Within theBiodiversity Community Integrated Knowledge Library (BiCIKL) project, 14 European institutions from ten countries, spent the last three years elaborating on services and high-tech digital tools, in order to improve the findability, accessibility, interoperability and reusability (FAIR-ness) of various types of data about the world’s biodiversity. These types of data include peer-reviewed scientific literature, occurrence records, natural history collections, DNA data and more.
By ensuring all those data are readily available and efficiently interlinked to each other, the project consortium’s intention is to provide better tools to the scientific community, so that it can more rapidly and effectively study, assess, monitor and preserve Earth’s biological diversity in line with the objectives of the likes of the EU Biodiversity Strategy for 2030 and the European Green Deal. Their targets require openly available, precise and harmonised data to underpin the design of effective measures for restoration and conservation, reminds the BiCIKL consortium.
Since 2021, the project partners at BiCIKL have been working together to elaborate existing workflows and links, as well as create brand new ones, so that their data resources, platforms and tools can seamlessly communicate with each other, thereby taking the burden off the shoulders of scientists and letting them focus on their actual mission: paving the way to healthy and sustainable ecosystems across Europe and beyond.
Now that the three-year project is officially over, the wider scientific community is yet to reap the fruits of the consortium’s efforts. In fact, the end of the BiCIKL project marks the actual beginning of a European- and global-wide revolution in the way biodiversity scientists access, use and produce data. It is time for the research community, as well as all actors involved in the study of biodiversity and the implementation of regulations necessary to protect and preserve it, to embrace the lessons learned, adopt the good practices identified and build on the knowledge in existence.
This is why amongst the BiCIKL’s major final research outputs, there are two Policy Briefs meant to summarise and highlight important recommendations addressed to key policy makers, research institutions and funders of research. After all, it is the regulatory bodies that are best equipped to share and implement best practices and guidelines.
Most recently, the BiCIKL consortium published two particularly important policy briefs, both addressed to the likes of the European Commission’s Directorate-General for Environment; the European Environment Agency; the Joint Research Centre; as well as science and policy interface platforms, such as the EU Biodiversity Platform; and also organisations and programmes, e.g. Biodiversa+ and EuropaBON, which are engaged in biodiversity monitoring, protection and restoration. The policy briefs are also to be of particular use to national research funds in the European Union.
One of the newly published policy briefs, titled “Uniting FAIR data through interlinked, machine-actionable infrastructures”, highlights the potential benefits derived from enhanced connectivity and interoperability among various types of biodiversity data. The publication includes a list of recommendations addressed to policy-makers, as well as nine key action points. Understandably, amongst the main themes are those of wider international cooperation; inclusivity and collaboration at scale; standardisation and bringing science and policy closer to industry. Another major outcome of the BiCIKL project: the Biodiversity Knowledge Hub portal is noted as central to many of these objectives and tasks in its role of a knowledge broker that will continue to be maintained and updated with additional FAIR data-compliant services as a living legacy of the collaborative efforts at BiCIKL.
The second policy brief, titled “Liberate the power of biodiversity literature as FAIR digital objects”, shares key actions that can liberate data published in non-machine actionable formats and non-interoperable platforms, so that those data can also be efficiently accessed and used; as well as ways to publish future data according to the best FAIR and linked data practices. The recommendations highlighted in the policy brief intend to support decision-making in Europe; expedite research by making biodiversity data immediately and globally accessible; provide curated data ready to use by AI applications; and bridge gaps in the life cycle of research data through digital-born data. Several new and innovative workflows, linkages and integrative mechanisms and services developed within BiCIKL are mentioned as key advancements created to access and disseminate data available from scientific literature.
While all policy briefs and factsheets – both primarily targeted at non-expert decision-makers who play a central role in biodiversity research and conservation efforts – are openly and freely available on the project’s website, the most important contributions were published as permanent scientific records in a BiCIKL-branded dedicated collection in the peer-reviewed open-science journal Research Ideas and Outcomes (RIO). There, the policy briefs are provided as both a ready-to-print document (available as supplementary material) and an extensive academic publication.
Currently, the collection: “Towards interlinked FAIR biodiversity knowledge: The BiCIKL perspective” in the RIO journal contains 60 publications, including policy briefs, project reports, methods papers, conference abstracts, demonstrating and highlighting key milestones and project outcomes from along the BiCIKL’s journey in the last three years. The collection also features over 15 scientific publications authored by people not necessarily involved in BiCIKL, but whose research uses linked open data and tools created in BiCIKL. Their publications were published in a dedicated article collection in the Biodiversity Data Journal.
Leiden – also known as the ‘City of Keys’ and the ‘City of Discoveries’ – was aptly chosen to host the third Empowering Biodiversity Research (EBR III) conference. The two-day conference – this time focusing on the utilisation of biodiversity data as a vehicle for biodiversity research to reach to Policy – was held in a no less fitting locality: the Naturalis Biodiversity Center.
On 25th and 26th March 2024, the delegates got the chance to learn more about the latest discoveries, trends and innovations from scientists, as well as various stakeholders, including representatives of policy-making bodies, research institutions and infrastructures. The conference also ran a poster session and a Biodiversity Informatics market, where scientists, research teams, project consortia, and providers of biodiversity research-related services and tools could showcase their work and meet like-minded professionals.
BiCIKL stops at the Naturalis Biodiversity Center
The main outcome of the BiCIKL project: the Biodiversity Knowledge Hub, a one-stop knowledge portal to interlinked and machine-readable FAIR data.
The famous for its bicycle friendliness country also made a suitable stop for BiCIKL (an acronym for the Biodiversity Community Integrated Knowledge Library): a project funded under the European Commission’s Horizon 2020 programme that aimed at triggering a culture change in the way users access, (re)use, publish and share biodiversity data. To do this, the BiCIKL consortium set off on a 3-year journey to build on the existing biodiversity data infrastructures, workflows, standards and the linkages between them.
Many of the people who have been involved in the project over the last three years could be seen all around the beautiful venue. Above all, Naturalis is itself one of the partnering institutions at BiCIKL. Then, on Tuesday, on behalf of the BiCIKL consortium and the project’s coordinator: the scientific publisher and technology innovator: Pensoft, Iva Boyadzhieva presented the work done within the project one month ahead of its official conclusion at the end of April.
As she talked about the way the BiCIKL consortium took to traverse obstacles to wider use and adoption of FAIR and linked biodiversity data, she focused on BiCIKL’s main outcome: the Biodiversity Knowledge Hub (BKH).
Key results from the BiCIKL project three years into its existence presented by Pensoft’s Iva Boyadzhieva at the EBR III conference.
Intended to act as a knowledge broker for users who wish to navigate and access sources of open and FAIR biodiversity data, guidelines, tools and services, in practicality, the BKH is a one-stop portal for understanding the complex but increasingly interconnected landscape of biodiversity research infrastructures in Europe and beyond. It collates information, guidelines, recommendations and best practices in usage of FAIR and linked biodiversity data, as well as a continuously expanded catalogue of compliant relevant services and tools.
At the core of the BKH is the FAIR Data Place (FDP), where users can familiarise themselves with each of the participating biodiversity infrastructures and network organisations, and also learn about the specific services they provide. There, anyone can explore various biodiversity data tools and services by browsing by their main data type, e.g. specimens, sequences, taxon names, literature.
While the project might be coming to an end, she pointed out, the BKH is here to stay as a navigation system in a universe of interconnected biodiversity research infrastructures.
To do this, not only will the partners continue to maintain it, but it will also remain open to any research infrastructure that wishes to feature its own tools and services compliant with the linked and FAIR data requirements set by the BiCIKL consortium.
Indisputably, the ‘hot’ topics at the EBR III were the novel technologies for remote and non-invasive, yet efficient biomonitoring; the utilisation of data and other input sourced by citizen scientists; as well as leveraging different types and sources of biodiversity data, in order to better inform decision-makers, but also future-proof the scientific knowledge we have collected and generated to date.
Project’s coordinator Dr Quentin Groom presents the B-Cubed’s approach towards standardised access to biodiversity data for the use of policy-making at the EBR III conference.
Amongst the other Horizon Europe projects presented at the EBR III conference was B-Cubed (Biodiversity Building Blocks for policy). On Monday, the project’s coordinator Dr Quentin Groom (Meise Botanic Garden) familiarised the conference participants with the project, which aims to standardise access to biodiversity data, in order to empower policymakers to proactively address the impacts of biodiversity change.
You can find more about B-Cubed and Pensoft’s role in it in this blog post.
Dr France Gerard (UK Centre for Ecology & Hydrology) talks about the challenges in using raw data – including those provided by drones – to derive habitat condition metrics.
MAMBO: another Horizon Europe project where Pensoft has been contributing with expertise in science communication, dissemination and exploitation, was also an active participant at the event. An acronym for Modern Approaches to the Monitoring of BiOdiversity, MAMBO had its own session on Tuesday morning, where Dr Vincent Kalkman (Naturalis Biodiversity Center), Dr France Gerard (UK Centre for Ecology & Hydrology) and Prof. Toke Høye (Aarhus University) each took to the stage to demonstrate how modern technology developed within the project is to improve biodiversity and habitat monitoring. Learn more about MAMBO and Pensoft’s involvement in this blog post.
MAMBO’s project coordinator Prof. Toke T. Høye talked about smarter technologies for biodiversity monitoring, including camera traps able to count insects at a particular site.
On the event’s website you can access the MAMBO’s slides presentations by Kalkman, GerardandHøye, as presented at the EBR III conference.
***
The EBR III conference also saw a presentation – albeit remote – from Prof. Dr. Florian Leese (Dean at the University of Duisburg-Essen, Germany, and Editor-in-Chief at the Metabarcoding and Metagenomics journal), where he talked about the promise, but also the challenges for DNA-based methods to empower biodiversity monitoring.
Amongst the key tasks here, he pointed out, are the alignment of DNA-based methods with the Global Biodiversity Framework; central push and funding for standards and guidance; publication of data in portals that adhere to the best data practices and rules; and the mobilisation of existing resources such as the meteorological ones.
He also made a reference to the Forum Paper “Introducing guidelines for publishing DNA-derived occurrence data through biodiversity data platforms” by R. Henrik Nilsson et al., where the international team provided a brief rationale and an overview of guidelines targeting the principles and approaches of exposing DNA-derived occurrence data in the context of broader biodiversity data. In the study, published in the Metabarcoding and Metagenomics journal in 2022, they also introduced a living version of these guidelines, which continues to encourage feedback and interaction as new techniques and best practices emerge.
***
You can find the programme on the conference website and see highlights on the conference hashtag: #EBR2024.
To bridge the gap between authors and their readers or fellow researchers – whether humans or computers – Knowledge Pixels and Pensoft launched workflows to link scientific publications to nanopublications.
A new pilot project by Pensoft and Knowledge Pixels breaks scientific knowledge into FAIR and interlinked snippets of precise information
As you might have already heard, Knowledge Pixels: an innovative startup tech company aiming to revolutionise scientific publishing and knowledge sharing by means of nanopublications – recently launched a pilot project with the similarly pioneering open-science journal Research Ideas and Outcomes (RIO), in a first of several upcoming collaborations between the software developer and the open-access scholarly publisher Pensoft.
“The way how science is performed has dramatically changed with digitalisation, the Internet, and the vast increase in data, but the results are still shared in basically the same form and language as 300 years ago: in narrative text, like a story. These narratives are not precise and not directly interpretable by machines, thereby not FAIR. Even the latest impressive AI tools like ChatGPT can only guess (and sometimes ‘hallucinate’) what the authors meant exactly and how the results compare,”
said Philipp von Essen and Tobias Kuhn, the two founders of Knowledge Pixels in a press announcement.
So, in order to bridge the gap between authors and their readers and fellow researchers – whether humans or computers – the partners launched several workflows to bi-directionally link scientific publications from RIO Journal to nanopublications. We will explain and demonstrate these workflows in a bit.
Now, first, let’s see what nanopublications are and how they contribute to scientific knowledge, researchers and scholarship as a whole.
Basically, a nanopublication – unlike a research article – is just a tiny snippet of a scientific finding (e.g. medication X treats disease Y), which exists as a complete and straightforward piece of information stored on a decentralised server network in a specially structured format, so that it is readable for humans, but also “understandable” and actionable for computers and their algorithms.
A nanopublication may also be an assertion related to an existing research article meant to support, comment, update or complement the reported findings.
In fact, nanopublications as a concept have been with us for quite a while now. Ever since the rise of the Semantic Web, to be exact. At the end of the day, it all boils down to providing easily accessible information that is only a click away from additional useful and relevant content. The thing is, technological advancement has only recently begun to catch up with the concept of nanopublications. Today, we are one step closer to another revolution in scientific publishing, thanks to the emergence and increasing adoption of what we call knowledge graphs.
Second time I hear about nanopublications in biodiversity in 3 days -1st by @rdmpage + now by @Pensoft#ECN2016
“As pioneers in the semantic open access scientific publishing field for over a decade now, at Pensoft we are deeply engaged with making research work actually available at anyone’s fingertips. What once started as breaking down paywalls to research articles and adding the right hyperlinks in the right places, is time to be built upon,”
said Prof. Lyubomir Penev, founder and CEO at Pensoft: the open-access scholarly publisher behind the very first semantically enhanced research article in the biodiversity domain, published back in 2010 in the ZooKeys journal.
Why nanopublications?
Apart from enabling computer algorithms with wholesome access to published research findings, nanopublications allow for the knowledge snippets that they are intended to communicate to be fully understandable and actionable. With nanopublications, each byte of knowledge is interconnected and traceable back to its author(s) and scientific evidence.
Nanopublications present a complete and straightforward piece of information stored on a decentralised server network in a specially structured format, so that it is readable for humans, but also “understandable” and actionable for computers and their algorithms. Illustration by Knowledge Pixels.
By granting computers the capability of exchanging information between users and platforms, these data become Interoperable (as in the Iin FAIR), so that they can be delivered to the right user, at the right time, in the right place.
Another issue nanopublications are designed to address is research scrutiny. Today, scientific publications are produced at an unprecedented rate that is unlikely to cease in the years to come, as scholarship embraces the dissemination of early research outputs, including preprints, accepted manuscripts and non-conventional papers.
By linking assertions to a publication by means of nanopublications allows the original authors and their fellow researchers to keep knowledge up to date as new findings emerge either in support or contradiction to previous information.
A network of interlinked nanopublications could also provide a valuable forum for scientists to test, compare, complement and build on each other’s results and approaches to a common scientific problem, while retaining the record of their cooperation each step along the way.
A scientific issue that would definitely benefit from an additional layer of provenance and, specifically, a workflow allowing for new updates to be linked to previous publications is the biodiversity domain, where species treatments, taxon names, biotic interactions and phylogenies are continuously being updated, reworked and even discarded for good. This is why an upcoming collaboration between Pensoft and Knowledge Pixels will also involve the Biodiversity Data Journal (stay tuned!)
What can you do in RIO?
Now, let’s have a look at the *nano*opportunities already available at RIO Journal.
The integration between RIO and Nanodash: the environment developed by Knowledge Pixels where users edit and publish their nanopublications is available at any article published in the journal.
Add reaction to article
This function allows any reader to evaluate and record an opinion about any article using a simple template. The opinion is posted as a nanopublication displayed on the article page, bearing the timestamp and the name of the creator.
All one needs to do is go to a paper, locate the Nanopubs tab in the menu on the left and click on the Add reaction command to navigate to the Nanodash workspace accessible to anyone registered on ORCiD.
To access the Nanodash workspace, where you can fill in a ready-to-use, partially filled in nanopublication template, simply go to the Nanopubs tab in the menu of any article published in RIO Journal and click Add reaction to this article (see example).
Within the simple Nanodash workspace, the user can provide the text of the nanopublication; define its relation to the linked paper using the Citation Typing Ontology (CiTO); update its provenance and add information (e.g. licence, extra creators) by inserting extra elements.
To do this, the Knowledge Pixels team has created a ready-to-use nanopublication template, where the necessary details for the RIO paper and the author that secure the linkage have already been pre-filled.
Post an inline comment as a nanopublication
Another opportunity for readers and authors to add further meaningful information or feedback to an already published paper is by attaching an inline comment and then exporting it to Nanodash, so that it becomes a nanopublication. To do this, users will simply need to select some text with a left click, type in the comment, and click OK. Now, their input will be available in the Comment tab designed to host simple comments addressing the authors of the publication.
While RIO has long been supporting features allowing for readers to publicly share comments and even CrossRef-registered post-publication peer reviews along the articles, the nanopublications integration adds to the versatile open science-driven arsenal of feedback tools. More precisely, the novel workflow is especially useful for comments that provide a particularly valuable contribution to a research topic.
To make a comment into a nanopublication the user needs to locate the comment in the tab, and click on the Post as Nanopub command to access the Nanodash environment.
Add a nanopublication while writing your manuscript
A functionality available from ARPHA Writing Tool – the online collaborative authoring environment that underpins the manuscript submission process at several journals published by Pensoft, including RIO Journal – allows for researchers to create a list of nanopublications within their manuscripts.
By doing so, not only do authors get to highlight their key statements in a tabular view within a separate pre-designated Nanopublications section, but they also make it easier for reviewers and scientific editors to focus on and evaluate the very foundations of the paper.
By incorporating a machine algorithm-friendly structure for the main findings of their research paper, authors ensure that AI assistants, for example, will be more likely to correctly ‘read’, ‘interpret’ and deliver the knowledge reported in the publication for the next users and their prompts. Furthermore, fellow researchers who might want to cite the paper will also have an easier time citing the specific statement from within the cited source, so that their own readers – be it human, or AI – will make the right links and conclusions.
Within a pre-designated article template at RIO – regardless of the paper type selected – authors have the option to either paste a link to an already available nanopublication or manage their nanopublication via the Nanodash environment by following a link. Customised for the purposes of RIO, the Nanodash workspace will provide them with all the information needed to guide them through the creation and publication of their nanopublications.
Why Research Ideas and Outcomes, a.k.a. RIO Journal?
Why did Knowledge Pixels and Pensoft opt to run their joint pilot at no other journal within the Pensoft portfolio of open-access scientific journals but the Research Ideas and Outcomes (RIO)?
Well, one may argue that there simply was no better choice than an academic outlet that was initially designed to serve as “the open-science journal”: something it has been honourably recognised for by SPARC in 2016, only one year since its launch.
Innovative since day #1, back in 2015, RIO surfaced as an academic outlet to publish a whole lot of article types, reporting on scientific work from across the research process, starting from research ideas, grant proposals and workshop reports.
After all, back in 2015, when it was only a handful of funders who required Data and Software Management Plans to be made openly and publicly, RIO was already providing a platform to publish those as easily citable research outputs, complete with DOI and registration on Crossref. In the spirit of transparency, RIO has always operated an open and public by default peer review policy.
More recently, RIO introduced a novel collections workflow which allows, for example, project coordinators, to provide a one-stop access point for publications and all kinds of valuable outputs resulting from their projects regardless of their publication source.
Bottom line is, RIO has always stood for innovation, transparency, openness and FAIRness in scholarly publishing and communication, so it was indeed the best fit for the nanopublication pilot with Knowledge Pixels.
***
We encourage you to try the nanopublications workflow yourself by going to https://riojournal.com/articles, and posting your own assertion to an article of your choice!
Don’t forget to also sign up for the RIO Journal’s newsletter via the Email alert form on the journal’s website and follow it on Twitter, Facebook, Linkedin and Mastodon.
OpenBiodiv is a biodiversity database containing knowledge extracted from scientific literature, built as an Open Biodiversity Knowledge Management System.
Apart from coordinating the Horizon 2020-funded project BiCIKL, scholarly publisher and technology provider Pensoft has been the engine behind what is likely to be the first production-stage semantic system to run on top of a reasonably-sized biodiversity knowledge graph.
OpenBiodiv is a biodiversity database containing knowledge extracted from scientific literature, built as an Open Biodiversity Knowledge Management System.
As of February 2023, OpenBiodiv contains 36,308 processed articles; 69,596 taxon treatments; 1,131 institutions; 460,475 taxon names; 87,876 sequences; 247,023 bibliographic references; 341,594 author names; and 2,770,357 article sections and subsections.
In fact, OpenBiodiv is a whole ecosystem comprising tools and services that enable biodiversity data to be extracted from the text of biodiversity articles published in data-minable XML format, as in the journals published by Pensoft (e.g. ZooKeys, PhytoKeys, MycoKeys, Biodiversity Data Journal), and other taxonomic treatments – available from Plazi and Plazi’s specialised extraction workflow – into Linked Open Data.
“I believe that OpenBiodiv is a good real-life example of how the outputs and efforts of a research project may and should outlive the duration of the project itself. Something that is – of course – central to our mission at BiCIKL.”
explains Prof Lyubomir Penev, BiCIKL’s Project Coordinator and founder and CEO of Pensoft.
“The basics of what was to become the OpenBiodiv database began to come together back in 2015 within the EU-funded BIG4 PhD project of Victor Senderov, later succeeded by another PhD project by Mariya Dimitrova within IGNITE. It was during those two projects that the backend Ontology-O, the first versions of RDF converters and the basic website functionalities were created,”
he adds.
At the time OpenBiodiv became one of the nine research infrastructures within BiCIKL tasked with the provision of virtual access to open FAIR data, tools and services, it had already evolved into a RDF-based biodiversity knowledge graph, equipped with a fully automated extraction and indexing workflow and user apps.
Currently, Pensoft is working at full speed on new user apps in OpenBiodiv, as the team is continuously bringing into play invaluable feedback and recommendation from end-users and partners at BiCIKL.
As a result, OpenBiodiv is already capable of answering open-ended queries based on the available data. To do this, OpenBiodiv discovers ‘hidden’ links between data classes, i.e. taxon names, taxon treatments, specimens, sequences, persons/authors and collections/institutions.
Thus, the system generates new knowledge about taxa, scientific articles and their subsections, the examined materials and their metadata, localities and sequences, amongst others. Additionally, it is able to return information with a relevant visual representation about any one or a combination of those major data classes within a certain scope and semantic context.
Users can explore the database by either typing in any term (even if misspelt!) in the search engine available from the OpenBiodiv homepage; or integrating an Application Programming Interface (API); as well as by using SPARQL queries.
On the OpenBiodiv website, there is also a list of predefined SPARQL queries, which is continuously being expanded.
“OpenBiodiv is an ambitious project of ours, and it’s surely one close to Pensoft’s heart, given our decades-long dedication to biodiversity science and knowledge sharing. Our previous fruitful partnerships with Plazi, BIG4 and IGNITE, as well as the current exciting and inspirational network of BiCIKL are wonderful examples of how far we can go with the right collaborators,”
For the 37th time, experts from across the world to share and discuss the latest developments surrounding biodiversity data and how they are being gathered, used, shared and integrated across time, space and disciplines.
Between 17th and 21st October, about 400 scientists and experts took part in a hybrid meeting dedicated to the development, use and maintenance of biodiversity data, technologies, and standards across the world.
For the 37th time, the global scientific and educational association Biodiversity Information Standards (TDWG) brought together experts from all over the globe to share and discuss the latest developments surrounding biodiversity data and how they are being gathered, used, shared and integrated across time, space and disciplines.
This was the first time the event happened in a hybrid format. It was attended by 160 people on-site, while another 235 people joined online.
The TDWG 2022 conference saw plenty of networking and engaging discussions with as many as 160 on-site attendees and another 235 people, who joined the event remotely.
“It’s wonderful to be in the Balkans and Bulgaria for our Biodiversity Information and Standards (TDWG) 2022 conference! Everyone’s been so welcoming and thoughtfully engaged in conversations about biodiversity information and how we can all collaborate, contribute and benefit,”
“Our TDWG mission is to create, maintain and promote the use of open, community-driven standards to enable sharing and use of biodiversity data for all,”
she added.
Prof Lyubomir Penev (Pensoft) and Deborah Paul (TDWG) at TDWG 2022.
“We are proud to have been selected to be the hosts of this year’s TDWG annual conference and are definitely happy to have joined and observed so many active experts network and share their know-how and future plans with each other, so that they can collaborate and make further progress in the way scientists and informaticians work with biodiversity information,”
said Pensoft’s founder and CEO Prof. Lyubomir Penev.
“As a publisher of multiple globally renowned scientific journals and books in the field of biodiversity and ecology, at Pensoft we assume it to be our responsibility to be amongst the first to implement those standards and good practices, and serve as an example in the scholarly publishing world. Let me remind you that it is the scientific publications that present the most reliable knowledge the world and science has, due to the scrutiny and rigour in the review process they undergo before seeing the light of day,”
he added.
***
In a nutshell, the main task and dedication of the TDWG association is to develop and maintain standards and data-sharing protocols that support the infrastructures (e.g., The Global Biodiversity Information Facility – GBIF), which aggregate and facilitate use of these data, in order to inform and expand humanity’s knowledge about life on Earth.
It is the goal of everyone at TDWG to let scientists interested in the world’s biodiversity to do their work efficiently and in a manner that can be understood, shared and reused.
It is the goal of everyone volunteering their time and expertise to TDWG to enable the scientists interested in the world’s biodiversity to do their work efficiently and in a manner that can be understood, shared and reused by others. After all, biodiversity data underlie everything we know about the natural world.
If there are optimised and universal standards in the way researchers store and disseminate biodiversity data, all those biodiversity scientists will be able to find, access and use the knowledge in their own work much more easily. As a result, they will be much better positioned to contribute new knowledge that will later be used in nature and ecosystem conservation by key decision-makers.
On Monday, the event opened with welcoming speeches by Deborah Paul and Prof. Lyubomir Penev in their roles of the Chair of TDWG and the main host of this year’s conference, respectively.
The opening ceremony continued with a keynote speech by Prof. Pavel Stoev, Director of the Natural History Museum of Sofia and co-host of TDWG 2022.
Prof. Pavel Stoev (Natural History Museum of Sofia) with a presentation about the known and unknown biodiversity of Bulgaria during the opening plenary session of TDWG 2022.
He walked the participants through the fascinating biodiversity of Bulgaria, but also the worrying trends in the country associated with declining taxonomic expertise.
He finished his talk with a beam of hope by sharing about the recently established national unit of DiSSCo, whose aim – even if a tad too optimistic – is to digitise one million natural history items in four years, of which 250,000 with photographs. So far, one year into the project, the Bulgarian team has managed to digitise more than 32,000 specimens and provide images to 10,000 specimens.
The plenary session concluded with a keynote presentation by renowned ichthyologist and biodiversity data manager Dr. Richard L. Pyle, who is also a manager of ZooBank – the key international database for newly described species.
Keynote presentation by Dr Richard L. Pyle (Bishop Museum, USA) at the opening plenary session of TDWG 2022.
In his talk, he highlighted the gaps in the ways taxonomy is being used, thereby impeding biodiversity research and cutting off a lot of opportunities for timely scientific progress.
“There are simple things we can do to change how we use taxonomy as a tool that would dramatically improve our ability to conduct science and understand biodiversity. There is enormous value and utility within existing databases around the world to understand biodiversity, how threatened it is, what impacts human activity has (especially climate change), and how to optimise the protection and preservation of biodiversity,”
he said in an interview for a joint interview by the Bulgarian News Agency and Pensoft.
“But we do not have easy access to much of this information because the different databases are not well integrated. Taxonomy offers us the best opportunity to connect this information together, to answer important questions about biodiversity that we have never been able to answer before. The reason meetings like this are so important is that they bring people together to discuss ways of using modern informatics to greatly increase the power of the data we already have, and prioritise how we fill the gaps in data that exist. Taxonomy, and especially taxonomic data integration, is a very important part of the solution.”
Pyle also commented on the work in progress at ZooBank ten years into the platform’s existence and its role in the next (fifth) edition of the International Code of Zoological Nomenclature, which is currently being developed by the International Commission of Zoological Nomenclature (ICZN).
“We already know that ZooBank will play a more important role in the next edition of the Code than it has for these past ten years, so this is exactly the right time to be planning new services for ZooBank. Improvements at ZooBank will include things like better user-interfaces on the web to make it easier and faster to use ZooBank, better data services to make it easier for publishers to add content to ZooBank as part of their publication workflow, additional information about nomenclature and taxonomy that will both support the next edition of the Code, and also help taxonomists get their jobs done more efficiently and effectively. Conferences like the TDWG one are critical for helping to define what the next version of ZooBank will look like, and what it will do.”
***
During the week, the conference participants had the opportunity to enjoy a total of 140 presentations; as well as multiple social activities, including a field trip to Rila Monastery and a traditional Bulgarian dinner.
TDWG 2022 conference participants document their species observations on their way to Rila Monastery.
While going about the conference venue and field trip localities, the attendees were also actively uploading their species observations made during their stay in Bulgaria on iNaturalist in a TDWG2022-dedicated BioBlitz. The challenge concluded with a total of 635 observations and 228 successfully identified species.
Amongst the social activities going on during TDWG 2022 was a BioBlitz, where the conference participants could uploade their observations made in Bulgaria on iNaturalist and help each other successfully identify the specimens.
“Biodiversity provides the support systems for all life on Earth. Yet the natural world is in peril, and we face biodiversity and climate emergencies. The consequences of these include accelerating extinction, increased risk from zoonotic disease, degradation of natural capital, loss of sustainable livelihoods in many of the poorest yet most biodiverse countries of the world, challenges with food security, water scarcity and natural disasters, and the associated challenges of mass migration and social conflicts.
Solutions to these problems can be found in the data associated with natural science collections. DiSSCo is a partnership of the institutions that digitise their collections to harness their potential. By bringing them together in a distributed, interoperable research infrastructure, we are making them physically and digitally open, accessible, and usable for all forms of research and innovation.
At present rates, digitising all of the UK collection – which holds more than 130 million specimens collected from across the globe and is being taken care of by over 90 institutions – is likely to take many decades, but new technologies like machine learning and computer vision are dramatically reducing the time it will take, and we are presently exploring how robotics can be applied to accelerate our work.”
In his turn, Dr Donat Agosti, CEO and Managing director at Plazi – a not-for-profit organisation supporting and promoting the development of persistent and openly accessible digital taxonomic literature – said:
“All the data about biodiversity is in our libraries, that include over 500 million pages, and everyday new publications are being added. No person can read all this, but machines allow us to mine this huge, very rich source of data. We do not know how many species we know, because we cannot analyse with all the scientists in this library, nor can we follow new publications. Thus, we do not have the best possible information to explore and protect our biological environment.”
Dr Donat Agosti demonstrating the importance of publishing biodiversity data in a structured and semantically enhanced format in one of his presentations at TDWG 2022.
***
At the closing plenary session, Gail Kampmeier – TDWG Executive member and one of the first zoologists to join TDWG in 1996 – joined via Zoom to walk the conference attendees through the 37-year history of the association, originally named the Taxonomic Databases Working Group, but later transformed to Biodiversity Information Standards, as it expanded its activities to the whole range of biodiversity data.
“While this presentation is about TDWG’s history as an organisation, its focus will be on the heart of TDWG: its people. We would like to show how the organisation has evolved in terms of gender balance, inclusivity actions, and our engagement to promote and enhance diversity at all levels. But more importantly, where do we—as a community—want to go in the future?”,
Then, in the final talk of the session, Deborah Paul took to the stage to present the progress and key achievements by the association from 2022.
🤩Year in review by @idbdeb at #TDWG2022: many wonderful achievements & even more in the works!🙌 E.g.✅Memorandum of Understanding with Genomic Standards Consortium ✅new Mineralogy Task Group ✅new vision & mission statement ✅collaboration with @GBIF on the new data model.. 1/ pic.twitter.com/RZx8hlePOm
Deborah Paul reminds that – apart from the conference abstracts – the TDWG journal: Biodiversity Information Science and Standards (BISS) also welcomes full-lenght articles that demonstrate the development or application of new methods and approaches in biodiversity informatics.
Launched in 2017 on the Pensoft’s publishing platform ARPHA, the journal provides the quite unique and innovative opportunity to have both abstracts and full-length research papers published in a modern, technologically-advanced scholarly journal. In her speech, Deborah Paul reminded that BISS journal welcomes research articles that demonstrate the development or application of new methods and approaches in biodiversity informatics in the form of case studies.
Amongst the achievements of TDWG and its community, a special place was reserved for the Horizon 2020-funded BiCIKL project (abbreviation for Biodiversity Community Integrated Knowledge Library), involving many of the association’s members.
Having started in 2021, the 3-year project, coordinated by Pensoft, brings together 14 partnering institutions from 10 countries, and 15 biodiversity under the common goal to create a centralised place to connect all key biodiversity data by interlinking a total of 15 research infrastructures and their databases.
Deborah Paul also reported on the progress of the Horizon 2020-funded project BiCIKL, which involves many of the TDWG members. BiCIKL’s goal is to create a centralised place to connect all key biodiversity data by interlinking 15 key research infrastructures and their databases.
In fact, following the week-long TDWG 2022 conference in Sofia, a good many of the participants set off straight for another Bulgarian city and another event hosted by Pensoft. The Second General Assembly of BiCIKL took place between 22nd and 24th October in Plovdiv.
***
You can also explore highlights and live tweets from TDWG 2022 on Twitter via #TDWG2022.
The Pensoft team at TDWG 2022 were happy to become the hosts of the 37th TDWG conference.
Between now and 15 September 2021, the article processing fee (normally €550) will be waived for the first 36 papers, provided that the publications are accepted and meet the following criteria that the data paper describes a dataset:
The manuscript must be prepared in English and is submitted in accordance with BDJ’s instructions to authors by 15 September 2021. Late submissions will not be eligible for APC waivers.
Sponsorship is limited to the first 36 accepted submissions meeting these criteria on a first-come, first-served basis. The call for submissions can therefore close prior to the stated deadline of 15 September 2021. Authors may contribute to more than one manuscript, but artificial division of the logically uniform data and data stories, or “salami publishing”, is not allowed.
BDJ will publish a special issue including the selected papers by the end of 2021. The journal is indexed by Web of Science (Impact Factor 1.331), Scopus (CiteScore: 2.1) and listed in РИНЦ / eLibrary.ru.
For non-native speakers, please ensure that your English is checked either by native speakers or by professional English-language editors prior to submission. You may credit these individuals as a “Contributor” through the AWT interface. Contributors are not listed as co-authors but can help you improve your manuscripts.
In addition to the BDJ instruction to authors, it is required that datasets referenced from the data paper a) cite the dataset’s DOI, b) appear in the paper’s list of references, and c) has “Russia 2021” in Project Data: Title and “N-Eurasia-Russia2021“ in Project Data: Identifier in the dataset’s metadata.
Questions may be directed either to Dmitry Schigel, GBIF scientific officer, or Yasen Mutafchiev, managing editor of Biodiversity Data Journal.
The 2021 extension of the collection of data papers will be edited by Vladimir Blagoderov, Pedro Cardoso, Ivan Chadin, Nina Filippova, Alexander Sennikov, Alexey Seregin, and Dmitry Schigel.
Datasets with more than 5,000 records that are new to GBIF.org
Datasets should contain at a minimum 5,000 new records that are new to GBIF.org. While the focus is on additional records for the region, records already published in GBIF may meet the criteria of ‘new’ if they are substantially improved, particularly through the addition of georeferenced locations.” Artificial reduction of records from otherwise uniform datasets to the necessary minimum (“salami publishing”) is discouraged and may result in rejection of the manuscript. New submissions describing updates of datasets, already presented in earlier published data papers will not be sponsored.
Justification for publishing datasets with fewer records (e.g. sampling-event datasets, sequence-based data, checklists with endemics etc.) will be considered on a case-by-case basis.
Datasets with high-quality data and metadata
Authors should start by publishing a dataset comprised of data and metadata that meets GBIF’s stated data quality requirement. This effort will involve work on an installation of the GBIF Integrated Publishing Toolkit.
Only when the dataset is prepared should authors then turn to working on the manuscript text. The extended metadata you enter in the IPT while describing your dataset can be converted into manuscript with a single-click of a button in the ARPHA Writing Tool (see also Creation and Publication of Data Papers from Ecological Metadata Language (EML) Metadata. Authors can then complete, edit and submit manuscripts to BDJ for review.
Datasets with geographic coverage in Russia
In correspondence with the funding priorities of this programme, at least 80% of the records in a dataset should have coordinates that fall within the priority area of Russia. However, authors of the paper may be affiliated with institutions anywhere in the world.
***
Check out the Biota of Russia dynamic data paper collection so far.
Follow Biodiversity Data Journal on Twitter and Facebook to keep yourself posted about the new research published.
By Mariya Dimitrova, Georgi Zhelezov, Teodor Georgiev and Lyubomir Penev
The use of written language to record new knowledge is one of the advancements of civilisation that has helped us achieve progress. However, in the era of Big Data, the amount of published writing greatly exceeds the physical ability of humans to read and understand all written information.
More than ever, we need computers to help us process and manage written knowledge. Unlike humans, computers are “naturally fluent” in many languages, such as the formats of the Semantic Web. These standards were developed by the World Wide Web Consortium (W3C) to enable computers to understand data published on the Internet. As a result, computers can index web content and gather data and metadata about web resources.
To help manage knowledge in different domains, humans have started to develop ontologies: shared conceptualisations of real-world objects, phenomena and abstract concepts, expressed in machine-readable formats. Such ontologies can provide computers with the necessary basic knowledge, or axioms, to help them understand the definitions and relations between resources on the Web. Ontologies outline data concepts, each with its own unique identifier, definition and human-legible label.
Matching data to its underlying ontological model is called ontology population and involves data handling and parsing that gives it additional context and semantics (meaning). Over the past couple of years, Pensoft has been working on an ontology population tool, the Pensoft Annotator, which matches free text to ontological terms.
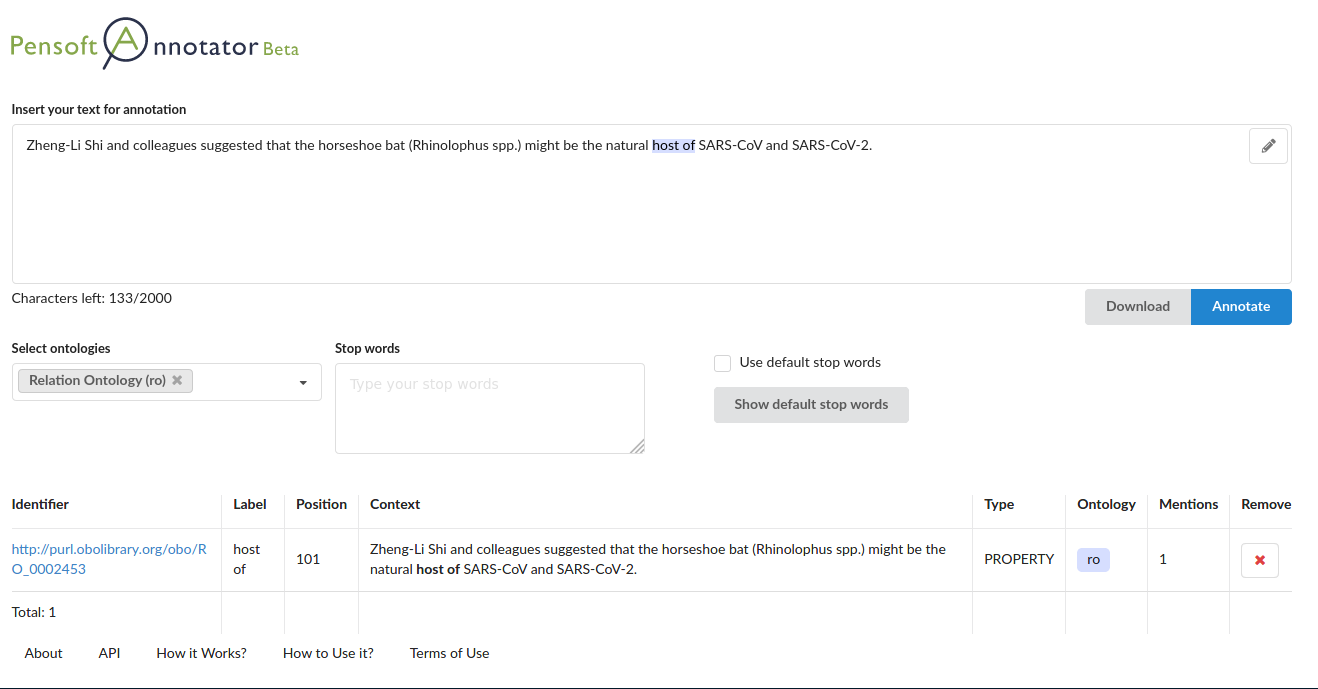
The Pensoft Annotator is a web application, which allows annotation of text input by the user, with any of the available ontologies. Currently, they are the Environment Ontology (ENVO) and the Relation Ontology (RO), but we plan to upload many more. The Annotator can be run with multiple ontologies, and will return a table of matched ontological term identifiers, their labels, as well as the ontology from which they originate (Fig. 1). The results can also be downloaded as a Tab-Separated Value (TSV) file and certain records can be removed from the table of results, if desired. In addition, the Pensoft Annotator allows to exclude certain words (“stopwords”) from the free text matching algorithm. There is a list of default stopwords, common for the English language, such as prepositions and pronouns, but anyone can add new stopwords.
Figure 1. Interface of the Pensoft Annotator application
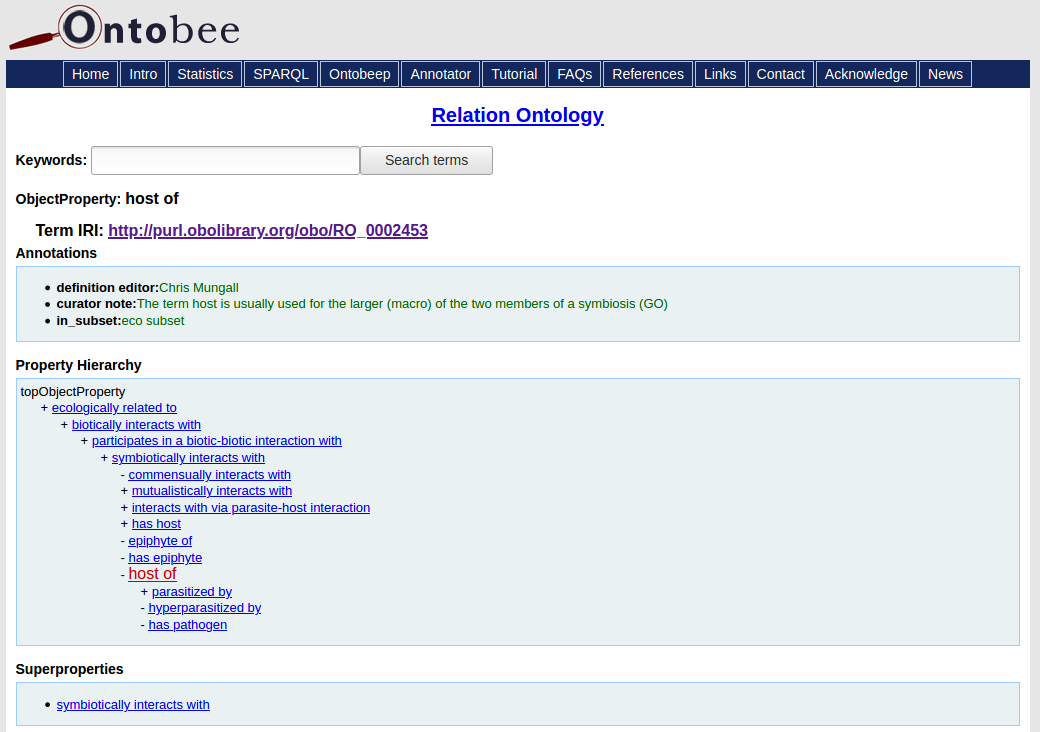
In Figure 1, we have annotated a sentence with the Pensoft Annotator, which yields a single matched term, labeled ‘host of’, from the Relation Ontology (RO). The ontology term identifier is linked to a webpage in Ontobee, which points to additional metadata about the ontology term (Fig. 2).
Figure 2. Web page about ontology term
Such annotation requests can be run to perform text analyses for topic modelling to discover texts which contain host-pathogen interactions. Topic modelling is used to build algorithms for content recommendation (recommender systems) which can be implemented in online news platforms, streaming services, shopping websites and others.
At Pensoft, we use the Pensoft Annotator to enrich biodiversity publications with semantics. We are currently annotating taxonomic treatments with a custom-made ontology based on the Relation Ontology (RO) to discover treatments potentially describing species interactions. You can read more about using the Annotator to detect biotic interactions in this abstract.
The Pensoft Annotator can also be used programmatically through an API, allowing you to integrate the Annotator into your own script. For more information about using the Pensoft Annotator, please check out the documentation.
by Mariya Dimitrova, Jorrit Poelen, Georgi Zhelezov, Teodor Georgiev, Lyubomir Penev
Fig. 1. Pensoft-GloBI workflow for indexing biotic interactions from scholarly literature
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species, etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 2 in Fig. 1).. We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as json to a GitHub repository, from where they could be accessed by GloBI.
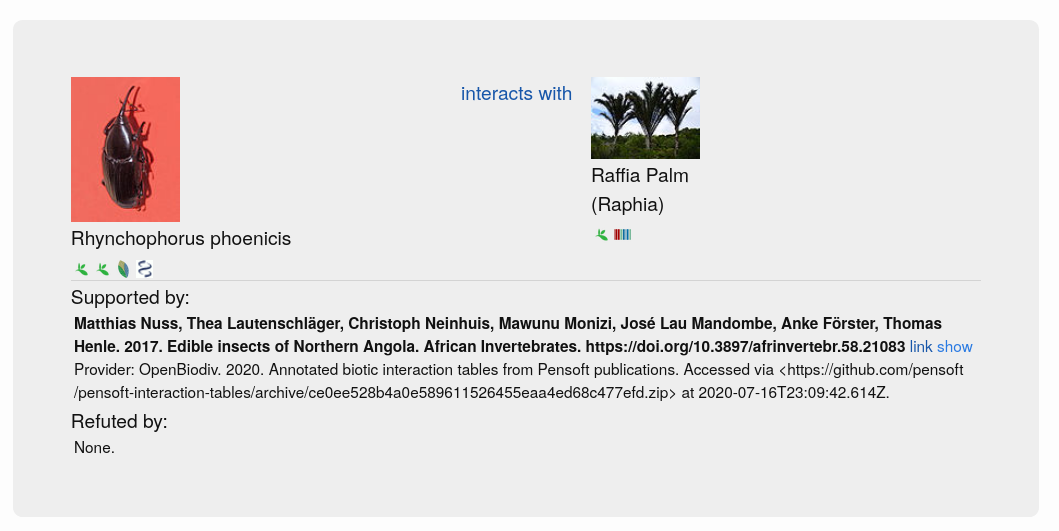
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ (Fig. 2) because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
Fig. 2. Example of a biotic interaction indexed by GloBI.
Examples of species interactions provided by OpenBiodiv and indexed by GloBI are available on GloBI’s website.
In the future we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6,993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 1 in Fig. 1). We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as JSON to a GitHub repository, from where they could be accessed by GloBI.
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
In the future, we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
References
Jorrit H. Poelen, James D. Simons and Chris J. Mungall. (2014). Global Biotic Interactions: An open infrastructure to share and analyze species-interaction datasets. Ecological Informatics. https://doi.org/10.1016/j.ecoinf.2014.08.005.
Additional Information
The work has been partially supported by the International Training Network (ITN) IGNITE funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 764840.
Pensoft creates a specialised data paper article type for the omics community within Biodiversity Data Journal to reflect the specific nature of omics data. The scholarly publisher and technology provider established a manuscript template to help standardise the description of such datasets and their most important features.
By Mariya Dimitrova, Raïssa Meyer, Pier Luigi Buttigieg, Lyubomir Penev
Data papers are scientific papers which describe a dataset rather than present and discuss research results. The concept was introduced to the biodiversity community by Chavan and Penev in 2011 as the result of a joint project of GBIF and Pensoft.
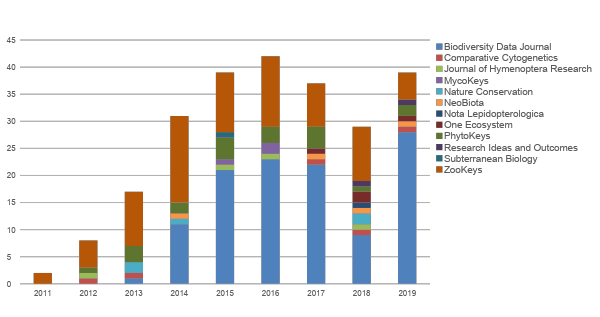
Since then, Pensoft has implemented the data paper in several of its journals (Fig. 1). The recognition gained through data papers is an important incentive for researchers and data managers to author better quality metadata and to make it Findable, Accessible, Interoperable and Re-usable (FAIR). High quality and FAIRness of (meta)data are promoted through providing peer review, data audit, permanent scientific record and citation credit as for any other scholarly publication. One can read more on the different types of data papers and how they help to achieve these goals in the Strategies and guidelines for scholarly publishing of biodiversity data (https://doi.org/10.3897/rio.3.e12431).
Fig. 1 Number of data papers published in Pensoft’s journals since 2011.
The data paper concept was initially based on the standard metadata descriptions, using the Ecological Metadata Language (EML). Apart from distinguishing a specialised place for dataset descriptions by creating a data paper article type, Pensoft has developed multiple workflows for streamlined import of metadata from various repositories and their conversion into data paper a manuscripts in Pensoft’s ARPHA Writing Tool (AWT). You can read more about the EML workflow in this blog post.
Similarly, we decided to create a specialised data paper article type for the omics community within Pensoft’s Biodiversity Data Journal to reflect the specific nature of omics data. We established a manuscript template to help standardise the description of such datasets and their most important features. This initiative was supported in part by the IGNITE project.
How can authors publish omics data papers?
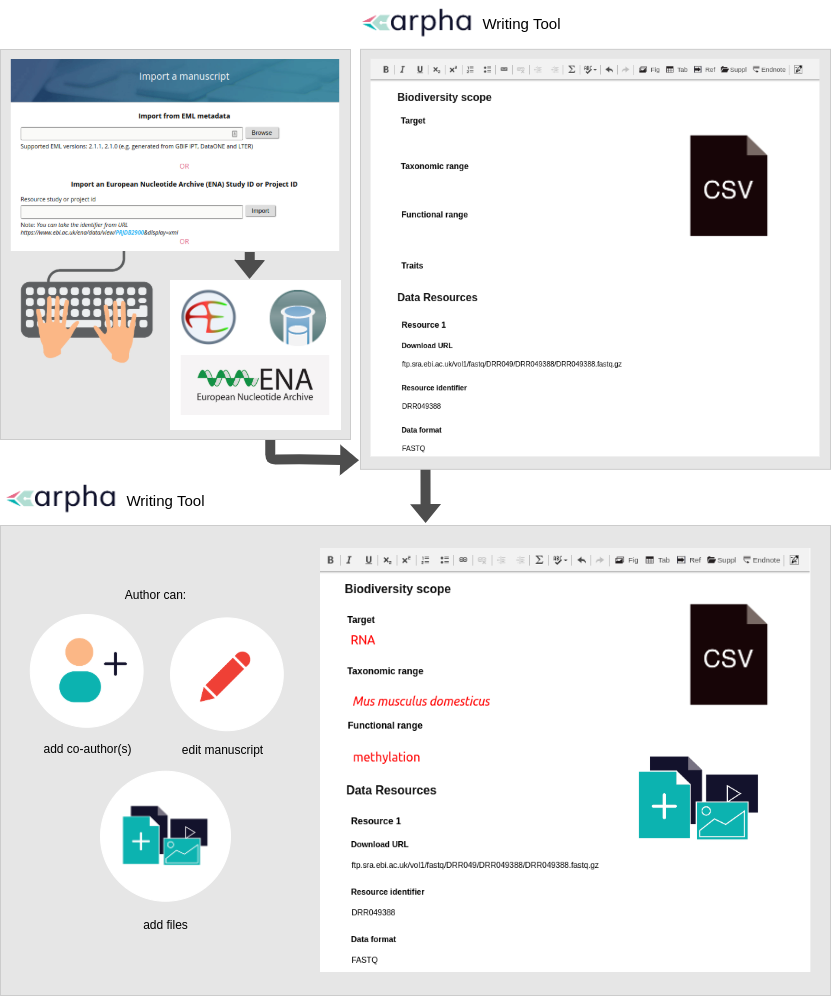
There are two ways to do publish omics data papers – (1) to write a data paper manuscript following the respective template in the ARPHA Writing Tool (AWT) or (2) to convert metadata describing a project or study deposited in EMBL-EBI’s European Nucleotide Archive (ENA) into a manuscript within the AWT.
The first method is straightforward but the second one deserves more attention. We focused on metadata published in ENA, which is part of the International Nucleotide Sequence Database Collaboration (INSDC) and synchronises its records with these of the other two members (DDBJ and NCBI). ENA is linked to the ArrayExpress and BioSamples databases, which describe sequencing experiments and samples, and follow the community-accepted metadata standards MINSEQE and MIxS. To auto populate a manuscript with a click of a button, authors can provide the accession number of the relevant ENA Study of Project and our workflow will automatically retrieve all metadata from ENA, as well as any available ArrayExpress or BioSamples records linked to it (Fig. 2). After that, authors can edit any of the article sections in the manuscript by filling in the relevant template fields or creating new sections, adding text, figures, citations and so on.
An important component of the OMICS data paper manuscript is a supplementary table containing MIxS-compliant metadata imported from BioSamples. When available, BioSamples metadata is automatically converted to a long table format and attached to the manuscript. The authors are not permitted to edit or delete it inside the ARPHA Writing Tool. Instead, if desired, they should correct the associated records in the sourced BioSamples database. We have implemented a feature allowing the automatic re-import of corrected BioSamples records inside the supplementary table. In this way, we ensure data integrity and provide a reliable and trusted source for accessing these metadata.
Fig. 2 Automated generation of omics data paper manuscripts through import and conversion of metadata associated with the Project ID or Study ID at ENA
Here is a step-by-step guide for conversion of ENA metadata into a data paper manuscript:
The author has published a dataset to any of the INSDC databases. They copy its ENA Study or Project accession number.
The author goes to the Biodiversity Data Journal (BDJ) webpage, clicks the “Start a manuscript” buttоn and selects OMICS Data Paper template in the ARPHA Writing Tool (AWT). Alternatively, the author can also start from the AWT website, click “Create a manuscript”, and select “OMICS Data Paper” as the article type, the Biodiversity Data Journal will be automatically marked by the system. The author clicks the “Import a manuscript” button at the bottom of the webpage.
The author pastes the ENA Study or Project accession number inside the relevant text box (“Import an European Nucleotide Archive (ENA) Study ID or Project ID”) and clicks “Import”.
The Project or Study metadata is converted into an OMICS data paper manuscript along with the metadata from ArrayExpress and BioSamples if available. The author can start making changes to the manuscript, invite co-authors and then submit it for technical evaluation, peer review and publication.
Our innovative workflow makes authoring omics data papers much easier and saves authors time and efforts when inserting metadata into the manuscript. It takes advantage of existing links between data repositories to unify biodiversity and omics knowledge into a single narrative. This workflow demonstrates the importance of standardisation and interoperability to integrate data and metadata from different scientific fields.
We have established a special collection for OMICS data papers in the Biodiversity Data Journal. Authors are invited to describe their omics datasets by using the novel streamlined workflow for creating a manuscript at a click of a button from metadata deposited in ENA or by following the template to create their manuscript via the non-automated route.
To stimulate omics data paper publishing, the first 10 papers will be published free of charge. Upon submission of an omics data paper manuscript, do not forget to assign it to the collection Next-generation publishing of omics data.
Pensoft’s journals introduce a standard appendix template for primary biodiversity data to provide direct harvesting and conversion to interlinked FAIR data
by Lyubomir Penev, Mariya Dimitrova, Iva Kostadinova, Teodor Georgiev, Donat Agosti, Jorrit Poelen
Linking open data is far from being a “new” or “innovative” concept ever since Tim Berners-Lee published his “5-Star Rating of Linked Open Data (LOD)” in 2006. The real question is how to implement it in practice, especially when most data are still waiting to be liberated from the narratives of more than 2.5 million scholarly articles published annually? We are still far from the dream world of linked and re-usable open data, not least because the inertia in academic publishing practices appears much stronger than the necessary cultural changes.
Already, there are many exciting tools and projects that harvest data from large corpora of published literature, including historical papers, such as PubMedCentral in biomedicine or Biodiversity Heritage Library in biodiversity science. Yet, finding data elements within the text of these corpora and linking data to external resources, even with the help of AI tools, is still in its infancy and is presently only half way there.
Data should not only be extracted, they should be semantically enriched and linked to both their original resources (e.g. accession numbers for sequences need to be linked to GenBank), but also between each other, as well as with data from other domains. Only then, the data can be made FAIR: Findable, Accessible, Interoperable and Re-usable. There are already research infrastructures, which provide extraction, liberation and semantic enrichment of data from the published narratives, for example, the Biodiversity Literature Repository, established at Zenodo by the digitisation company Plazi and the science publisher and technology provider Pensoft.
Quick access to high-quality Linked Open Data can become vitally important in cases like the current COVID-19 pandemic, when scientists need re-usable data from different research fields to come up with healthcare solutions. To complete the puzzle, they need data related to the taxonomy and biology of viruses, but also data taken from their potential hosts and vectors in the animal world, like bats or pangolins. Therefore, what could publishers do to facilitate the re-usability and interoperability of data they publish?
In a recently published paper by Patterson et al. (2020) on the phylogenetics of Old World Leaf-nosed bats in the journal ZooKeys, the authors and the publisher worked together to present the data on the studied voucher specimens of bats in an Appendix table, where each row represents a set of valuable links between the different data related to a specimen (see Fig. 1).
Fig. 1. Screenshot of the Appendix table with data on 324 specimens of bats (Patterson et al. 2020).
Specimens in natural history collections, for instance, have their so-called human-readable Specimen codes, for example, FMNH 221308 translates to a specimen with Catalogue No 221308, which is preserved in the collection of the Field Museum of Natural History Chicago (FMNH). When added to a collection, such voucher specimens are also assigned Globally Unique Identifiers (GUIDs). For example, the GUID of the above-mentioned specimen looks like this:
25634cae-5a0c-490b-b380-9cabe456316a
and is available from the Global Biodiversity Information Facilities (GBIF) under Original Occurrence ID (Fig. 2), from where computer algorithms can locate various types of data associated with the GUID of a particular specimen, regardless of where these data are stored. Examples for data types and relevant repositories, besides the occurrence record of the specimen available from the GBIF, are specimen data stored at the US-based natural history collection network iDigBio, specimen’s genetic sequences at GenBank, images or sound recordings stored in other third-party databases (e.g. MorphoSource, BioAcustica) and others.
The complex digital environment of various information linked to the globally unique identifier of a physical specimen in a collection together constitutes its “openDS digital specimen” representation, recently formulated within the EU project ICEDIG. Nevertheless, this complex linking could occur more easily and at a modest cost if only the GUIDs were always submitted to the respective data repositories together with the data about that particular specimen. Unfortunately, this is too rarely the case, hence we have to look for other ways to link these fragmented data.
Fig. 2. The representation of the specimen FMNH 221308 on GBIF. The Global Unique Identifier (GUID) of the specimen is shown in the Original Occurrence ID field.
Next to the Specimen code in the table (Fig. 1), there are one or more columns containing accession numbers of different gene sequences from that specimen, linked to their entries in GenBank. There is also a column for the species names associated with the specimens, linked through the Pensoft Taxon Profile (PTP) tool to several trusted international resources, in whose data holdings it appears, such as GBIF, GenBank, Biodiversity Heritage Library, PubMedCentral and many more (see example for the bat species Hipposideros ater). The next column contains the country where the specimen has been collected. The last columns contain the geo-coordinated locations of the collecting spot.
The structure of such a specimen-based table is not fixed and can also have several other data elements, for example, resolvable persistent identifiers for the deposition of MicroCt or other images of the specimen at a repository (e.g. MorphoSource) or of a tissue sample from where a virus has been isolated (see the sample table template below).
So far, so good, but what would the true value of those interlinked data be, besides that a reader could easily click on to a linked data item and see immediately more information about that particular element? What other missinglinks can we include to bring extra value to the data, so that these can be put together and re-used by the research community? Moreover, from where do we take these missing links?
The missing links are present in the table rows!
Firstly, if we open the GBIF record for the specimen in question (FMNH 221308), we see a lot of additional information there (Fig.2), which can be read by humans and retrieved by computers through GBIF’s Application Programming Interface (API). However, the links to the GenBank accession numbers KT583829 of the cyt-b gene sequenced from that specimen are missing, probably because, at the time of deposition of this specimen data in GBIF, its sequences had not yet been submitted to GenBank.
Now, we would probably wish to determine the specimen from which a particular gene has been sequenced and deposited in GenBank and where this specimen is preserved? We can easily click on any accession number in the table but, again, while we find a lot of useful information about the gene, for example, about the methods of sequencing, its taxon name etc., the voucher specimen’s GUID is actually missing (see KT583829 accession number of the specimen FMNH 221308, Fig. 3). How could we then locate the GUID of that specimen and the additional information linked to it? By publishing all this information in the Appendix in the way described here, we can easily locate this missing link between the specimen’s GUID and its sequence, either “by hand” or through API call requests provided by computers.
Fig. 3. GenBank record for the accession number KT583829 of the voucher specimen FMNH 221308. The GUID for the voucher specimen is not present in the record.
While biodiversity researchers are used to working with taxon names, these names are far from being stable entities. Names can either change over time or several different names could be associated with the same “thing” (synonyms) or identical names (homonyms) may be used for different “things”. The biodiversity community needs to resolve this problem by agreeing in the future Catalogue of Life on taxon names that are unambiguously identified with GUIDs through their taxon concepts (the content behind each name, according to a particular author who has already used that name in a publication, for example, Hipposideros vittatus (Peters, 1852) is used in the work of Patterson et al. (2020). Here comes another missing link that the table could provide – the link between the specimen, the taxon name to which it belongs and the taxon concept of that name, according to the article in which this name has been used and published.
Now, once we have listed all available linked information about several specimens belonging to a number of different species in a table, we can continue by adding some other important data, such as the biotic interactions between specimens or species. For example, we can name the table we have already constructed “Source specimens/species” and add to it some more columns under the heading “Target specimens/species”. The linking between the two groups of specimens or species in the extended biotic interaction table can be modelled using the OBO Relations Ontology, especially its list of terms, in a drop-down menu provided in the table template. Observed biotic interactions between specimens or species of the type “pathogen of”, “preys on”, “has vector” etc. can then be easily harvested and recorded in the Global Biotic Interactions database GloBI (see example on interactions between specimens).
As a result, we could have a table like the one below, where column names and data elements linked in the rows follow simple but strict rules:
Appendix A. Specimen data table. Legend: 1 – Two groupings of specimen/species data (Source and Target); 2 – Data type groups – not changeable, linked to the appropriate ontology terms, whenever possible; 3- Column names – not changeable, linked to the appropriate ontology terms, whenever possible; 4- Linked to; 5 – Linked by.
As one can imagine, some columns or cells provided in the table could be empty, as the full completion of this kind of data is rarely possible. For the purposes of a publication, the author can remove all empty columns or add additional columns, for example, for listing more genes or other types of data repository records containing data about a particular specimen. What should not be changed, though, are the column names, because they give the semantic meaning of the data in the table, which allows computers to transform them into machine-readable formats.
At the end of the publishing process, this table is published, not only for humans, but also in a code language, called Extensive Markup Language (XML), which makes the data in the table “understandable” for computers. At the moment of publication, tables published in XML contain not only data, but also information about what these data mean (semantics) and how they could be identified. Thanks to these two features, an algorithm can automatically convert the data into another machine-readable language: Resource Description Framework (RDF), which, in turn, makes the data compatible (interoperable) with other data that can be linked together, using any of the identifiers of the data elements in the table. Such converted data are represented as simple statements, called “RDF triples” and stored in special triple stores, such as OpenBiodiv or Ozymandias, from where knowledge graphs can be created and used further. As an example, one can search and access data associated with a particular specimen, but deposited at various data repositories, for example, other research groups might be interested in having together all pathogens that have been extracted from particular tissues from specimens belonging to a particular host species within a specific geographical location and so on.
Finding and preserving links between the different data elements, for example, between a Specimen, Tissue, Sequence, Taxon name and Location, is by itself a task deserving special attention and investments. How could such bi- and multilateral linking work? Having the table above in place alongside all relevant tools and competences, one can run, for example, the following operations via scripts and APIs:
Locate the GUID for Specimen Code at GBIF (= OccurrenceID)
Lookup sequence data associated with that GUID at GenBank
Represent the link between the GUID and Sequence accession numbers in a series of RDF triples
Link and express in RDF the presentation of the specimen on GBIF with the article where it has been published.
Automatically inform institutions/collections for published materials containing data on their holdings (specimens, authors, publications, links to other research infrastructures, etc.).
Semantic representation of data found in such an Appendix Specimen Data Table allows the utilisation of the Linked Open Data model to map and link several data elements to each other, including the provenance record, that is the original source (article) from where these links have been extracted (Fig. 4).
Fig. 4. Example of a semantic representation between some of the data elements from the Appendix Specimen Data Table. The proposed schema for mapping these elements uses mostly Darwin Core terms to maintain interoperability across different platforms. The link between the specimen GUID, GBIF occurrence, GenBank sequence and scientific name is marked in red.
At the very end, we will be able to construct a new “virtual super-table“ of semantic links between the data elements associated with a specimen, which, in the ideal case, would provide the fully-linked information on data and metadata along and across the lines:
Species A: Specimen <> Tissue sample <> Sequence <> Location <> Taxon name <> Habitat <> Publication source
↑↓
Species B: Specimen <> Tissue sample <> Sequence <> Location <> Taxon name <> Habitat <> Publication source
Retrieving such additional information, for example, about an occurrence from GBIF or sequence information from GenBank through APIs and linking these pieces of information together in one dataset opens new possibilities for data discovery and re-use, as well as to the reproducibility of the research results.
An example for how data from different resources could be put and represented together is the visualisation of the host-parasite interactions between species, such as those between bats and coronaviruses, indexed by the Global Biotic Interactions (GloBI) (Fig. 5). Various other interactions, such as pollination, feeding, co-existence and others, are stored in GloBI’s database which is also available in the form of a Linked Open Dataset, openly accessible through files or through a SPARQL endpoint.
Fig. 5. Visualisation resulting from querying biotic interactions existing between a bat species from order Chiroptera (Plecotus auritus) and bat coronavirus.
The technology of Linked Open Data is already widely used across many fields, so data scientists will not be tremendously impressed by the fact that all of the above is possible. The problem is how to get there. One of the most obvious ways seems to be for publishers to start publishing data in a standard, community-agreed format so that these can easily be handled by machines with little or no human intervention. Will they do that? Some will, but until it becomes routine practice, most of the published data, i.e. high-quality, peer-reviewed data vetted by the act of publishing, will remain hardly accessible, hence unusable.
This pilot was elaborated as a use case published as the first article in a free-to-publish special issue on the biology of bats and pangolins as potential vectors for Coronaviruses in the journal ZooKeys. An additional benefit from the use case is the digitisation and data liberation from many articles on bats contained in the bibliography of the Patterson et al. article by Plazi. The use case is also a contribution to the recently opened COVID-19 Joint Task Force of the Consortium of European Taxonomic Facilities (CETAF), the Distributed System for Scientific Collections (DiSSCo) and the Integrated Digitized Biocollections (iDigBio).
To facilitate the quick adoption of the improved data table standards, Pensoft invites all who would like to test and see how their data are distributed and re-used after publication to submit manuscripts containing specimen data and biotic interaction tables, following the standard described above. The authors would be provided with a template table for completion of all fields relevant to their study while conforming to the standard used by Pensoft.
This initiative was supported in part by the IGNITE project.
Information:
Pensoft Publishers
Field Museum of Natural History Chicago
References:
Patterson BD, Webala PW, Lavery TH, Agwanda BR, Goodman SM, Kerbis Peterhans JC, Demos TC (2020) Evolutionary relationships and population genetics of the Afrotropical leaf-nosed bats (Chiroptera, Hipposideridae). ZooKeys 929: 117-161. https://doi.org/10.3897/zookeys.929.50240
Jorrit H. Poelen, James D. Simons and Chris J. Mungall. (2014). Global Biotic Interactions: An open infrastructure to share and analyze species-interaction datasets. Ecological Informatics. https://doi.org/10.1016/j.ecoinf.2014.08.005.
Hardisty A, Ma K, Nelson G, Fortes J (2019) ‘openDS’ – A New Standard for Digital Specimens and Other Natural Science Digital Object Types. Biodiversity Information Science and Standards 3: e37033. https://doi.org/10.3897/biss.3.37033