On Monday, 28 April, the first day of the European Geosciences Union General Assembly 2025 (EGU 2025), participants had the chance to discover one of the most promising initiatives in biodiversity informatics: the Biodiversity Knowledge Hub (BKH). BKH was presented as part of a dedicated poster session, titled “Biodiversity Knowledge Hub: Addressing the impacts of environmental change by linking Research Infrastructures, Global Aggregators and Community Networks“.
Understanding and addressing the impacts of environmental change on biodiversity and ecosystems demands access to reliable FAIR data (as in Findable, Accessible, Interoperable, Reusable). However, the current landscape is often fragmented, making it difficult to combine and use these resources effectively.
Enter the Horizon-funded project Biodiversity Community Integrated Knowledge Library (BiCIKL): a pioneering initiative that demonstrates the transformative power of interdisciplinary collaboration. Coordinated by Pensoft, BiCIKL ran between 2021 and 2024.
Within BiCIKL, 14 European institutions from ten countries teamed up with the aim to integrate biodiversity data across research infrastructures, scientific repositories, and expert communities.
Through this integration, BiCIKL bridged the gap between isolated knowledge systems and delivered actionable insights to guide conservation and resilience efforts. The project embodies the principles of open science by demonstrating how interdisciplinary collaboration can turn fragmented data into cohesive, usable knowledge for researchers, policymakers, and practitioners.
At the heart of BiCIKL’s success is the Biodiversity Knowledge Hub (BKH): an innovative platform that provides seamless access to biodiversity data, tools, and workflows. The BKH fosters interoperability between diverse resources, thus making it easier to combine information from different sources. Whether for advanced research analytics or policymaking in support of sustainable development, the BKH empowers users with tools tailored to their needs.
A few of the standout features of the BKH include:
Modular design to allow continuous expansion and adaptability to new challenges in biodiversity and climate resilience
Interoperable systems that connect a variety of databases, repositories, and services to deliver integrated knowledge.
Community building by welcoming a broad network of stakeholders to ensure the platform’s long-term sustainability and growth.
Watch the Biodiversity Knowledge Hubvideo on YouTube.
Setting a New Benchmark in Biodiversity Informatics
Through its collaborative approach, BiCIKL set a new standard for how biodiversity and climate resilience initiatives can be harmonised globally. By showcasing best practices in data integration, capacity building, and stakeholder engagement, BiCIKL became much more than a project: it turned into a blueprint for future biodiversity knowledge infrastructures.
The Biodiversity Knowledge Hub serves to demonstrate how harmonised standards and active collaboration are key to unlocking the full potential of biodiversity data. In doing so, its mission is to create scalable, long-term solutions that are crucial for addressing today’s pressing environmental challenges.
The poster presentation at EGU25 outlined the methodologies and technologies driving the BKH, emphasizing its role as a pioneering model for integrated biodiversity knowledge and action. As environmental pressures continue to mount, the work of BiCIKL and the Biodiversity Knowledge Hub offers a hopeful path forward—one where knowledge flows freely, collaborations flourish, and data-driven solutions guide our way to a more resilient future.
Visit the Biodiversity Community Integrated Knowledge Library (BiCIKL) project’s website at: https://bicikl-project.eu/.
The European Union (EU) has been working to protect nature for decades, with the Natura 2000 network now safeguarding over 18% of EU land and 9% of its marine territory. Yet, biodiversity is still in trouble, with only 50% of bird species and 15% of habitats in good conservation status.
To turn the tide, the EU’s Biodiversity Strategy for 2030 will expand the existing Natura 2000 areas, implement the EU’s first-ever Nature Restoration Law, and introduce concrete measures to achieve global biodiversity targets. Success will depend on enhancing biodiversity monitoring, making better use of data and gaining a clearer picture of how nature is changing.
Addressing this urgent challenge, the EU Horizon project BMD (abbreviated for Biodiversity Meets Data) will offer a centralised platform (Single Access Point or SAP) for improved biodiversity monitoring across Europe.
Pensoft’s role
Pensoft will play a role in Biodiversity Meets Data’s impact by planning and implementing the communication, dissemination and exploitation of project results, as well as helping with the training and capacity building for BMD’s end-users, which will be led by LifeWatch ERIC. Pensoft will adopt a multi-format approach to knowledge transfer with tailored outputs for the scientific community, decision-makers, industry representatives and the general public.
Furthermore, the BMD SAP will also incorporate elements of the Biodiversity Knowledge Hub (BKH), developed under the BiCIKL project, coordinated by Pensoft.
“It’s incredibly rewarding to see the continuity in our projects, with the legacy of the BiCIKL project continuing with Biodiversity Meets Data. This seamless progression not only builds on our past successes but also ensures that our work continues to deliver long-lasting value to the biodiversity community.”
said Prof. Dr. Lyubomir Penev, CEO and Founder of Pensoft, and project coordinator of BiCIKL (abbreviated from Biodiversity Community Integrated Knowledge Library).
The BMD project consortium at the project’s kick-off meeting in early March 2025 (Leiden, the Netherlands).
International consortium
Coordinated by Naturalis Biodiversity Center, the project brings together 14 partner organisations from 11 countries to develop innovative solutions for biodiversity management.
Visit the BMD project website at https://bmd-project.eu/, and make sure to follow the project’s progress via our social media channels on Blueskyand Linkedin.
Pensoft is among the first signatories dedicated to fully leveraging biodiversity knowledge from research publications within an open science framework by 2035
Some of the world’s leading institutions, experts and scientific infrastructures relating to biodiversity information are uniting around a new 10-year roadmap to ‘liberate’ data presently trapped in research publications.
The initiative aims to enable the creation of a ‘Libroscope’ – a mechanism for unlocking and linking data from scientific literature to support understanding of biodiversity, as the microscope and telescope previously revolutionized science. The plan largely builds on existing technology and workflows, and does not rely on construction of a new technical infrastructure.
The proposals result from a symposium involving 51 experts from 10 countries held in August 2024 at the 7th-century monastery at Disentis in the Swiss Alps, supported financially by the Arcadia Fund. The symposium was a 10-year follow-up to the 2014 meeting at Meise Botanic Garden in Belgium, which led to the Bouchout Declaration on open biodiversity knowledge management. The Disentis meeting evaluated progress since then, and identified priorities for the decade ahead.
Group photo from the Disentis meeting (Switzerland, August 2024).
While acknowledging major advances in the sharing and use of open biodiversity data, the participants noted that accessing data within research publications is often very cumbersome, with databases disconnected from each other and from the source literature. Liberating and linking data from such publications – estimated to encompass more than 500 million total pages – would represent a compelling mission for the next decade.
A roadmap for staged action over the next decade was agreed by the symposium participants, with the following vision: “By 2035, the power of biodiversity knowledge from research publications will be fully leveraged within an open science framework, including unencumbered data discovery, access, and re-use across scientific disciplines and policy applications.”
The ‘Disentis Roadmap’, further developed following the symposium, and now released publicly, has already been signed by 26 institutions and a further 46 individual experts on five continents – among them major natural history collections such as Meise Botanic Garden, Botanic Garden and Botanical Museum Berlin, the National Museum of Natural History in Paris, and Royal Botanic Gardens, Kew; infrastructures such as the Global Biodiversity Information Facility (GBIF), Biodiversity Heritage Library (BHL), Catalogue of Life, LifeWatch ERIC and the Swiss Institute of Bioinformatics (SIB); journal publishers such as Pensoft Publishers and the European Journal of Taxonomy; research institutions such as Chinese Academy of Sciences and the Senckenberg Society for Nature Research; and networks such as TDWG Biodiversity Information Standards and Consortium of European Taxonomic Facilities (CETAF). See the full list of signatories here.
The roadmap remains open for further signatures, ahead of the launch of an action plan at the Living Data conference in Bogotá, Colombia in October 2025. The original signatories hope that a much broader group of institutions and individuals, across global regions and disciplines, will join the initiative and help to shape implementation of its vision. Engagement of funders will also be critical to realize its objectives.
The specific goals of the roadmap are that by 2035:
All major public biodiversity research funders and academic publishers will encourage and enable publication of data adhering to the FAIR principles (findable, accessible, interoperable and reusable);
Biodiversity-focussed publications will be accessible in machine-actionable formats, with all non-copyrightable parts of articles flowing into public data repositories;
Published research on biodiversity will be ‘fully AI-ready’, that is openly available for AI training and properly labelled for ingestion by machine-learning modelled, within appropriate ethical and legal frameworks;
Dedicated funding from research and infrastructure grants will be reserved for ensuring access to biodiversity data and knowledge.
“We finally have a chance to make a quantum leap in understanding and monitoring biodiversity, by leveraging the power of digital technologies, and combining modern genomic methods with the vast amount of research data published daily and currently stuck in the publication prison. The ‘Libroscope’ will help to explore the universe of existing knowledge, accumulated over hundreds of years, and bring it to the forefront of developments in the digital age, helping nature and people across the globe.”
commented Donat Agosti of the Swiss organization Plazi, who convened the Disentis symposium.
A recent demonstration of the principles of the ‘Libroscope’ was the launch of data portals for the European Journal of Taxonomy (EJT) and the Biodiversity Data Journal, as part of the GBIF hosted portal programme. The new portals showcase the data contained within taxonomic literature published by the journals, making use of the workflow originally developed by Plazi and partners to extract re-usable data from articles traditionally locked in static PDF files. Once created, these data objects then flow into platforms such as GBIF, Catalogue of Life, ChecklistBank and the BiodiversityPMC, and are stored in the Biodiversity Literature Repository at Zenodo hosted by CERN. This process enables data on new species and the location of related specimens cited in the literature to be openly accessible in near-real time, and available for long-term access.
The newly launched Biodiversity Data Journal data portal is part of the GBIF-hosted portal programme. It showcase the data contained within taxonomic literature published by the journal.
“As a publisher of dozens of renowned academic journals in the field of biodiversity and systematics with experience in technology development, at Pensoft, we have always recognised the key role of academic publishers in scholarly communication. It’s not only about publishing the latest research. Above all, it’s about putting scientific work in the hands of those who need it: be it future researchers, policy-makers or their AI-powered assistants. Now that the Disentis roadmap is already a fact, we hope that many others will also join us on this ambitious journey to open up the knowledge we have today for those who will need it tomorrow.”
said Prof. Dr. Lyubomir Penev, founder and CEO at Pensoft, who attended the Disentis symposium.
“By repositioning scientific publications as an essential part of the research cycle, the Disentis Roadmap encourages publishers and the scientific community to move beyond open access towards FAIR access. Proactively ensuring data quality and dissemination is the core mission of the European Journal of Taxonomy. In this way, EJT enhances the immediate discoverability and usability of the taxonomic information it publishes, making it more valuable to the scientific community as a whole. Adherence to the Disentis vision marks a crucial step in the liberation and enrichment of knowledge about biodiversity.”
said Laurence Bénichou, founder and liaison officer of the European Journal of Taxonomy.
The Chief Executive Officer of Meise Botanic Garden, Steven Dessein, who attended the Disentis Symposium, commented:
“Meise Botanic Garden fully supports the Disentis Roadmap, which builds on the foundation laid by the Bouchout Declaration. Open biodiversity data is essential to tackling today’s pressing environmental challenges, from biodiversity loss to climate change. By ensuring research publications become more accessible and interconnected, this roadmap represents a critical step toward harnessing biodiversity knowledge for science, policy, and conservation.”
Christophe Déssimoz, Executive Director of the SIB Swiss Institute of Bioinformatics, another signatory of the Disentis Roadmap, added:
“We have long championed the principles of open, structured, and interoperable data to advance life sciences. The Disentis Roadmap applies these same principles to biodiversity knowledge, ensuring that critical data is not just available, but truly actionable for research, policy, and conservation.”
The director of the Botanic Garden and Botanical Museum of Berlin, Thomas Borsch, noted that more than any other branch of science, taxonomic research depended on the machine-actionable availability of biodiversity data from the literature:
“The ‘Libroscope’ postulated in the Disentis Roadmap will enable a new generation of research workflows through its interoperable approach,” said Professor Borsch. “This will be very helpful to address pressing issues in biodiversity research and in particular to improve the use of quality information on organisms in national and global assessments.”
The chief scientist of the national museum of natural history in Paris (MNHN) said:
“We, like all similar museums and taxonomic institutions, are focussed on linking taxonomic and collection data with digital reproductions and molecular information to create the ‘extended digital specimen.’ However, the potential of taxonomic publications and text mining should not be underestimated either. On the contrary, it is a smart and accessible way to dig into scientific publications so as to retrieve, link and consolidate, research data of great relevance to many disciplines. This is why our institution fully supports the Disentis initiative.”
Christos Arvanitidis, CEO of the Biodiversity and Ecosystem e-Science Infrastructure LifeWatch ERIC, commented:
“LifeWatch ERIC is proud to be part of this initiative, as providing access and support to biodiversity and ecosystem data is fully aligned with our mission. The Disentis Roadmap opens up new opportunities for our research infrastructure to help make what science has provided us accessible and usable, and to improve the FAIRness of data for research and science-based policy.”
Tim Robertson, deputy director and head of informatics at the Global Biodiversity Information Facility (GBIF), who also attended the Disentis meeting added:
“We’re excited to see the results from Disentis partners like Plazi, BHL, Pensoft and the European Journal of Taxonomy who are focussed on liberating data connected with scientific publications,” said . “GBIF will continue to do our part to improve the standards, tools and services that help expand both the benefits and the impact of FAIR and open data on biodiversity science and policy.”
Olaf Bánki, Executive Director of the Catalogue of Life, commented:
“We call out to the scientific community, especially the younger generation, to join our effort in unlocking biodiversity data from literature. Actionable biodiversity and taxonomic data from digitized literature contributes to creating an index of all described organisms of all life on earth. We need such data to tackle and understand the current biodiversity crisis.”
Yet another hectic year has passed for our team at Pensoft, so it feels right to look back at the highlights from the last 12 months, as we buckle up for the leaps and strides in 2025.
In the past, we have used the occasion to take you back to the best moments of our most popular journals (see this list of 2023 highlights from ZooKeys, MycoKeys, PhytoKeys and more!); share milestones related to our ARPHA publishing platform (see the new journals, integrations and features from 2023); or let you reminisce about the coolest research published across our journals during the year(check out our Top 10 new species from 2021).
In 2022, when we celebrated our 30th anniversary on the academic scene, we extended our festive spirit throughout the year as we dived deep into those fantastic three decades. We put up Pensoft’s timeline and finished the year with a New Species Showdown tournament, where our followers on (what was back then) Twitter voted twice a week for their favourite species EVER described on the pages of our taxonomic journals.
Spoiler alert: we will be releasing our 2024 Top 10 New Species on Monday, 23 December, so you’d better go to the right of this screen and subscribe to our blog!
As we realised we might’ve been a bit biased towards our publishing activities over the years, this time, hereby, we chose to present you a retrospection that captures our best 2024 moments from across the departments, and shed light on how the publishing, technology and project communication endeavours fit together to make Pensoft what it is.
In truth, we take pride in being an exponentially growing family of multiple departments that currently comprises over 60 full-time employees and about a dozen freelancers working from all corners of the world, including Australia, Canada, Belgium and the United Kingdom. Together, we are all determined to make sure we continuously improve our service to all who have trusted us: authors, reviewers, editors, client journals, learned societies, research institutions, project consortia and other external collaborators.
After all, great deeds are only possible when you team up with great like-minded people!
In 2024, at Pensoft, we were hugely pleased to see a significant growth in the published output at almost all our journals, including record-breaking numbers in both submissions and publications at flagship titles of ours, including the Biodiversity Data Journal, PhytoKeys and MycoKeys.
Later in 2024, our colleagues, who work together with our clients to ensure their journals comply with the requirements of the top scholarly databases before they apply for indexation, informed us that another two journals in our portfolio have had their applications to Clarivate’s Web of Science successfully accepted. These are the newest journal of the International Association of Vegetation Science: Vegetation and Classification, and Metabarcoding and Metagenomics: a journal we launched in 2017 in collaboration with a team of brilliant scientists working together at the time within the DNAquaNet COST Action.
In 2024, we also joined the celebrations of our long-time partners at the Museum für Naturkunde Berlin, whose three journals: Zoosystematics and Evolution, Deutsche Entomologische Zeitschrift and Fossil Record are all part of our journal portfolio. This year marked the 10th Open Access anniversary of the three journals.
In the meantime, we also registered a record in new titles either joining the Pensoft portfolio or opting for ARPHA Platform’s white-label publishing solution, where journal owners retain exclusivity for the publication of their titles, yet use ARPHA’s end-to-end technology and as many human-provided services as necessary.
Pensoft’s CEO and founder Prof. Dr. Lyubomir Penev with Prof. Dr. Marc Stadler, Editor-in-Chief of IMA Fungus and President of the International Mycological Association at the Pensoft booth at the 12th International Mycological Congress (August, the Netherlands).
Amongst our new partners are the International Mycological Association who moved their official journal IMA Fungus to ARPHA Platform. As part of Pensoft’s scholarly portfolio, the renowned journal joins another well-known academic title in the field of mycology: MycoKeys, which was launched by Pensoft in 2011. The big announcement was aptly made public at this year’s 12th International Mycological Congress where visitors of the Pensoft stand could often spot newly elected IMA President and IMA Fungus Chief editor: Marc Stadler chatting with our founder and CEO Lyubomir Penev by the Pensoft/MycoKeys booth.
On our end, we did not stop supporting enthusiastic and proactive scientists in their attempt to bridge gaps in scientific knowledge. In January, we launched the Estuarine Management and Technologies journal together with Dr. Soufiane Haddout of the Ibn Tofail University, Morocco.
Later on, Dr. Franco Andreone (Museo Regionale di Scienze Naturali, Italy) sought us with the idea to launch a journal addressing the role of natural history museums and herbaria collections in scientific progress. This collaboration resulted in the Natural History Collections and Museomics journal, officially announced at the joint TDWG-SPNHC conference in Okinawa, Japan in August.
Around this time, we finalised our similarly exciting journal project in partnership with Prof. Dr. Volker Grimm (UFZ, Germany), Prof. Dr. Karin Frank (UFZ, Germany), Prof. Dr. Mark E. Hauber (City University of New York) and Prof. Dr. Florian Jeltsch (University of Potsdam, Germany). The outcome of this collaboration is called Individual-based Ecology: a journal that aims to promote an individual-based perspective in ecology, as it closes the knowledge gap between individual-level responses and broader ecological patterns.
The three newly-launched journals are all published under the Diamond Open Access model, where neither access, nor publication is subject to charges.
As you can see, we have a lot to be proud of in terms of our journals. This is also why in 2024 our team took a record number of trips to attend major scientific events, where we got the chance to meet face-to-face with long-time editors, authors, reviewers and readers of our journals. Even more exciting was meeting the new faces of scientific research and learning about their own take on scholarship and academic journals.
Pensoft’s CEO and founder Prof. Dr. Lyubomir Penev welcomed editors at PhytoKeys to the Pensoft-PhytoKeys-branded booth at the XX International Botanical Congress in July 2024 (Spain).
We cannot possibly comment on Pensoft’s tech progress in 2024 without mentioning the EU-funded project BiCIKL (acronym for Biodiversity Community Integrated Knowledge Library) that we coordinated for three years ending up last April.
This 36-month endeavour saw 14 member institutions and 15 research infrastructures representing diverse actors from the biodiversity data realm come together to improve bi-directional links between different platforms, standards, formats and scientific fields.
Following these three years of collaborative work, we reported a great many notable research outputs from our consortium (find about them in the open-science project collection in the Research Ideas and Outcomes journal, titled “Towards interlinked FAIR biodiversity knowledge: The BiCIKL perspective”) that culminated in the Biodiversity Knowledge Hub: a one-stop portal that allows users to access FAIR and interlinked biodiversity data and services in a few clicks; and also a set of policy recommendations addressing key policy makers, research institutions and funders who deal with various types of data about the world’s biodiversity, and are thereby responsible to ensuring there findability, accessibility, interoperability and reusability (FAIR-ness).
Apart from coordinating BiCIKL, we also worked side-by-side with our partners to develop, refine and test each other’s tools and services, in order to make sure that they communicate efficiently with each other, thereby aligning with the principles of FAIR data and the needs of the scientific community in the long run.
During those three years we made a lot of refinements to our OpenBiodiv: a biodiversity database containing knowledge extracted from scientific literature, built as an Open Biodiversity Knowledge Management System, and our ARPHA Writing Tool. The latter is an XML-based online authoring environment using a large set of pre-formatted templates, where manuscripts are collaboratively written, edited and submitted to participating journals published on ARPHA Platform. What makes the tool particularly special is its multiple features that streamline and FAIRify data publishing as part of a scientific publication, especially in the field of biodiversity knowledge. In fact, we made enough improvements to the ARPHA Writing Tool that we will be soon officially releasing its 2.0 version!
OpenBiodiv – The Open Biodiversity Knowledge Management System
ARPHA Writing Tool 2.0
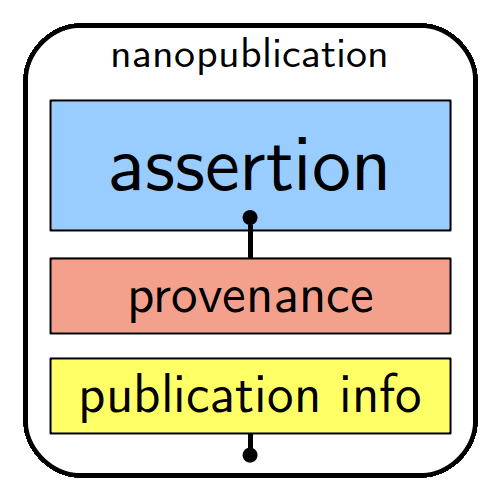
Amongst our collaborative projects are the Nanopublications for Biodiversity workflow that we co-developed with KnowledgePixels to allow researchers to ‘fragment’ their most important scientific findings into machine-actionable and machine-interpretable statements. Being the smallest units of publishable information, these ‘pixels of knowledge’ present an assertion about anything that can be uniquely identified and attributed to its author and serve to communicate a single statement, its original source (provenance) and citation record (publication info).
Nanopublications for Biodiversity
In partnership with the Swiss-based Text Mining group of Patrick Ruch at SIB and the text- and data-mining association Plazi, we brought the SIB Literature Services (SIBiLS) database one step closer to solidifying its “Biodiversity PMC” portal and working title.
Understandably, we spent a lot of effort, time and enthusiasm in raising awareness about our most recent innovations, in addition to our long-standing workflows, formats and tools developed with the aim to facilitate open and efficient access to scientific data; and their integration into published scholarly work, as well as receiving well-deserved recognition for their collection.
We just can’t stress it enough how important and beneficial it is for everyone to have high-quality FAIR data, ideally made available within a formal scientific publication!
🗨️Imagine if ALL these links were provided as hyperlinks within a #scholarly publication!
Pensoft’s CTO Teodor Georgiev talks about innovative methods and good practices in the publication of biodiversity data in scholarly papers at the First national meeting of the Bulgarian Barcode of Life (BgBOL) consortium (December, Bulgaria).
🤔What is a Data Paper?
👍 A means to describe a #dataset – like the ones on @GBIF – in a standardised, widely accepted #scientific article format.
👇🧵Highlights from @LyuboPenev's talk at the int'l symposium "#BiodiversityData in montane & arid Eurasia" in Kazakhstan 🇰🇿
Pensoft’s CEO and founder Prof. Dr. Lyubomir Penev presenting his “Data papers on biodiversity” talk at the “Biodiversity data in montane and arid Eurasia” symposium jointly organized by GBIF and by the Institute of Zoology of Republic of Kazakhstan (November, Kazakhstan).
.
📸Today, at the @EASEeditors symposium, our @teodorpensoft gave a sneak peek into the AI-assisted tools at @ARPHAplatform we have been working on (e.g. Word -> JATS XML conversion) and the #ARPHA Writing Tool 2.0 (coming up in early 2025)!🎉
Pensoft’s CTO Teodor Georgiev presents new features and workflows currently in testing at the ARPHA Writing Tool 2.0 at the EASE Autumn Symposium 2024 (online event).Pensoft’s Head of Journal development, Marketing and PR Iva Boyadzhieva talks about Pensoft’s data publishing approach and innovations at the German Ecological Society 53rd Annual Conference (September, Germany).
Pensoft as a science communicator
At our Project team, which is undoubtedly the fastest developing department at Pensoft, science communicators are working closely with technology and publishing teams to help consortia bring their scientific results closer to policy actors, decision-makers and the society at large.
Ultimately, bridging the notorious chasm between researchers and global politics boils down to mutual understanding and dialogue.
Pensoft’s communication team attended COP16 (November 2024, Colombia) along with partners at the consortia of CO-OP4CBD, BioAgora and RESPIN: three Horizon Europe projects, whose communication and dissemination is led by Pensoft.
Throughout 2024, the team, comprising 20 science communicators and project managers, has been working as part of 27 EU-funded project consortia, including nine that have only started this year (check out all partnering projects on the Pensoft website, ordered from most recently started to oldest). Apart from communicating key outcomes and activities during the duration of the projects, at many of the projects, our team has also been actively involved in their grant proposal drafting, coordination, administration, platform development, graphic and web design and others (see all project services offered by Pensoft to consortia).
📸As leaders of the “Stakeholder engagement, comms & dissemination” WP at @BCubedProject, we joined the annual meeting to report on project branding, #scicomm & #DataManagement.
Naturally, we had a seat on the front row during many milestones achieved by our partners at all those 27 ongoing projects, and communicated to the public by our communicators.
Amongst those are the release of the InsectsCount web application developed within the Horizon 2020 project SHOWCASE. Through innovative gamification elements, the app encourages users to share valuable data about flower-visiting insects, which in turn help researchers gain new knowledge about the relationship between observed species and the region’s land use and management practices (learn more about InsectsCount on the SHOWCASE prroject website).
Another fantastic project output was the long-awaited dataset of maps of annual forest disturbances across 38 European countries derived from the Landsat satellite data archive published by the Horizon Europe project ForestPaths in April (find more about the European Forest Disturbance Atlas on the ForestPaths project website).
In a major company highlight, last month, our project team participated in COP29 in Baku, Azerbaijan with a side event dedicated to the role of open science and science communication in climate- and biodiversity-friendly policy.
Pensoft’s participation at COP29 – as well as our perspective on FAIR data and open science – were recently covered in an interview by Exposed by CMD (a US-based news media accredited to cover the event) with our science communicator Alexandra Korcheva and project manager Boris Barov.
You see, A LOT of great things worth celebrating happened during the year for us at Pensoft: all thanks to ceaselessly flourishing collaboration based on transparency, trust and integrity. Huge ‘THANK YOU!’ goes to everyone who has joined us in our endeavours!
Here’s to many more shared achievements coming up in 2025!
***
Now, to keep up with our next steps in real time, we invite you to follow Pensoft on social media on BlueSky,X,Facebook,InstagramandLinkedin!
Don’t forget to also enter your email to the right to sign up for new content from this blog!
Within theBiodiversity Community Integrated Knowledge Library (BiCIKL) project, 14 European institutions from ten countries, spent the last three years elaborating on services and high-tech digital tools, in order to improve the findability, accessibility, interoperability and reusability (FAIR-ness) of various types of data about the world’s biodiversity. These types of data include peer-reviewed scientific literature, occurrence records, natural history collections, DNA data and more.
By ensuring all those data are readily available and efficiently interlinked to each other, the project consortium’s intention is to provide better tools to the scientific community, so that it can more rapidly and effectively study, assess, monitor and preserve Earth’s biological diversity in line with the objectives of the likes of the EU Biodiversity Strategy for 2030 and the European Green Deal. Their targets require openly available, precise and harmonised data to underpin the design of effective measures for restoration and conservation, reminds the BiCIKL consortium.
Since 2021, the project partners at BiCIKL have been working together to elaborate existing workflows and links, as well as create brand new ones, so that their data resources, platforms and tools can seamlessly communicate with each other, thereby taking the burden off the shoulders of scientists and letting them focus on their actual mission: paving the way to healthy and sustainable ecosystems across Europe and beyond.
Now that the three-year project is officially over, the wider scientific community is yet to reap the fruits of the consortium’s efforts. In fact, the end of the BiCIKL project marks the actual beginning of a European- and global-wide revolution in the way biodiversity scientists access, use and produce data. It is time for the research community, as well as all actors involved in the study of biodiversity and the implementation of regulations necessary to protect and preserve it, to embrace the lessons learned, adopt the good practices identified and build on the knowledge in existence.
This is why amongst the BiCIKL’s major final research outputs, there are two Policy Briefs meant to summarise and highlight important recommendations addressed to key policy makers, research institutions and funders of research. After all, it is the regulatory bodies that are best equipped to share and implement best practices and guidelines.
Most recently, the BiCIKL consortium published two particularly important policy briefs, both addressed to the likes of the European Commission’s Directorate-General for Environment; the European Environment Agency; the Joint Research Centre; as well as science and policy interface platforms, such as the EU Biodiversity Platform; and also organisations and programmes, e.g. Biodiversa+ and EuropaBON, which are engaged in biodiversity monitoring, protection and restoration. The policy briefs are also to be of particular use to national research funds in the European Union.
One of the newly published policy briefs, titled “Uniting FAIR data through interlinked, machine-actionable infrastructures”, highlights the potential benefits derived from enhanced connectivity and interoperability among various types of biodiversity data. The publication includes a list of recommendations addressed to policy-makers, as well as nine key action points. Understandably, amongst the main themes are those of wider international cooperation; inclusivity and collaboration at scale; standardisation and bringing science and policy closer to industry. Another major outcome of the BiCIKL project: the Biodiversity Knowledge Hub portal is noted as central to many of these objectives and tasks in its role of a knowledge broker that will continue to be maintained and updated with additional FAIR data-compliant services as a living legacy of the collaborative efforts at BiCIKL.
The second policy brief, titled “Liberate the power of biodiversity literature as FAIR digital objects”, shares key actions that can liberate data published in non-machine actionable formats and non-interoperable platforms, so that those data can also be efficiently accessed and used; as well as ways to publish future data according to the best FAIR and linked data practices. The recommendations highlighted in the policy brief intend to support decision-making in Europe; expedite research by making biodiversity data immediately and globally accessible; provide curated data ready to use by AI applications; and bridge gaps in the life cycle of research data through digital-born data. Several new and innovative workflows, linkages and integrative mechanisms and services developed within BiCIKL are mentioned as key advancements created to access and disseminate data available from scientific literature.
While all policy briefs and factsheets – both primarily targeted at non-expert decision-makers who play a central role in biodiversity research and conservation efforts – are openly and freely available on the project’s website, the most important contributions were published as permanent scientific records in a BiCIKL-branded dedicated collection in the peer-reviewed open-science journal Research Ideas and Outcomes (RIO). There, the policy briefs are provided as both a ready-to-print document (available as supplementary material) and an extensive academic publication.
Currently, the collection: “Towards interlinked FAIR biodiversity knowledge: The BiCIKL perspective” in the RIO journal contains 60 publications, including policy briefs, project reports, methods papers, conference abstracts, demonstrating and highlighting key milestones and project outcomes from along the BiCIKL’s journey in the last three years. The collection also features over 15 scientific publications authored by people not necessarily involved in BiCIKL, but whose research uses linked open data and tools created in BiCIKL. Their publications were published in a dedicated article collection in the Biodiversity Data Journal.
Leiden – also known as the ‘City of Keys’ and the ‘City of Discoveries’ – was aptly chosen to host the third Empowering Biodiversity Research (EBR III) conference. The two-day conference – this time focusing on the utilisation of biodiversity data as a vehicle for biodiversity research to reach to Policy – was held in a no less fitting locality: the Naturalis Biodiversity Center.
On 25th and 26th March 2024, the delegates got the chance to learn more about the latest discoveries, trends and innovations from scientists, as well as various stakeholders, including representatives of policy-making bodies, research institutions and infrastructures. The conference also ran a poster session and a Biodiversity Informatics market, where scientists, research teams, project consortia, and providers of biodiversity research-related services and tools could showcase their work and meet like-minded professionals.
BiCIKL stops at the Naturalis Biodiversity Center
The main outcome of the BiCIKL project: the Biodiversity Knowledge Hub, a one-stop knowledge portal to interlinked and machine-readable FAIR data.
The famous for its bicycle friendliness country also made a suitable stop for BiCIKL (an acronym for the Biodiversity Community Integrated Knowledge Library): a project funded under the European Commission’s Horizon 2020 programme that aimed at triggering a culture change in the way users access, (re)use, publish and share biodiversity data. To do this, the BiCIKL consortium set off on a 3-year journey to build on the existing biodiversity data infrastructures, workflows, standards and the linkages between them.
Many of the people who have been involved in the project over the last three years could be seen all around the beautiful venue. Above all, Naturalis is itself one of the partnering institutions at BiCIKL. Then, on Tuesday, on behalf of the BiCIKL consortium and the project’s coordinator: the scientific publisher and technology innovator: Pensoft, Iva Boyadzhieva presented the work done within the project one month ahead of its official conclusion at the end of April.
As she talked about the way the BiCIKL consortium took to traverse obstacles to wider use and adoption of FAIR and linked biodiversity data, she focused on BiCIKL’s main outcome: the Biodiversity Knowledge Hub (BKH).
Key results from the BiCIKL project three years into its existence presented by Pensoft’s Iva Boyadzhieva at the EBR III conference.
Intended to act as a knowledge broker for users who wish to navigate and access sources of open and FAIR biodiversity data, guidelines, tools and services, in practicality, the BKH is a one-stop portal for understanding the complex but increasingly interconnected landscape of biodiversity research infrastructures in Europe and beyond. It collates information, guidelines, recommendations and best practices in usage of FAIR and linked biodiversity data, as well as a continuously expanded catalogue of compliant relevant services and tools.
At the core of the BKH is the FAIR Data Place (FDP), where users can familiarise themselves with each of the participating biodiversity infrastructures and network organisations, and also learn about the specific services they provide. There, anyone can explore various biodiversity data tools and services by browsing by their main data type, e.g. specimens, sequences, taxon names, literature.
While the project might be coming to an end, she pointed out, the BKH is here to stay as a navigation system in a universe of interconnected biodiversity research infrastructures.
To do this, not only will the partners continue to maintain it, but it will also remain open to any research infrastructure that wishes to feature its own tools and services compliant with the linked and FAIR data requirements set by the BiCIKL consortium.
Indisputably, the ‘hot’ topics at the EBR III were the novel technologies for remote and non-invasive, yet efficient biomonitoring; the utilisation of data and other input sourced by citizen scientists; as well as leveraging different types and sources of biodiversity data, in order to better inform decision-makers, but also future-proof the scientific knowledge we have collected and generated to date.
Project’s coordinator Dr Quentin Groom presents the B-Cubed’s approach towards standardised access to biodiversity data for the use of policy-making at the EBR III conference.
Amongst the other Horizon Europe projects presented at the EBR III conference was B-Cubed (Biodiversity Building Blocks for policy). On Monday, the project’s coordinator Dr Quentin Groom (Meise Botanic Garden) familiarised the conference participants with the project, which aims to standardise access to biodiversity data, in order to empower policymakers to proactively address the impacts of biodiversity change.
You can find more about B-Cubed and Pensoft’s role in it in this blog post.
Dr France Gerard (UK Centre for Ecology & Hydrology) talks about the challenges in using raw data – including those provided by drones – to derive habitat condition metrics.
MAMBO: another Horizon Europe project where Pensoft has been contributing with expertise in science communication, dissemination and exploitation, was also an active participant at the event. An acronym for Modern Approaches to the Monitoring of BiOdiversity, MAMBO had its own session on Tuesday morning, where Dr Vincent Kalkman (Naturalis Biodiversity Center), Dr France Gerard (UK Centre for Ecology & Hydrology) and Prof. Toke Høye (Aarhus University) each took to the stage to demonstrate how modern technology developed within the project is to improve biodiversity and habitat monitoring. Learn more about MAMBO and Pensoft’s involvement in this blog post.
MAMBO’s project coordinator Prof. Toke T. Høye talked about smarter technologies for biodiversity monitoring, including camera traps able to count insects at a particular site.
On the event’s website you can access the MAMBO’s slides presentations by Kalkman, GerardandHøye, as presented at the EBR III conference.
***
The EBR III conference also saw a presentation – albeit remote – from Prof. Dr. Florian Leese (Dean at the University of Duisburg-Essen, Germany, and Editor-in-Chief at the Metabarcoding and Metagenomics journal), where he talked about the promise, but also the challenges for DNA-based methods to empower biodiversity monitoring.
Amongst the key tasks here, he pointed out, are the alignment of DNA-based methods with the Global Biodiversity Framework; central push and funding for standards and guidance; publication of data in portals that adhere to the best data practices and rules; and the mobilisation of existing resources such as the meteorological ones.
He also made a reference to the Forum Paper “Introducing guidelines for publishing DNA-derived occurrence data through biodiversity data platforms” by R. Henrik Nilsson et al., where the international team provided a brief rationale and an overview of guidelines targeting the principles and approaches of exposing DNA-derived occurrence data in the context of broader biodiversity data. In the study, published in the Metabarcoding and Metagenomics journal in 2022, they also introduced a living version of these guidelines, which continues to encourage feedback and interaction as new techniques and best practices emerge.
***
You can find the programme on the conference website and see highlights on the conference hashtag: #EBR2024.
Dikow, an esteemed entomologist specialising in Diptera and cybertaxonomy, is the new Editor-in-Chief of the leading scholarly journal in systematic zoology and biodiversity
Esteemed entomologist specialising in true flies (order Diptera) and cybertaxonomy, Dr Torsten Dikow was appointed as the new Editor-in-Chief of the leading open-access peer-reviewed journal in systematic zoology and biodiversity ZooKeys.
Today, Dikow is a Research Entomologist and Curator of Diptera and Aquatic Insects at the Smithsonian National Museum of Natural History (Washington, DC, USA), where his research interests encompass the diversity and evolutionary history of the superfamily Asiloidea – or asiloid flies – comprising curious insect groups, such as the assassin flies / robber flies and the mydas flies. Amongst an extensive list of research publications, Dikow’s studies on the diversity, biology, distribution and systematics of asiloid flies include the description of 60 species of assassin flies alone, and the redescription of even more through comprehensive taxonomic revisions.
During his years as a postdoc at the Field Museum (Illinois, USA), Dikow was earnestly involved in the broader activities of the Encyclopedia of Life through its Biodiversity Synthesis Center (BioSynC) and the Biodiversity Heritage Library (BHL). There, he would personally establish contacts with smaller natural history museums and scientific societies, and encourage them to grant digitisation permissions to the BHL for in-copyright scientific publications. Dikow is a champion of cybertaxonomic tools and making biodiversity data accessible from both natural history collections and publications. He has been named a Biodiversity Open Data Ambassador by the Global Biodiversity Information Facility (GBIF).
Dikow is no stranger to ZooKeys and other journals published by the open-access scientific publisher and technology provider Pensoft. For the past 10 years, he has been amongst the most active editors and a regular author and reviewer at ZooKeys, Biodiversity Data Journal and African Invertebrates.
“Publishing taxonomic revisions and species descriptions in an open-access, innovative journal to make data digitally accessible is one way we taxonomists can and need to add to the biodiversity knowledge base. ZooKeys has been a journal in support of this goal since day one. I am excited to lend my expertise and enthusiasm to further this goal and continue the development to publish foundational biodiversity research, species discoveries, and much more in the zoological field,”
ZooKeys is a peer-reviewed, open-access, rapidly disseminated journal launched to accelerate research and free information exchange in taxonomy, phylogeny, biogeography and evolution of animals. ZooKeys aims to apply the latest trends and methodologies in publishing and preservation of digital materials to meet the highest possible standards of the cybertaxonomy era.
ZooKeys publishes papers in systematic zoology containing taxonomic/faunistic data on any taxon of any geological age from any part of the world with no limit to manuscript size. To respond to the current trends in linking biodiversity information and synthesising the knowledge through technology advancements, ZooKeys also publishes papers across other taxon-based disciplines, such as ecology, molecular biology, genomics, evolutionary biology, palaeontology, behavioural science, bioinformatics, etc.
The database is a groundbreaking and pioneering initiative set to revolutionise our understanding of the rich biodiversity of Mindanao, the second-largest island group in the Philippines.
The Philippine Archipelago, with more than 7,100 islands, has one of the highest levels of endemism globally and is a hotspot for biodiversity conservation. Mindanao, the second largest group of islands in the country, is a treasure trove of terrestrial species, boasting one of the highest densities of unique flora and fauna on the planet. However, despite its ecological significance, comprehensive biodiversity records and data for the region have remained inaccessible until now.
The Mindanao Open Biodiversity Information (MOBIOS+) database aims to bridge these critical data gaps by compiling biodiversity information from the 21st century. This monumental undertaking seeks to enhance our understanding of Mindanao’s biodiversity trends, while establishing a database that is openly accessible to researchers and conservationists worldwide.
MOBIOS+ is the first of its kind and, currently, the most comprehensive attempt to create a consolidated database for the biodiversity of Mindanao based on publicly available literature. With a vast collection of biodiversity data, this database will be an invaluable resource to advance regional biodiversity research and analysis.
“It will further facilitate the identification of species and areas that require immediate conservation prioritisation and action, addressing the urgent challenges posed by our rapidly changing planet,” the researchers behind the project write in their data paper, published in the open-access, peer-reviewed Biodiversity Data Journal.
Team members of the MOBIOS+ consortium curating the dataset.
The MOBIOS+ database, available through the Global Biodiversity Information Facility (GBIF) platform, currently comprises an impressive 12,813 georeferenced specimen occurrences representing 1,907 unique taxa. These span across ten animal classes inhabiting terrestrial and freshwater environments within the Mindanao faunal region. The project aims to continuously update the species database, complementing on-ground biodiversity efforts in Mindanao.
Diversity and distribution of species occurrence records across taxonomic groups included in the first version of the MOBIOS+ database. The diversity of species (percentage, %) according to class compared to the overall number of species recorded in the MOBIOS+ database (a); and the total number of species and the number of georeferenced occurrences per animal class (b).
Associate Professor Krizler Tanalgo of the Ecology and Conservation Research Laboratory at the University of Southern Mindanao, the project leader behind MOBIOS+, shared his thoughts on this initiative, saying:
“We aim to democratise biodiversity information, making it readily available to researchers, policymakers, and conservation biologists. By doing so, we hope to facilitate well-informed decisions to address pressing environmental challenges, with a particular focus on the often underrepresented Mindanao region, which tends to receive limited attention in terms of research and funding.”
Distribution of biodiversity records across taxonomic groups from published papers.
“The MOBIOS+ database is not only a testament to the dedication of the scientific community, but also a beacon of hope for the future of biodiversity conservation in Mindanao and beyond. It will support researchers and conservationists in identifying species and areas that require immediate prioritisation and action, safeguarding the unique and fragile ecosystems of this extraordinary region.”
The Biodiversity Community Integrated Knowledge Library (BiCIKL) project, funded by the European Union Horizon 2020 Research and Innovation Action under grant agreement No 101007492, has supported the publication of this work. The work is part of a special collection supported by the project and looking to demonstrate the advantages and novel approaches in accessing and (re-)using linked biodiversity data.
Research article: Tanalgo KC, Dela Cruz KC, Agduma AR, Respicio JMV, Abdullah SS, Alvaro-Ele RJ, Hilario-Husain BA, Manampan-Rubio M, Murray SA, Casim LF, Pantog AMM, Balase SMP, Abdulkasan RMA, Aguirre CAS, Banto NL, Broncate SMM, Dimacaling AD, Fabrero GVN, Lidasan AK, Lingcob AA, Millondaga AM, Panilla KFL, Sinadjan CQM, Unte ND (2023) The MOBIOS+: A FAIR (Findable, Accessible, Interoperable and Reusable) database for Mindanao’s terrestrial biodiversity. Biodiversity Data Journal 11: e110016. https://doi.org/10.3897/BDJ.11.e110016
***
You can find all contributions published in the “Linking FAIR biodiversity data through publications: The BiCIKL approach” article collection in the open-access, peer-reviewed Biodiversity Data Journal on: https://doi.org/10.3897/bdj.coll.209.
Novel nanopublication workflows and templates for associations between organisms, taxa and their environment are the latest outcome of the collaboration between Knowledge Pixels and Pensoft.
Nanopublications complement human-created narratives of scientific knowledge with elementary, machine-actionable, simple and straightforward scientific statements that prompt sharing, finding, accessibility, citability and interoperability.
By making it easier to trace individual findings back to their origin and/or follow-up updates, nanopublications also help to better understand the provenance of scientific data.
With the nanopublication format and workflow, authors make sure that key scientific statements – the ones underpinning their research work – are efficiently communicated in both human-readable and machine-actionable mannerin line with FAIR principles. Thus, their contributions to science are better prepared for a reality driven by AI technology.
The machine-actionability of nanopublications is a standard due to each assertion comprising a subject, an object and a predicate (type of relation between the subject and the object), complemented by provenance, authorship and publication information. A unique feature here is that each of the elements is linked to an online resource, such as a controlled vocabulary, ontology or standards.
Now, what’s new?
As a result of the partnership between high-tech startup Knowledge Pixels and open-access scholarly publisher and technology provider Pensoft, authors in Biodiversity Data Journal (BDJ) can make use of three types of nanopublications:
Nanopublications associated with a manuscript submitted to BDJ. This workflow lets authors add a Nanopublications section within their manuscript while preparing their submission in the ARPHA Writing Tool (AWT). Basically, authors ‘highlight’ and ‘export’ key points from their papers as nanopublications to further ensure the FAIRness of the most important findings from their publications.
Standalone nanopublication related to any scientific publication, regardless of its author or source. This can be done via the Nanopublications page accessible from the BDJ website. The main advantage of standalone nanopublication is that straightforward scientific statements become available and FAIR early on, and remain ready to be added to a future scholarly paper.
Nanopublications as annotations to existing scientific publications. This feature is available from several journals published on the ARPHA Platform, including BDJ. By attaching an annotation to the entire paper (via the Nanopublication tab) or a text selection (by first adding an inline comment, then exporting it as a nanopublication), a reader can evaluate and record an opinion about any article using a simple template based on the Citation Typing Ontology (CiTO).
Nanopublications for biodiversity data?
At Biodiversity Data Journal (BDJ), authors can now incorporate nanopublications within their manuscripts to future-proofthe most important assertions on biological taxa and organisms or statements about associations of taxa or organisms and their environments.
On top of being shared and archived by means of a traditional research publication in an open-access peer-reviewed journal, scientific statements using the nanopublication format will also remain ‘at the fingertips’ of automated tools that may be the next to come looking for this information, while mining the Web.
Using the nanopublication workflows and templates available at BDJ, biodiversity researchers can share assertions, such as:
So far, the available biodiversity nanopublication templates cover a range of associations, including those between taxa and individual organisms, as well as between those and their environments and nucleotide sequences.
Nanopublication template customised for biodiversity research publications available from Nanodash.
As a result, those easy-to-digest ‘pixels of knowledge’ can capture and disseminate information about single observations, as well as higher taxonomic ranks.
The novel domain-specific publication format was launched as part of thecollaboration betweenKnowledge Pixels – an innovative startup tech company aiming to revolutionise scientific publishing and knowledge sharing and the open-access scholarly publisherPensoft.
Basically, a nanopublication – unlike a research article – is a tiny snippet of a precise and structured scientific finding (e.g. medication X treats disease Y), which exists as a reusable and cite-able pieces of a growing knowledge graph stored on a decentralised server network in a format that it is readable for humans, but also “understandable” and actionable for computers and their algorithms.
These semantic statements expressed in community-agreed terms, openly available through links to controlled vocabularies, ontologies and standards, are not only freely accessible to everyone in both human-readable and machine-actionable formats, but also easy-to-digest for computer algorithms and AI-powered assistants.
In short, nanopublications allow us to browse and aggregate such findings as part of a complex scientific knowledge graph. Therefore, nanopublications bring us one step closer to the next revolution in scientific publishing, which started with the emergence and increasing adoption of knowledge graphs.
“As pioneers in the semantic open access scientific publishing field for over a decade now, we at Pensoft are deeply engaged with making research work actually available at anyone’s fingertips. What once started as breaking down paywalls to research articles and adding the right hyperlinks in the right places, is time to be built upon,”
By letting computer algorithms access published research findings in a structured format, nanopublications allow for the knowledge snippets that they are intended to communicate to be fully understandable and actionable. With nanopublications, each of those fragmentsof scientific information is interconnected and traceable back to its author(s) and scientific evidence.
A nanopublication is a tiny snippet of a precise and structured scientific finding (e.g. medication X treats disease Y), which exists within a growing knowledge graph stored on a decentralised server network in a format that it is readable for humans, but also “understandable” and actionable for computers and their algorithms. Illustration by Knowledge Pixels.
By building on shared knowledge representation models, these data become Interoperable (as in the Iin FAIR), so that they can be delivered to the right user, at the right time, in the right place , ready to be reused (as per the R in FAIR) in new contexts.
Another issue nanopublications are designed to address is research scrutiny. Today, scientific publications are produced at an unprecedented rate that is unlikely to cease in the years to come, as scholarship embraces the dissemination of early research outputs, including preprints, accepted manuscripts and non-conventional papers.
A network of interlinked nanopublications could also provide a valuable forum for scientists to test, compare, complement and build on each other’s results and approaches to a common scientific problem, while retaining the record of their cooperation each step along the way.
***
We encourage you to try the nanopublications workflow yourself when submitting your next biodiversity paper to Biodiversity Data Journal.
Community feedback on this pilot project and suggestions for additional biodiversity-related nanopublication templates are very welcome!
On the journal website: https://bdj.pensoft.net/, you can find more about the unique features and workflows provided by the Biodiversity Data Journal (BDJ), including innovative research paper formats (e.g. Data Paper, OMICS Data Paper, Software Description, R Package, Species Conservation Profiles, Alien Species Profile), expert-provided data audit for each data paper submission, automated data export and more.
Don’t forget to also sign up for the BDJ newsletter via the Email alert form on the journal’s homepage and follow it on Twitter and Facebook.
Earlier this year, Knowledge Pixels and Pensoft presented several routes for readers and researchers to contribute to research outputs – either produced by themselves or by others – through nanopublications generated through and visualised in Pensoft’s cross-disciplinary Research Ideas and Outcomes (RIO) journal, which uses the same nanopublication workflows.
BKH is a one-stop portal that allows users to access FAIR and interlinked biodiversity data and services in a few clicks. BKH was designed to support a new emerging community of users over time and across the entire biodiversity research cycle providing its services to anybody, anywhere and anytime.
The Knowledge Hub is the main product from our BiCIKL consortium, and we are delighted with the result!
BKH can easily be seen as the beginning of the major shift in the way we search interlinked biodiversity information.”
Biodiversity researchers, research infrastructures and publishers interested in fields ranging from taxonomy to ecology and bioinformatics can now freely use BKH as a compass to navigate the oceans of biodiversity data. BKH will do the linkages.
says Prof. Lyubomir Penev,BiCIKL’s Project coordinator and Founder of Pensoft Publishers.
The BKH is designed to serve a new emerging community of users over time and across the entire biodiversity research cycle.
We have invested our best energies and resources in the development of BKH and the Fair Data Place (FDP), which is the beating heart of the portal,”
BKH has been designed to support a new emerging community of users across the entire biodiversity research cycle.
Its purpose goes beyond the BiCIKL project itself: we are thrilled to say that BKH is meant to stay, aiming to reshape the way biodiversity knowledge is accessed and used.
The BKH outlines how users can navigate and access the linked data, tools and services of the infrastructures cooperating in BiCIKL.
By revealing how they harvest, liberate and reuse data, these increasingly integrated sources enable researchers in the natural sciences to move more seamlessly between specimens and material samples, genomic and metagenomic data, scientific literature, and taxonomic names and units.