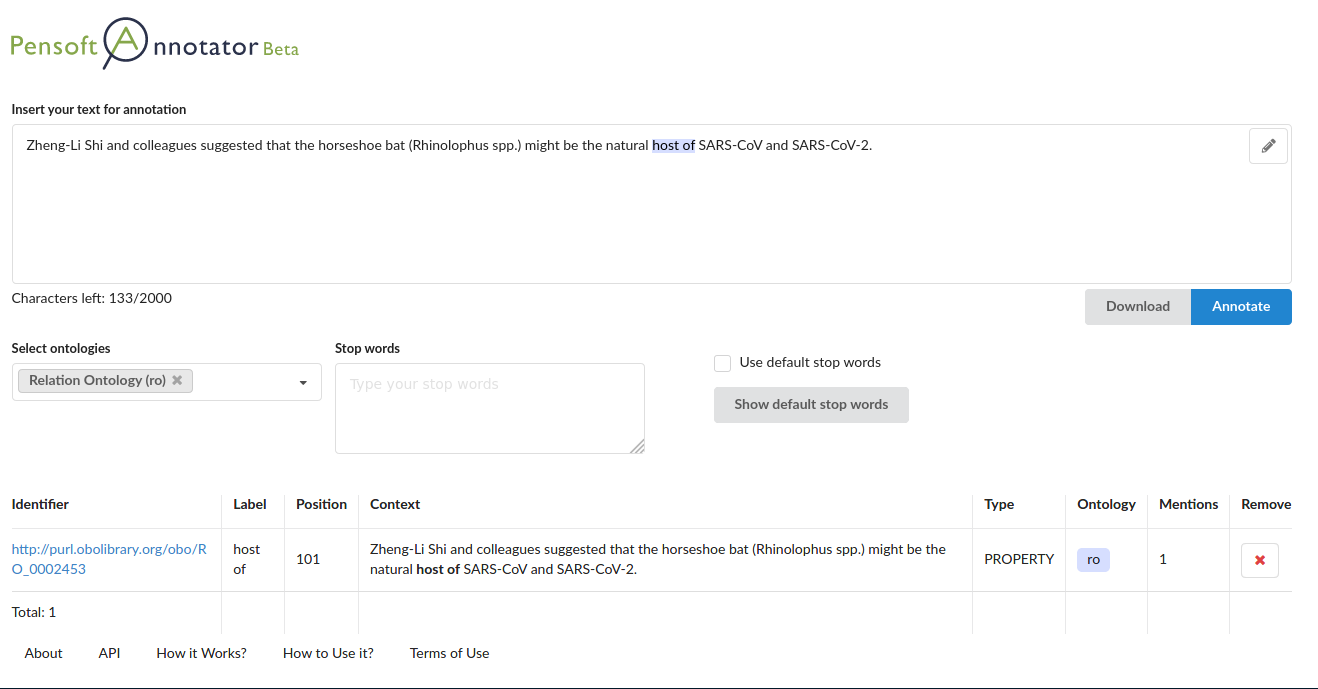
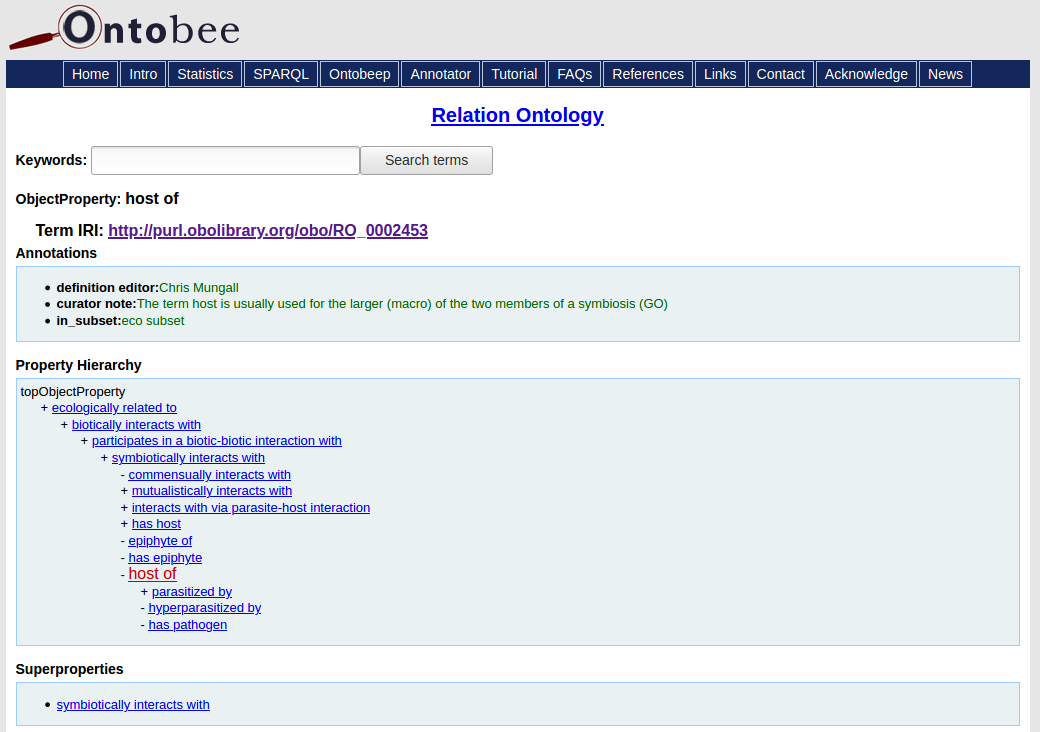
In Figure 1, we have annotated a sentence with the Pensoft Annotator, which yields a single matched term, labeled ‘host of’, from the Relation Ontology (RO). The ontology term identifier is linked to a webpage in Ontobee, which points to additional metadata about the ontology term (Fig. 2).
Such annotation requests can be run to perform text analyses for topic modelling to discover texts which contain host-pathogen interactions. Topic modelling is used to build algorithms for content recommendation (recommender systems) which can be implemented in online news platforms, streaming services, shopping websites and others.
At Pensoft, we use the Pensoft Annotator to enrich biodiversity publications with semantics. We are currently annotating taxonomic treatments with a custom-made ontology based on the Relation Ontology (RO) to discover treatments potentially describing species interactions. You can read more about using the Annotator to detect biotic interactions in this abstract.
The Pensoft Annotator can also be used programmatically through an API, allowing you to integrate the Annotator into your own script. For more information about using the Pensoft Annotator, please check out the documentation.