Titled “Otters as Bioindicators of Estuarine Health: Innovations in Monitoring and Management from Tropical Coastal Brazil,” the collection celebrates nearly four decades of pioneering otter conservation and estuarine stewardship in Brazil, while advancing global knowledge on sustainable coastal ecosystem management.
Since 1986, Projeto Lontra has stood at the forefront of tropical otter conservation, ecological monitoring, and community engagement. Over the years, its research has provided unprecedented insights into the health of estuarine and coastal ecosystems—making otters not only charismatic species of interest, but powerful sentinels of environmental change.
“2026 will mark the 40th anniversary of Projeto Lontra. This partnership represents a rare convergence of long-term field knowledge, cutting-edge methodology, and global outreach—precisely the kind of collaboration needed to scale impact in applied estuarine conservation.”
From hydrodynamic assessments and habitat connectivity studies to long-term behavioral monitoring, Projeto Lontra has generated one of the most extensive otter-focused datasets in the Western Atlantic.
EMT Editor-in-Chief Dr. Soufiane Haddout highlights the significance of this collaborative milestone:
“Otters aren’t just icons of biodiversity—they’re active barometers of estuarine resilience. Partnering with Instituto Ekko Brasil allows us to amplify voices from the Global South, transforming local stewardship into global action. This is more than a collection; it’s a call to reimagine how we protect our coasts through otter-inspired innovation.”
The new collection directly supports EMT’s mission to strengthen the exchange of applied research, technology, and management strategies that support the long-term sustainability of estuarine ecosystems worldwide.
All contributions to the Topical Collection come from the Projeto Lontra team and invited collaborators who have worked closely with the project over the years. The resulting series of articles will showcase the unparalleled long-term dataset built since 1986 and demonstrate how otters serve as powerful sentinels of estuarine and coastal health.
Guest Editors
Projeto Lontra – Instituto Ekko Brasil
Dr Oldemar Carvalho Junior– Coordinator, Projeto Lontra & Institutional Director, Instituto Ekko Brasil, Florianópolis, Brazil
Ms Alessandra Bez Birolo – Coordinator of Social Mobilization and Public Policies, Founding Partner, Instituto Ekko Brasil; Environmental Education Coordinator, Projeto Lontra, Brazil
Mr Marcelo Tosatti – President, Instituto Ekko Brasil; Field Researcher (20+ years), Projeto Lontra, Brazil
EMT Editorial Board
Dr Soufiane Haddout – Editor-in-Chief, Estuarine Management and Technologies, Ibn Tofail University, Morocco
Dr P.R. Jayachandran – King Fahd University of Petroleum and Minerals, Saudi Arabia
The partnership between EMT and Projeto Lontra embodies a powerful message: long-term conservation succeeds when knowledge, people, and technology work together.
By elevating nearly 40 years of Brazilian conservation leadership to global research audiences, this Topical Collection aims to inspire new partnerships, operational tools, and policy actions that safeguard estuarine ecosystems for future generations.
by Mariya Dimitrova, Jorrit Poelen, Georgi Zhelezov, Teodor Georgiev, Lyubomir Penev
Fig. 1. Pensoft-GloBI workflow for indexing biotic interactions from scholarly literature
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species, etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 2 in Fig. 1).. We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as json to a GitHub repository, from where they could be accessed by GloBI.
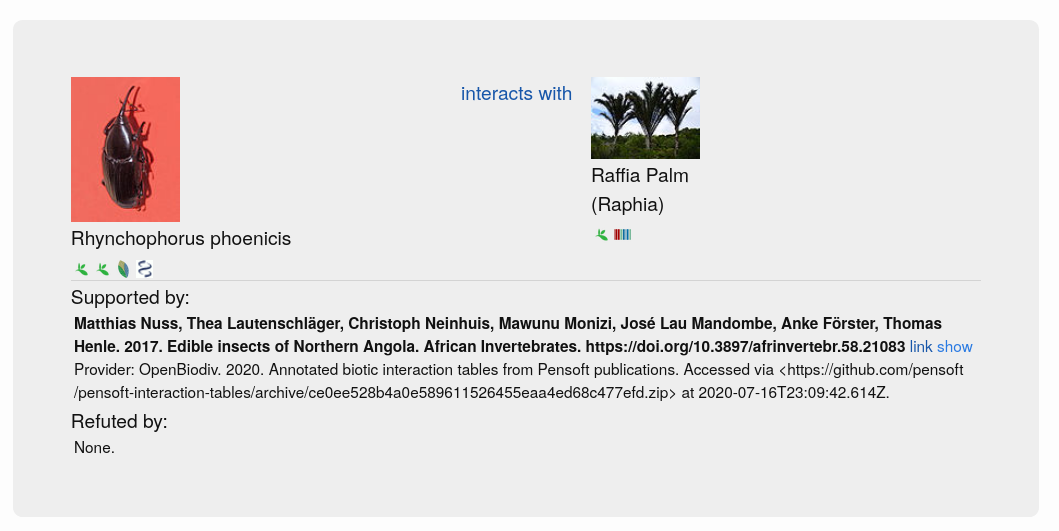
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ (Fig. 2) because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
Fig. 2. Example of a biotic interaction indexed by GloBI.
Examples of species interactions provided by OpenBiodiv and indexed by GloBI are available on GloBI’s website.
In the future we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6,993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 1 in Fig. 1). We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as JSON to a GitHub repository, from where they could be accessed by GloBI.
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
In the future, we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
References
Jorrit H. Poelen, James D. Simons and Chris J. Mungall. (2014). Global Biotic Interactions: An open infrastructure to share and analyze species-interaction datasets. Ecological Informatics. https://doi.org/10.1016/j.ecoinf.2014.08.005.
Additional Information
The work has been partially supported by the International Training Network (ITN) IGNITE funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 764840.