Pensoft is among the first signatories dedicated to fully leveraging biodiversity knowledge from research publications within an open science framework by 2035
Some of the world’s leading institutions, experts and scientific infrastructures relating to biodiversity information are uniting around a new 10-year roadmap to ‘liberate’ data presently trapped in research publications.
The initiative aims to enable the creation of a ‘Libroscope’ – a mechanism for unlocking and linking data from scientific literature to support understanding of biodiversity, as the microscope and telescope previously revolutionized science. The plan largely builds on existing technology and workflows, and does not rely on construction of a new technical infrastructure.
The proposals result from a symposium involving 51 experts from 10 countries held in August 2024 at the 7th-century monastery at Disentis in the Swiss Alps, supported financially by the Arcadia Fund. The symposium was a 10-year follow-up to the 2014 meeting at Meise Botanic Garden in Belgium, which led to the Bouchout Declaration on open biodiversity knowledge management. The Disentis meeting evaluated progress since then, and identified priorities for the decade ahead.
Group photo from the Disentis meeting (Switzerland, August 2024).
While acknowledging major advances in the sharing and use of open biodiversity data, the participants noted that accessing data within research publications is often very cumbersome, with databases disconnected from each other and from the source literature. Liberating and linking data from such publications – estimated to encompass more than 500 million total pages – would represent a compelling mission for the next decade.
A roadmap for staged action over the next decade was agreed by the symposium participants, with the following vision: “By 2035, the power of biodiversity knowledge from research publications will be fully leveraged within an open science framework, including unencumbered data discovery, access, and re-use across scientific disciplines and policy applications.”
The ‘Disentis Roadmap’, further developed following the symposium, and now released publicly, has already been signed by 26 institutions and a further 46 individual experts on five continents – among them major natural history collections such as Meise Botanic Garden, Botanic Garden and Botanical Museum Berlin, the National Museum of Natural History in Paris, and Royal Botanic Gardens, Kew; infrastructures such as the Global Biodiversity Information Facility (GBIF), Biodiversity Heritage Library (BHL), Catalogue of Life, LifeWatch ERIC and the Swiss Institute of Bioinformatics (SIB); journal publishers such as Pensoft Publishers and the European Journal of Taxonomy; research institutions such as Chinese Academy of Sciences and the Senckenberg Society for Nature Research; and networks such as TDWG Biodiversity Information Standards and Consortium of European Taxonomic Facilities (CETAF). See the full list of signatories here.
The roadmap remains open for further signatures, ahead of the launch of an action plan at the Living Data conference in Bogotá, Colombia in October 2025. The original signatories hope that a much broader group of institutions and individuals, across global regions and disciplines, will join the initiative and help to shape implementation of its vision. Engagement of funders will also be critical to realize its objectives.
The specific goals of the roadmap are that by 2035:
All major public biodiversity research funders and academic publishers will encourage and enable publication of data adhering to the FAIR principles (findable, accessible, interoperable and reusable);
Biodiversity-focussed publications will be accessible in machine-actionable formats, with all non-copyrightable parts of articles flowing into public data repositories;
Published research on biodiversity will be ‘fully AI-ready’, that is openly available for AI training and properly labelled for ingestion by machine-learning modelled, within appropriate ethical and legal frameworks;
Dedicated funding from research and infrastructure grants will be reserved for ensuring access to biodiversity data and knowledge.
“We finally have a chance to make a quantum leap in understanding and monitoring biodiversity, by leveraging the power of digital technologies, and combining modern genomic methods with the vast amount of research data published daily and currently stuck in the publication prison. The ‘Libroscope’ will help to explore the universe of existing knowledge, accumulated over hundreds of years, and bring it to the forefront of developments in the digital age, helping nature and people across the globe.”
commented Donat Agosti of the Swiss organization Plazi, who convened the Disentis symposium.
A recent demonstration of the principles of the ‘Libroscope’ was the launch of data portals for the European Journal of Taxonomy (EJT) and the Biodiversity Data Journal, as part of the GBIF hosted portal programme. The new portals showcase the data contained within taxonomic literature published by the journals, making use of the workflow originally developed by Plazi and partners to extract re-usable data from articles traditionally locked in static PDF files. Once created, these data objects then flow into platforms such as GBIF, Catalogue of Life, ChecklistBank and the BiodiversityPMC, and are stored in the Biodiversity Literature Repository at Zenodo hosted by CERN. This process enables data on new species and the location of related specimens cited in the literature to be openly accessible in near-real time, and available for long-term access.
The newly launched Biodiversity Data Journal data portal is part of the GBIF-hosted portal programme. It showcase the data contained within taxonomic literature published by the journal.
“As a publisher of dozens of renowned academic journals in the field of biodiversity and systematics with experience in technology development, at Pensoft, we have always recognised the key role of academic publishers in scholarly communication. It’s not only about publishing the latest research. Above all, it’s about putting scientific work in the hands of those who need it: be it future researchers, policy-makers or their AI-powered assistants. Now that the Disentis roadmap is already a fact, we hope that many others will also join us on this ambitious journey to open up the knowledge we have today for those who will need it tomorrow.”
said Prof. Dr. Lyubomir Penev, founder and CEO at Pensoft, who attended the Disentis symposium.
“By repositioning scientific publications as an essential part of the research cycle, the Disentis Roadmap encourages publishers and the scientific community to move beyond open access towards FAIR access. Proactively ensuring data quality and dissemination is the core mission of the European Journal of Taxonomy. In this way, EJT enhances the immediate discoverability and usability of the taxonomic information it publishes, making it more valuable to the scientific community as a whole. Adherence to the Disentis vision marks a crucial step in the liberation and enrichment of knowledge about biodiversity.”
said Laurence Bénichou, founder and liaison officer of the European Journal of Taxonomy.
The Chief Executive Officer of Meise Botanic Garden, Steven Dessein, who attended the Disentis Symposium, commented:
“Meise Botanic Garden fully supports the Disentis Roadmap, which builds on the foundation laid by the Bouchout Declaration. Open biodiversity data is essential to tackling today’s pressing environmental challenges, from biodiversity loss to climate change. By ensuring research publications become more accessible and interconnected, this roadmap represents a critical step toward harnessing biodiversity knowledge for science, policy, and conservation.”
Christophe Déssimoz, Executive Director of the SIB Swiss Institute of Bioinformatics, another signatory of the Disentis Roadmap, added:
“We have long championed the principles of open, structured, and interoperable data to advance life sciences. The Disentis Roadmap applies these same principles to biodiversity knowledge, ensuring that critical data is not just available, but truly actionable for research, policy, and conservation.”
The director of the Botanic Garden and Botanical Museum of Berlin, Thomas Borsch, noted that more than any other branch of science, taxonomic research depended on the machine-actionable availability of biodiversity data from the literature:
“The ‘Libroscope’ postulated in the Disentis Roadmap will enable a new generation of research workflows through its interoperable approach,” said Professor Borsch. “This will be very helpful to address pressing issues in biodiversity research and in particular to improve the use of quality information on organisms in national and global assessments.”
The chief scientist of the national museum of natural history in Paris (MNHN) said:
“We, like all similar museums and taxonomic institutions, are focussed on linking taxonomic and collection data with digital reproductions and molecular information to create the ‘extended digital specimen.’ However, the potential of taxonomic publications and text mining should not be underestimated either. On the contrary, it is a smart and accessible way to dig into scientific publications so as to retrieve, link and consolidate, research data of great relevance to many disciplines. This is why our institution fully supports the Disentis initiative.”
Christos Arvanitidis, CEO of the Biodiversity and Ecosystem e-Science Infrastructure LifeWatch ERIC, commented:
“LifeWatch ERIC is proud to be part of this initiative, as providing access and support to biodiversity and ecosystem data is fully aligned with our mission. The Disentis Roadmap opens up new opportunities for our research infrastructure to help make what science has provided us accessible and usable, and to improve the FAIRness of data for research and science-based policy.”
Tim Robertson, deputy director and head of informatics at the Global Biodiversity Information Facility (GBIF), who also attended the Disentis meeting added:
“We’re excited to see the results from Disentis partners like Plazi, BHL, Pensoft and the European Journal of Taxonomy who are focussed on liberating data connected with scientific publications,” said . “GBIF will continue to do our part to improve the standards, tools and services that help expand both the benefits and the impact of FAIR and open data on biodiversity science and policy.”
Olaf Bánki, Executive Director of the Catalogue of Life, commented:
“We call out to the scientific community, especially the younger generation, to join our effort in unlocking biodiversity data from literature. Actionable biodiversity and taxonomic data from digitized literature contributes to creating an index of all described organisms of all life on earth. We need such data to tackle and understand the current biodiversity crisis.”
Within theBiodiversity Community Integrated Knowledge Library (BiCIKL) project, 14 European institutions from ten countries, spent the last three years elaborating on services and high-tech digital tools, in order to improve the findability, accessibility, interoperability and reusability (FAIR-ness) of various types of data about the world’s biodiversity. These types of data include peer-reviewed scientific literature, occurrence records, natural history collections, DNA data and more.
By ensuring all those data are readily available and efficiently interlinked to each other, the project consortium’s intention is to provide better tools to the scientific community, so that it can more rapidly and effectively study, assess, monitor and preserve Earth’s biological diversity in line with the objectives of the likes of the EU Biodiversity Strategy for 2030 and the European Green Deal. Their targets require openly available, precise and harmonised data to underpin the design of effective measures for restoration and conservation, reminds the BiCIKL consortium.
Since 2021, the project partners at BiCIKL have been working together to elaborate existing workflows and links, as well as create brand new ones, so that their data resources, platforms and tools can seamlessly communicate with each other, thereby taking the burden off the shoulders of scientists and letting them focus on their actual mission: paving the way to healthy and sustainable ecosystems across Europe and beyond.
Now that the three-year project is officially over, the wider scientific community is yet to reap the fruits of the consortium’s efforts. In fact, the end of the BiCIKL project marks the actual beginning of a European- and global-wide revolution in the way biodiversity scientists access, use and produce data. It is time for the research community, as well as all actors involved in the study of biodiversity and the implementation of regulations necessary to protect and preserve it, to embrace the lessons learned, adopt the good practices identified and build on the knowledge in existence.
This is why amongst the BiCIKL’s major final research outputs, there are two Policy Briefs meant to summarise and highlight important recommendations addressed to key policy makers, research institutions and funders of research. After all, it is the regulatory bodies that are best equipped to share and implement best practices and guidelines.
Most recently, the BiCIKL consortium published two particularly important policy briefs, both addressed to the likes of the European Commission’s Directorate-General for Environment; the European Environment Agency; the Joint Research Centre; as well as science and policy interface platforms, such as the EU Biodiversity Platform; and also organisations and programmes, e.g. Biodiversa+ and EuropaBON, which are engaged in biodiversity monitoring, protection and restoration. The policy briefs are also to be of particular use to national research funds in the European Union.
One of the newly published policy briefs, titled “Uniting FAIR data through interlinked, machine-actionable infrastructures”, highlights the potential benefits derived from enhanced connectivity and interoperability among various types of biodiversity data. The publication includes a list of recommendations addressed to policy-makers, as well as nine key action points. Understandably, amongst the main themes are those of wider international cooperation; inclusivity and collaboration at scale; standardisation and bringing science and policy closer to industry. Another major outcome of the BiCIKL project: the Biodiversity Knowledge Hub portal is noted as central to many of these objectives and tasks in its role of a knowledge broker that will continue to be maintained and updated with additional FAIR data-compliant services as a living legacy of the collaborative efforts at BiCIKL.
The second policy brief, titled “Liberate the power of biodiversity literature as FAIR digital objects”, shares key actions that can liberate data published in non-machine actionable formats and non-interoperable platforms, so that those data can also be efficiently accessed and used; as well as ways to publish future data according to the best FAIR and linked data practices. The recommendations highlighted in the policy brief intend to support decision-making in Europe; expedite research by making biodiversity data immediately and globally accessible; provide curated data ready to use by AI applications; and bridge gaps in the life cycle of research data through digital-born data. Several new and innovative workflows, linkages and integrative mechanisms and services developed within BiCIKL are mentioned as key advancements created to access and disseminate data available from scientific literature.
While all policy briefs and factsheets – both primarily targeted at non-expert decision-makers who play a central role in biodiversity research and conservation efforts – are openly and freely available on the project’s website, the most important contributions were published as permanent scientific records in a BiCIKL-branded dedicated collection in the peer-reviewed open-science journal Research Ideas and Outcomes (RIO). There, the policy briefs are provided as both a ready-to-print document (available as supplementary material) and an extensive academic publication.
Currently, the collection: “Towards interlinked FAIR biodiversity knowledge: The BiCIKL perspective” in the RIO journal contains 60 publications, including policy briefs, project reports, methods papers, conference abstracts, demonstrating and highlighting key milestones and project outcomes from along the BiCIKL’s journey in the last three years. The collection also features over 15 scientific publications authored by people not necessarily involved in BiCIKL, but whose research uses linked open data and tools created in BiCIKL. Their publications were published in a dedicated article collection in the Biodiversity Data Journal.
“Not only does it mean that content is persistent in merit and quality, but that innovative research outputs are already appreciated within academia,” says Editor-in-Chief Prof Dr Benjamin Burkhard
Seven years after its official launch in May 2016, the One Ecosystem journal has successfully completed the rigorous quality and integrity assessment at Web of Science.
The news means that One Ecosystem might see its very first Journal Impact Factor (JIF) as early as 2024, following the latest revision of the metric’s policies Clarivate announced last July. According to the update, all journals from the Web of Science Core Collection are now featured in the Journal Citation Reports, and thereby eligible for a JIF.
“Giving all quality journals a Journal Impact Factor will provide full transparency to articles and citations that have contributed to impact, and therefore will help them demonstrate their value to the research community. This decision is aligned to our position that publications in all quality journals, not just highly cited journals, should be eligible for inclusion in research assessment exercises,” said back then Dr Nandita Quaderi, Editor-in-Chief and Editorial Vice President at Web of Science.
“We are happy to learn that Web of Science has recognised the value and integrity of One Ecosystem in the scholarly landscape. Not only does it mean that the scientific content One Ecosystem has been publishing over the years is persistent in merit and quality, but that innovative research outputs are already widely accepted and appreciated within academia.
After all, one of the reasons why we launched One Ecosystem and why it has grown to be particularly distinguished in the field of ecology and sustainability is that it provides a scholarly publication venue for traditional research papers, as well as ‘unconventional’ scientific contributions,”
“These ‘unconventional’ research outputs – like software descriptions, ecosystem inventories, ecosystem service mappings and monitoring schema – do not normally see the light of day, let alone the formal publication and efficient visibility. We believe that these outputs can be very useful to researchers, as well as practitioners and public bodies in charge of, for example, setting up indicator frameworks for environmental reporting,”
“In fact, last year, we also launched a new article type: the Ecosystem Accounting table, which follows the standards set by the the System of Environmental-Economic Accounting Ecosystem Accounting (SEEA EA). This publication type provides scientists and statisticians with a platform to publish newly compiled accounting tables,”
Previously, One Ecosystem has been accepted for indexing at over 60 major academic databases, including Scopus, DOAJ, Cabell’s Directory, CABI and ERIH PLUS. In June 2022, the journal received a Scopus CiteScore reading 7.0, which placed it in Q1 in five categories: Earth and Planetary Sciences; Ecology; Nature and Landscape Conservation; Agricultural and Biological Sciences (miscellaneous); Ecology, Evolution, Behavior and Systematics.
Welcomed are taxonomic and other biodiversity-related research articles, which demonstrate the advantages and novel approaches in accessing and (re-)using linked biodiversity data
The EU-funded project BiCIKL (Biodiversity Community Integrated Knowledge Library) will support free of charge publications*submitted to the dedicated topical collection: “Linking FAIR biodiversity data through publications: The BiCIKL approach” in the Biodiversity Data Journal, demonstrating advanced publishing methods of linked biodiversity data, so that they can be easily harvested, distributed and re-used to generate new knowledge.
BiCIKL is dedicated to building a new community of key research infrastructures, researchers and citizen scientists by using linked FAIR biodiversity data at all stages of the research lifecycle, from specimens through sequencing, imaging, identification of taxa, etc. to final publication in novel, re-usable, human-readable and machine-interpretable scholarly articles.
Achieving a culture change in how biodiversity data are being identified, linked, integrated and re-used is the mission of the BiCIKL consortium. By doing so, BiCIKL is to help increase the transparency, trustworthiness and efficiency of the entire research ecosystem.
The new article collection welcomes taxonomic and other biodiversity-related research articles, data papers, software descriptions,and methodological/theoretical papers. These should demonstrate the advantages and novel approaches in accessing and (re-)using linked biodiversity data.
To be eligible for the collection, a manuscript must comply with at least two of the conditions listed below. In the submission form, the author needs tospecify the condition(s) applicable to the manuscript. The author should provide the explanation in a cover letter, using the Notes to the editor field.
All submissions must abide by the community-agreed standards for terms, ontologies and vocabularies used in biodiversity informatics.
Conditions for publication in the article collection:
The authors are expected to use explicit Globally Unique Persistent and Resolvable Identifiers (GUPRI) or other persistent identifiers (PIDs), where such are available, for the different types of data they use and/or cite in the manuscripts (specimens IDs, sequence accession numbers, taxon name and taxon treatment IDs, image IDs, etc.)
Global taxon reviews in the form of “cyber-catalogues” are welcome if they contain links of the key data elements (specimens, sequences, taxon treatments, images, literature references, etc.) to their respective records in external repositories. Taxon names in the text should not be hyperlinked. Instead, under each taxon name in the catalogue, the authors should add external links to, for example, Catalogue of Life, nomenclators (e.g. IPNI, MycoBank, Index Fungorum, ZooBank), taxon treatments in Plazi’s TreatmentBank or other relevant trusted resources.
Taxonomic papers (e.g. descriptions of new species or revisions) must contain persistent identifiers for the holotype, paratypes and at least most of the specimens used in the study.
Specimen records that are used for new taxon descriptions or taxonomic revisions and are associated with a particular Barcode Identification Number (BIN) or Species Hypothesis (SH) should be imported directly from BOLD or PlutoF, respectively, via the ARPHA Writing Tool data-import plugin.
More generally, individual specimen records used for various purposes in taxonomic descriptions and inventories should be imported directly into the manuscript from GBIF, iDigBio, or BOLD via the ARPHA Writing Tool data-import plugin.
In-text citations of taxon treatments from Plazi’s TreatmentBank are highly welcome in any taxonomic revision or catalogue. The in-text citations should be hyperlinked to the original treatment data at TreatmentBank.
Hyperlinking other terms of importance in the article text to their original external data sources or external vocabularies is encouraged.
Tables that list gene accession numbers, specimens and taxon names, should conform to the Biodiversity Data Journal’s linked data tables guidelines.
Theoretical or methodological papers on linking FAIR biodiversity data are eligible for the BiCIKL collection if they provide real examples and use cases.
Data papers or software descriptions are eligible if they use linked data from the BiCIKL’s partnering research infrastructures, or describe tools and services that facilitate access to and linking between FAIR biodiversity data.
Articles that contain nanopublications created or added during the authoring process in Biodiversity Data Journal. A nanopublication is a scientifically meaningful assertion about anything that can be uniquely identified and attributed to its author and serve to communicate a single statement, for example biotic relationship between taxa, or habitat preference of a taxon. The in-built workflow ensures the linkage and its persistence, while the information is simultaneously human-readable and machine-interpretable.
Manuscripts that contain or describe any other novel idea or feature related to linked or semantically enhanced biodiversity data will be considered too.
We recommend authors to get acquainted with these two papers before they decide to submit a manuscript to the collection:
Here are several examples of research questions that might be explored using semantically enriched and linked biodiversity data:
(1) How does linking taxon names or Operational Taxonomic Units (OTUs) to related external data (e.g. specimen records, sequences, distributions, ecological & bionomic traits, images) contribute to a better understanding of the functions and regional/local processes within faunas/floras/mycotas or biotic communities?
(2) How could the production and publication of taxon descriptions and inventories – including those based mostly on genomic and barcoding data – be streamlined?
(3) How could general conclusions, assertions and citations in biodiversity articles be expressed in formal, machine-actionable language, either to update prior work or express new facts (e.g. via nanopublications)?
(4) How could research data and narratives be re-used to support more extensive and data-rich studies?
(5) Are there other taxon- or topic-specific research questions that would benefit from richer, semantically enhanced FAIR biodiversity data?
Once published, specimen records data are being exported in Darwin Core Archive to GBIF.
The data and taxon treatments are also exported to several additional data aggregators, such as TreatmentBank, the Biodiversity Literature Repository, and SiBILS amongst others. The full-text articles are also converted to Linked Open Data indexed in the OpenBiodiv Knowledge Graph.
All articles will need to acknowledge the BiCIKL project, Grant No 101007492 in the Acknowledgements section.
* The publication fee (APC) is waived for standard-sized manuscripts (up to 40,000 characters, including spaces) normally charged by BDJ at € 650. Authors of larger manuscripts will need to cover the surplus charge (€10 for each 1,000 characters above 40,000). See more about the APC policy at Biodiversity Data Journal, or contact the journal editorial team at: bdj@pensoft.net.
Follow the BiCIKL Project on Twitter and Facebook.Join the conservation on via #BiCIKL_H2020.
You can also follow Biodiversity Data Journal on Twitter and Facebook.
Proofreading the text of scientific papers isn’t hard, although it can be tedious. Are all the words spelled correctly? Is all the punctuation correct and in the right place? Is the writing clear and concise, with correct grammar? Are all the cited references listed in the References section, and vice-versa? Are the figure and table citations correct?
Proofreading of text is usually done first by the reviewers, and then finished by the editors and copy editors employed by scientific publishers. A similar kind of proofreading is also done with the small tables of data found in scientific papers, mainly by reviewers familiar with the management and analysis of the data concerned.
But what about proofreading the big volumes of data that are common in biodiversity informatics? Tables with tens or hundreds of thousands of rows and dozens of columns? Who does the proofreading?
Sadly, the answer is usually “No one”. Proofreading large amounts of data isn’t easy and requires special skills and digital tools. The people who compile biodiversity data often lack the skills, the software or the time to properly check what they’ve compiled.
The result is that a great deal of the data made available through biodiversity projects like GBIF is — to be charitable — “messy”. Biodiversity data often needs a lot of patient cleaning by end-users before it’s ready for analysis. To assist end-users, GBIF and other aggregators attach “flags” to each record in the database where an automated check has found a problem. These checks find the most obvious problems amongst the many possible data compilation errors. End-users often have much more work to do after the flags have been dealt with.
In 2017, Pensoft employed a data specialist to proofread the online datasets that are referenced in manuscripts submitted to Pensoft’s journals as data papers. The results of the data-checking are sent to the data paper’s authors, who then edit the datasets. This process has substantially improved many datasets (including those already made available through GBIF) and made them more suitable for digital re-use. At blog publication time, more than 200 datasets have been checked in this way.
Note that a Pensoft data audit does not check the accuracy of the data, for example, whether the authority for a species name is correct, or whether the latitude/longitude for a collecting locality agrees with the verbal description of that locality. For a more or less complete list of what does get checked, see the Data checklist at the bottom of this blog post. These checks are aimed at ensuring that datasets are correctly organised, consistently formatted and easy to move from one digital application to another. The next reader of a digital dataset is likely to be a computer program, not a human. It is essential that the data are structured and formatted, so that they are easily processed by that program and by other programs in the pipeline between the data compiler and the next human user of the data.
Pensoft’s data-checking workflow was previously offered only to authors of data paper manuscripts. It is now available to data compilers generally, with three levels of service:
Basic: the compiler gets a detailed report on what needs fixing
Standard: minor problems are fixed in the dataset and reported
Premium: all detected problems are fixed in collaboration with the data compiler and a report is provided
Because datasets vary so much in size and content, it is not possible to set a price in advance for basic, standard and premium data-checking. To get a quote for a dataset, send an email with a small sample of the data topublishing@pensoft.net.
—
Data checklist
Minor problems:
dataset not UTF-8 encoded
blank or broken records
characters other than letters, numbers, punctuation and plain whitespace
more than one version (the simplest or most correct one) for each character
unnecessary whitespace
Windows carriage returns (retained if required)
encoding errors (e.g. “Dum?ril” instead of “Duméril”)
missing data with a variety of representations (blank, “-“, “NA”, “?” etc)
Major problems:
unintended shifts of data items between fields
incorrect or inconsistent formatting of data items (e.g. dates)
different representations of the same data item (pseudo-duplication)
for Darwin Core datasets, incorrect use of Darwin Core fields
data items that are invalid or inappropriate for a field
data items that should be split between fields
data items referring to unexplained entities (e.g. “habitat is type A”)
truncated data items
disagreements between fields within a record
missing, but expected, data items
incorrectly associated data items (e.g. two country codes for the same country)
duplicate records, or partial duplicate records where not needed
For details of the methods used, see the author’s online resources:
by Mariya Dimitrova, Jorrit Poelen, Georgi Zhelezov, Teodor Georgiev, Lyubomir Penev
Fig. 1. Pensoft-GloBI workflow for indexing biotic interactions from scholarly literature
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species, etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 2 in Fig. 1).. We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as json to a GitHub repository, from where they could be accessed by GloBI.
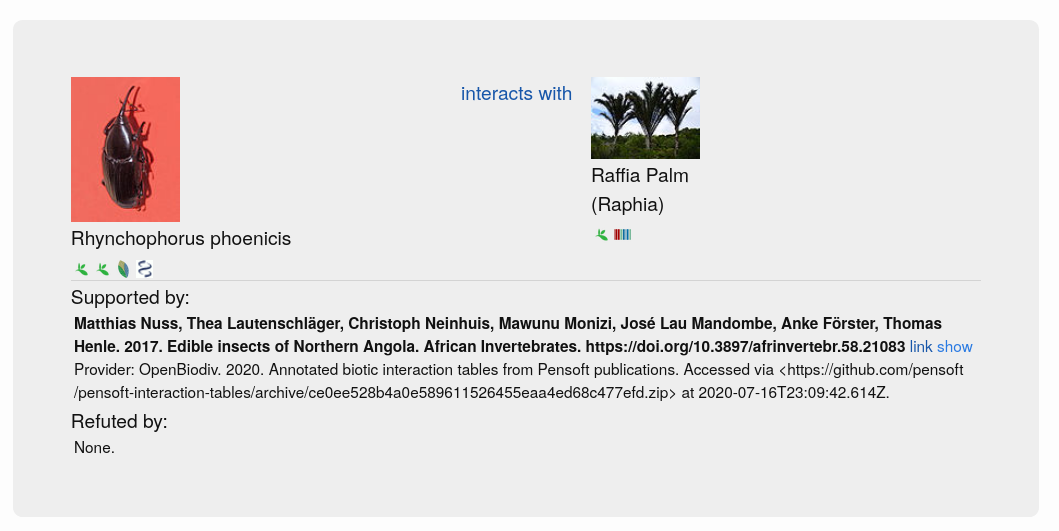
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ (Fig. 2) because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
Fig. 2. Example of a biotic interaction indexed by GloBI.
Examples of species interactions provided by OpenBiodiv and indexed by GloBI are available on GloBI’s website.
In the future we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6,993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 1 in Fig. 1). We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as JSON to a GitHub repository, from where they could be accessed by GloBI.
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
In the future, we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
References
Jorrit H. Poelen, James D. Simons and Chris J. Mungall. (2014). Global Biotic Interactions: An open infrastructure to share and analyze species-interaction datasets. Ecological Informatics. https://doi.org/10.1016/j.ecoinf.2014.08.005.
Additional Information
The work has been partially supported by the International Training Network (ITN) IGNITE funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 764840.
A colony of what is apparently a new species of the genus Hipposideros found in an abandoned gold mine in Western Kenya Photo by B. D. Patterson / Field Museum
Newly published findings about the phylogenetics and systematics of some previously known, but also other yet to be identified species of Old World Leaf-nosed bats, provide the first contribution to a recently launched collection of research articles, whose task is to help scientists from across disciplines to better understand potential hosts and vectors of zoonotic diseases, such as the Coronavirus. Bats and pangolins are among the animals already identified to be particularly potent vehicles of life-threatening viruses, including the infamous SARS-CoV-2.
The article, publicly available in the peer-reviewed scholarly journal ZooKeys, also pilots a new generation of Linked Open Data (LOD) publishing practices, invented and implemented to facilitate ongoing scientific collaborations in times of urgency like those we experience today with the COVID-19 pandemic currently ravaging across over 230 countries around the globe.
In their study, an international team of scientists, led by Dr Bruce Patterson, Field Museum‘s MacArthur curator of mammals, point to the existence of numerous, yet to be described species of leaf-nosed bats inhabiting the biodiversity hotspots of East Africa and Southeast Asia. In order to expedite future discoveries about the identity, biology and ecology of those bats, they provide key insights into the genetics and relations within their higher groupings, as well as further information about their geographic distribution.
“Leaf-nosed bats carry coronaviruses–not the strain that’s affecting humans right now, but this is certainly not the last time a virus will be transmitted from a wild mammal to humans. If we have better knowledge of what these bats are, we’ll be better prepared if that happens,”
says Dr Terrence Demos, a post-doctoral researcher in Patterson’s lab and a principal author of the paper.
One of the possibly three new to science bat species, previously referred to as Hipposideros caffer or Sundevall’s leaf-nosed bat Photo by B. D. Patterson / Field Museum
“With COVID-19, we have a virus that’s running amok in the human population. It originated in a horseshoe bat in China. There are 25 or 30 species of horseshoe bats in China, and no one can determine which one was involved. We owe it to ourselves to learn more about them and their relatives,”
comments Patterson.
In order to ensure that scientists from across disciplines, including biologists, but also virologists and epidemiologists, in addition to health and policy officials and decision-makers have the scientific data and evidence at hand, Patterson and his team supplemented their research publication with a particularly valuable appendix table. There, in a conveniently organized table format, everyone can access fundamental raw genetic data about each studied specimen, as well as its precise identification, origin and the natural history collection it is preserved. However, what makes those data particularly useful for researchers looking to make ground-breaking and potentially life-saving discoveries is that all that information is linked to other types of data stored at various databases and repositories contributed by scientists from anywhere in the world.
Furthermore, in this case, those linked and publicly available data or Linked Open Data (LOD) are published in specific code languages, so that they are “understandable” for computers. Thus, when a researcher seeks to access data associated with a particular specimen he/she finds in the table, he/she can immediately access additional data stored at external data repositories by means of a single algorithm. Alternatively, another researcher might want to retrieve all pathogens extracted from tissues from specimens of a specific animal species or from particular populations inhabiting a certain geographical range and so on.
###
The data publication and dissemination approach piloted in this new study was elaborated by the science publisher and technology provider Pensoft and the digitisation company Plazi for the purposes of a special collection of research papers reporting on novel findings concerning the biology of bats and pangolins in the scholarly journal ZooKeys. By targeting the two most likely ‘culprits’ at the roots of the Coronavirus outbreak in 2020: bats and pangolins, the article collection aligns with the agenda of the COVID-19 Joint Task Force, a recent call for contributions made by the Consortium of European Taxonomic Facilities (CETAF), the Distributed System for Scientific Collections (DiSSCo) and the Integrated Digitized Biocollections (iDigBio).
###
Original source:
Patterson BD, Webala PW, Lavery TH, Agwanda BR, Goodman SM, Kerbis Peterhans JC, Demos TC (2020) Evolutionary relationships and population genetics of the Afrotropical leaf-nosed bats (Chiroptera, Hipposideridae). ZooKeys 929: 117-161. https://doi.org/10.3897/zookeys.929.50240
At a time when a million species are at risk of extinction, according to a recent UN report, ironically, we don’t know how many species there are on Earth, nor have we noted down all those that we have come to know on a single list. In fact, we don’t even know how many species we would have put on such a list.
The combined research including over 2,000 natural history institutions worldwide, produced an estimated ~500 million pages of scholarly publications and tens of millions of illustrations and species descriptions, comprising all we currently know about the diversity of life. However, most of it isn’t digitally accessible. Even if it were digital, our current publishing systems wouldn’t be able to keep up, given that there are about 50 species described as new to science every day, with all of these published in plain text and PDF format, where the data cannot be mined by machines, thereby requiring a human to extract them. Furthermore, those publications would often appear in subscription (closed access) journals.
The Biodiversity Literature Repository (BLR), a joint project ofPlazi, Pensoft and Zenodo at CERN, takes on the challenge to open up the access to the data trapped in scientific publications, and find out how many species we know so far, what are their most important characteristics (also referred to as descriptions or taxonomic treatments), and how they look on various images. To do so, BLR uses highly standardised formats and terminology, typical for scientific publications, to discover and extract data from text written primarily for human consumption.
By relying on state-of-the-art data mining algorithms, BLR allows for the detection, extraction and enrichment of data, including DNA sequences, specimen collecting data or related descriptions, as well as providing implicit links to their sources: collections, repositories etc. As a result, BLR is the world’s largest public domain database of taxonomic treatments, images and associated original publications.
Once the data are available, they are immediately distributed to global biodiversity platforms, such as GBIF–the Global Biodiversity Information Facility. As of now, there are about 42,000 species, whose original scientific descriptions are only accessible because of BLR.
The very basic principle in science to cite previous information allows us to trace back the history of a particular species, to understand how the knowledge about it grew over time, and even whether and how its name has changed through the years. As a result, this service is one avenue to uncover the catalogue of life by means of simple lookups.
So far, the lessons learned have led to the development of TaxPub, an extension of the United States National Library of Medicine Journal Tag Suite and its application in a new class of 26 scientific journals. As a result, the data associated with articles in these journals are machine-accessible from the beginning of the publishing process. Thus, as soon as the paper comes out, the data are automatically added to GBIF.
While BLR is expected to open up millions of scientific illustrations and descriptions, the system is unique in that it makes all the extracted data findable, accessible, interoperable and reusable (FAIR), as well as open to anybody, anywhere, at any time. Most of all, its purpose is to create a novel way to access scientific literature.
To date, BLR has extracted ~350,000 taxonomic treatments and ~200,000 figures from over 38,000 publications. This includes the descriptions of 55,800 new species, 3,744 new genera, and 28 new families. BLR has contributed to the discovery of over 30% of the ~17,000 species described annually.
Prof. Lyubomir Penev, founder and CEO of Pensoft says,
“It is such a great satisfaction to see how the development process of the TaxPub standard, started by Plazi some 15 years ago and implemented as a routine publishing workflow at Pensoft’s journals in 2010, has now resulted in an entire infrastructure that allows automated extraction and distribution of biodiversity data from various journals across the globe. With the recent announcement from the Consortium of European Taxonomic Facilities (CETAF) that their European Journal of Taxonomy is joining the TaxPub club, we are even more confident that we are paving the right way to fully grasping the dimensions of the world’s biodiversity.”
Dr Donat Agosti, co-founder and president of Plazi, adds:
“Finally, information technology allows us to create a comprehensive, extended catalogue of life and bring to light this huge corpus of cultural and scientific heritage – the description of life on Earth – for everybody. The nature of taxonomic treatments as a network of citations and syntheses of what scientists have discovered about a species allows us to link distinct fields such as genomics and taxonomy to specimens in natural history museums.”
Dr Tim Smith, Head of Collaboration, Devices and Applications Group at CERN, comments:
“Moving the focus away from the papers, where concepts are communicated, to the concepts themselves is a hugely significant step. It enables BLR to offer a unique new interconnected view of the species of our world, where the taxonomic treatments, their provenance, histories and their illustrations are all linked, accessible and findable. This is inspirational for the digital liberation of other fields of study!”
###
Additional information:
BLR is a joint project led by Plazi in partnership with Pensoft and Zenodo at CERN.
A mystery has long shrouded the orb-weaving spider genus Opadometa, where males and females belonging to one and the same species look nothing alike. Furthermore, the males appear to be so elusive that scientists still doubt whether both sexes are correctly linked to each other even in the best-known species.
Such is the case for Opadometa sarawakensis – a species known only from female specimens. While remarkable with their striking red and blue colors and large size, the females could not give the slightest hint about the likely appearance of the male Opadometa sarawakensis.
The red and blue female Opadometa sarawakensis
Nevertheless, students taking part in a recent two-week tropical ecology field course organized by the Naturalis Biodiversity Center and Leiden University, and hosted by the Danau Girang Field Centre (DGFC) on the island of Borneo, Malaysia, found a mature male spider hanging on the web of a red and blue female, later identified as Opadometa sarawakensis. Still quite striking, the male was colored in a blend of orange, gray, black, and silver.
At the brink of a long-awaited discovery and eager to describe the male, the students along with their lecturers and the field station scientific staff encountered a peril – with problematic species like the studied orb weaver they were in need for strong evidence to prove that it matched the female from the web. Furthermore, molecular DNA-based analysis was not an option at the time, since the necessary equipment was not available at DGFC.
On the other hand, being at the center of the action turned out to have advantages no less persuasive than DNA evidence. Having conducted thorough field surveys in the area, the team has concluded that the male’s observation on that particular female’s web in addition to the fact that no other Opadometa species were found in the area, was enough to prove they were indeed representatives of the same spider.
Adapting to the quite basic conditions at the DGFC laboratory, the students and their mentors put in use various items they had on hand, including smartphones paired up with headlights mounted on gooseneck clips in place of sophisticated cameras.
In the end, they gathered all the necessary data to prepare the formal description of the newly identified male.
Once they had the observations and the data, there was only one question left to answer. How could they proceed with the submission of a manuscript to a scholarly journal, so that their finding is formally announced and recognised?
Thanks to the elaborated and highly automated workflow available at the peer-reviewed open access Biodiversity Data Journal and its underlying ARPHA Writing Tool, the researchers managed to successfully compile their manuscript, including all underlying data, such as geolocations, and submit it from the field station. All in all, the authoring, peer review and publication – each step taking place within the ARPHA Platform‘s singular environment – took less than a month to complete. In fact, the paper was published within few days after being submitted.
This is the second publication in the series “Dispatch from the field”, resulting from an initiative led by spider taxonomist Dr Jeremy Miller. In 2014, another team of students and their mentors described a new species of curious one-millimetre-long spider from the Danau Girang Field Center. Both papers serve to showcase the feasibility of publication and sharing of easy to find, access and re-use biodiversity data.
“This has been a unique educational experience for the students,” says Jeremy. “They got to experience how tropical field biologists work, which is often from remote locations and without sophisticated equipment. This means that creativity and persistence are necessary to solve problems and complete a research objective. The fact that the students got to participate in advancing knowledge about this remarkable spider species by contributing to a manuscript was really exciting.”
###
Original source:
Miller J, Freund C, Rambonnet L, Koets L, Barth N, van der Linden C, Geml J, Schilthuizen M, Burger R, Goossens B (2018) Dispatch from the field II: the mystery of the red and blue Opadometa male (Araneae, Tetragnathidae, Opadometa sarawakensis). Biodiversity Data Journal6: e24777. https://doi.org/10.3897/BDJ.6.e24777
As much as research data sharing and re-usability is a staple in the open science practices, their value would be hugely diminished if their quality is compromised.
In a time when machine-readability and the related software are getting more and more crucial in science, while data are piling up by the minute, it is essential that researchers efficiently format and structure as well as deposit their data, so that they can make it accessible and re-usable for their successors.
Errors, as in data that fail to be read by computer programs, can easily creep into any dataset. These errors are as diverse as invalid characters, missing brackets, blank fields and incomplete geolocations.
To summarise the lessons learnt from our extensive experience in biodiversity data audit at Pensoft, we have now included a Data Quality Checklist and Recommendations page in the About section of each of our data-publishing journals.
We are hopeful that these guidelines will help authors prepare and publish datasets of higher quality, so that their work can be fully utilised in subsequent research.
At the end of the day, proofreading your data is no different than running through your text looking for typos.