With expertise in science communication, dissemination and exploitation, Pensoft is involved in this project set to develop new technologies for monitoring species and their habitats across Europe
With expertise in science communication, dissemination and exploitation, Pensoft became part of this project dedicated to new technologies for species and habitat monitoring across Europe
Background
The European Union puts a great value in monitoring the health of ecosystems, as comprehensive mapping can aid policy makers’ work in adopting appropriate legislation for nature conservation. It allows for understanding the impact of human activities and making informed decisions for effective management of nature’s resources. This is particularly important for the EU, as it has set ambitious goals to halt biodiversity loss and restore degraded ecosystems by 2030, as outlined in the EU Biodiversity Strategy for 2030.
Effective biodiversity monitoring can help the EU track progress towards these goals, assess the effectiveness of conservation policies and initiatives, and identify emerging threats to biodiversity.
Despite this awareness, efforts to monitor animals and plants remain spatially and temporally fragmented. This lack of integration regarding data and methods creates a gap in biodiversity monitoring, which can negatively impact policy-making. Today, modern technologies such as drones, artificial intelligence algorithms, or remote sensing are still not widely used in biodiversity monitoring.
MAMBO project (Modern Approaches to the Monitoring of BiOdiversity) recognises this need and aims to develop, test, and implement enabling tools for monitoring conservation status and ecological requirements of species and habitats. Having started in late 2022, the project is set to run for four years until September 2026.
Pensoft – with its proven expertise in communicating scientific results – is committed to amplifying the impact of MAMBO. Pensoft supports the project through tailored approaches to communication, dissemination and exploitation so as to reach the most appropriate target audience and achieve maximum visibility of the project.
Deep-dive into the project
In order to enrich the biodiversity monitoring landscape, MAMBO will implement a multi-disciplinary approach by utilising the technical expertise in the fields of computer science, remote sensing, and social science expertise on human-technology interactions, environmental economy, and citizen science. This will be combined with knowledge on species, ecology, and conservation biology.
More specifically, the project will develop, evaluate and integrate image and sound recognition-based AI solutions for EU biodiversity monitoring from species to habitats as well as promote the standardised calculation and automated retrieval of habitat data using deep learning and remote sensing.
“Classification algorithms have matured to an extent where it is possible to identify organisms automatically from digital data, such as images or sound,”
“Technical breakthroughs in the realm of high spatial resolution remote sensing set the future of ecological monitoring and can greatly enrich traditional approaches to biodiversity monitoring.”
In order to achieve its goals, the project will test existing tools in combination with MAMBO-developed new technologies at the project’s demonstration sites geographically spread across Europe. This will contribute to an integrated European biodiversity monitoring system with potential for dynamic adaptations.
Pensoft is part of MAMBO’s Work Package 7 (WP7): “Science-policy interface and dissemination”, led by Helmholtz Centre for Environmental Research (UFZ). The work package is dedicated to providing a distinct identity of the project and its services through branding, visualisation and elaborated dissemination and communication strategy.
Within WP7, Pensoft will also be taking care after the launch of an open-science collection of research outputs in the scholarly journal Research Ideas and Outcomes(RIO).
Amongst the tasks of the partners in WP7 is also the development of different pathways for integrating new technologies and innovations into the EU Pollinators Monitoring Scheme (EU PoMS; SPRING).
You can find more about the project on the MAMBO website: mambo-project.eu. Stay up to date with the project’s progress on Twitter (@MAMBO_EU) and Linkedin (/MAMBO Project).
OpenBiodiv is a biodiversity database containing knowledge extracted from scientific literature, built as an Open Biodiversity Knowledge Management System.
Apart from coordinating the Horizon 2020-funded project BiCIKL, scholarly publisher and technology provider Pensoft has been the engine behind what is likely to be the first production-stage semantic system to run on top of a reasonably-sized biodiversity knowledge graph.
OpenBiodiv is a biodiversity database containing knowledge extracted from scientific literature, built as an Open Biodiversity Knowledge Management System.
As of February 2023, OpenBiodiv contains 36,308 processed articles; 69,596 taxon treatments; 1,131 institutions; 460,475 taxon names; 87,876 sequences; 247,023 bibliographic references; 341,594 author names; and 2,770,357 article sections and subsections.
In fact, OpenBiodiv is a whole ecosystem comprising tools and services that enable biodiversity data to be extracted from the text of biodiversity articles published in data-minable XML format, as in the journals published by Pensoft (e.g. ZooKeys, PhytoKeys, MycoKeys, Biodiversity Data Journal), and other taxonomic treatments – available from Plazi and Plazi’s specialised extraction workflow – into Linked Open Data.
“I believe that OpenBiodiv is a good real-life example of how the outputs and efforts of a research project may and should outlive the duration of the project itself. Something that is – of course – central to our mission at BiCIKL.”
explains Prof Lyubomir Penev, BiCIKL’s Project Coordinator and founder and CEO of Pensoft.
“The basics of what was to become the OpenBiodiv database began to come together back in 2015 within the EU-funded BIG4 PhD project of Victor Senderov, later succeeded by another PhD project by Mariya Dimitrova within IGNITE. It was during those two projects that the backend Ontology-O, the first versions of RDF converters and the basic website functionalities were created,”
he adds.
At the time OpenBiodiv became one of the nine research infrastructures within BiCIKL tasked with the provision of virtual access to open FAIR data, tools and services, it had already evolved into a RDF-based biodiversity knowledge graph, equipped with a fully automated extraction and indexing workflow and user apps.
Currently, Pensoft is working at full speed on new user apps in OpenBiodiv, as the team is continuously bringing into play invaluable feedback and recommendation from end-users and partners at BiCIKL.
As a result, OpenBiodiv is already capable of answering open-ended queries based on the available data. To do this, OpenBiodiv discovers ‘hidden’ links between data classes, i.e. taxon names, taxon treatments, specimens, sequences, persons/authors and collections/institutions.
Thus, the system generates new knowledge about taxa, scientific articles and their subsections, the examined materials and their metadata, localities and sequences, amongst others. Additionally, it is able to return information with a relevant visual representation about any one or a combination of those major data classes within a certain scope and semantic context.
Users can explore the database by either typing in any term (even if misspelt!) in the search engine available from the OpenBiodiv homepage; or integrating an Application Programming Interface (API); as well as by using SPARQL queries.
On the OpenBiodiv website, there is also a list of predefined SPARQL queries, which is continuously being expanded.
“OpenBiodiv is an ambitious project of ours, and it’s surely one close to Pensoft’s heart, given our decades-long dedication to biodiversity science and knowledge sharing. Our previous fruitful partnerships with Plazi, BIG4 and IGNITE, as well as the current exciting and inspirational network of BiCIKL are wonderful examples of how far we can go with the right collaborators,”
Which one is the species that springs to mind when you think about the most awesome discoveries in recent times?
In an age where we more than ever need to appreciate and preserve the magnificent biodiversity inhabiting the Earth, we decided to go for a lighter and fun take on the work of taxonomists that often goes unnoticed by the public.
From the ocean depths surrounding Indonesia to the foliage of the native forests of Príncipe Island and into the soils of Borneo, we started with 16 species described as new to science in journals published by Pensoft over the years.
Out of these most amazing creatures, over the past several weeks we sought to find who’s got the greatest fandom by holding a poll on Twitter (you can follow it further down here or via #NewSpeciesShowdown).
Grand Finale – here comes the champion!
Truly, we couldn’t have a more epic final!
The two competitors come from two kingdoms, two opposite sides of the globe, and the “pages” of two journals, namely PhytoKeys and Evolutionary Systematics.
While we need to admit that we ourselves expected to crown an animal as the crowd-favourite, we take the opportunity to congratulate the botanists amongst our fans for the well-deserved win of Nepenthes pudica (see the species description)!
Find more about the curious one-of-a-kind pitcher plant in this blog post, where we announced its discovery following the new species description in PhytoKeys in June 2022:
Back then, N. pudica gave a good sign about its worldwide web appeal, when it broke the all-time record for online popularity in a competition with all plant species described in PhytoKeys over the journal’s 22-year history of taxonomic papers comrpising over 200 issues.
What’s perhaps even more curious, is that there is only one species EVER described in a Pensoft-published journal that has so far triggered more tweets than the pitcher plant, and that species is the animal that has ended up in second place in the New Species Showdown: a tiny amphibian living in Peru, commonly known as the the Amazon Tapir Frog (Synapturanus danta).Which brings us once again to the influence of botanists in taxonomic research.
Read more about its discovery in the blog post from February 2022:
Another thing that struck us during the tournament was that there was only one species described in our flagship journal in systematic journal ZooKeys: the supergiant isopod Bathynomus raksasa, that managed to fight its way to the semi-finals, where it lost against S. danta.
This makes us especially proud with our diverse and competitive journal portfolio full of titles dedicated to biodiversity and taxonomic research!
The rules
Twice a week, @Pensoft would announce a match between two competing species on Twitter using the hashtag #NewSpeciesShowdown, where everyone could vote in the poll for their favourie.
Disclaimer
This competition is for entertainment purposes only. As it was tremendously tough to narrow the list down to only sixteen species, we admit that we left out a lot of spectacular creatures.
To ensure fairness and transparency, we made the selection based on the yearly Altmetric data, which covers articles in our journals published from 2010 onwards and ranks the publications according to their online mentions from across the Web, including news media, blogs and social networks.
We did our best to diversify the list as much as possible in terms of taxonomic groups. However, due to the visual-centric nature of social media, we gave preference to immediately attractive species.
The first tie of the New Species Showdown was between the olinguito: Bassaricyon neblina (see species description) and the “snow-coated” tussock moth Ivela yini (see species description).
In the second battle, we faced two marine species discovered in the Indian Ocean and described in ZooKeys. The supergiant isopod B. raksasa (see species description) won against the Rose Fariy Wrasse C. finifenmaa (see species description) with strong 75%.
✨Tapir “chocolate” frog S. danta claims the #NewSpeciesShowdown victory against the transparent Glass frog H. yaku by 73%! 🙌Congrats to all who voted for the tiny but very pretty frog which was described only this year in @EvolSystematics! pic.twitter.com/kAFrmepyJa
In the third battle, we faced two frog species: the tapir ‘chocolate’ frog described in Evolutionary Systematics (see species description) winning against the ‘glass frog’ described in Zookeys (see species description) with 73%.
With 62% of the votes, the two-species tournament saw the Harryplax severus crab grab the win against another species named after a great wizard from the Harry Potter universe: the Salazar’s pit viper, which was described in the journal Zoosystematics and Evolution in 2020. The “unusual” crustacean was described back in 2017 in ZooKeys. As its species characters matched no genus known to date, the species also established the Harryplax genus.
Earlier this year, the 1st #plant to grow underground pitcher was described in @PhytoKeys & quickly became the most tweeted paper EVER published in our #botany#journal! So, it isn't too hard to see how it won with 68% against the Demon's orchid in this #NewSpeciesShowdown!🔝 1/3 pic.twitter.com/toC6epfVus
With the fifth battle in the New Species Showdown taking us to the Kingdom of Plants, we enjoyed a great battle between the first pitcher plant found to grow its pitchers underground to dine (see the full study) and the Demon’s orchid, described in 2016 from a single population spread across a dwarf montane forest in southern Colombia (read the study). Both species made the headlines across the news media around the world following their descriptions in our flagship botany journal PhytoKeys.
Next, we saw the primitive dipluran Haplocampa wagnelli (read its species description in Subterranean Biology) – a likely survivor of the Ice Age thanks to the caves of Canada – win the public in a duel against Xuedytes bellus (described in ZooKeys in 2017), also known as the Most cave-adapted trechine beetle in the world!
We had a close battle between the Principe Scops-owl Otus bikegila (see species description published in our ZooKeys earlier in 2022) and the blue-tailed Monitor lizard Varanus semotus (also first ‘known’ from the pages of ZooKeys, 2016). Being adorable species, but also ‘castaways’ on isolated islands in the Atlantic, they made great sensations upon their discovery.In fact, the reptile won with a single vote!
In the last battle of Round 1, the ‘horned’ tarantula C. attonitifer claimed the victory with a strong (80%) advantage from its competitor with a rebel name: the freshwater crayfish C. snowden (species description in ZooKeys from 2015). Described in African Invertebrates in 2019, the arachnid might be one amongst many ‘horned’ baboon spiders, yet there was something quite extraordinary about its odd protuberance. Furthermore, it came to demonstrate how little we know about the fauna of Angola: a largely underexplored country located at the intersection of several ecoregions.
In the first quarter-final round, in the close battle, the isopod ’emerged’ from the ocean depths of Indonesia B. raksasa (species description in Zookeys from 2020) claimed the victory with just a few votes difference (58%!) from its competitor: lovely olinguito B. neblina, also described in Zookeys but back in 2013.
After a challenging round, the ‘chocolate’ Tapir #frog S. danta (discovery published in @EvolSystematics) makes it to the semi-final leaving its competitor #crab Harryplax severus behind!
In the second round of the quarter-final, the tapir ‘chocolate’ frog S. danta (described in Evolutionary Systematics this year) claimed the victory with a significant advantage (69%) over its competitor crab H. severus described in Zookeys in 2017.
The third battle in Round 2 secured a place at the semi-finals for the only plant to get this far in the New Species Showdown. If you are dedicated to the mission of proving the plant kingdom superior: keep supporting Nepenthes pudica in the semi-finals and beyond! In the meantime, read the full description of the species, published in our PhytoKeys in June.
The last quarter-final send the Angolan ‘horned’ tarantula to the next round. Described in African Invertebrates in 2019, its discovery would have likely remained a secret had it not been for the local tribes who provided the research team with crucial information about the curious arachnid.
Curiously enough, by winning against the ‘supergiant’ isopod B. raksasa – also known around the Internet as the ‘Darth Vader of the seas’ – the Amazonian anuran S. danta outcompetes the last species in the New Species Showdown representing our flagship taxonomy journal: ZooKeys.
In a dramatic turn of events, the tight match between the Angolan tarantula C. attonitifer , whose ‘horn’ protruding from its back surprised the scientists because of its unique structure and soft texture, and the first pitcher plant whose ‘traps’ can be found underground in Borneo, ended up with the news that the New Species Showdown will be concluding with a battle between the kingdoms Animalia and Plantae! What a denouement!
If you have gone to the Pensoft website at any point in 2022, visited our booth at a conference, or received a newsletter from any of our journals, by this time, you must be well aware that in 2022 – more precisely, on 25 December – we turned 30. And we weren’t afraid to show it!
Pensoft’s team happy to showcase the 30-year story of the company at various events this year. Left: Maria Kolesnikova at the annual Biodiversity Information Standards (TDWG 2022) conference, hosted by Pensoft in Sofia, Bulgaria. Right: Iva Boyadzhieva at the XXVI International Congress of Entomology (ICE 2022) in Helsinki, Finland.
Indeed, 30 is not that big of a number, as many of us adult humans can confirm. Yet, we take pride in reminiscing about what we’ve done over the last three decades.
The truth is, 30 years ago, we wouldn’t have been able to picture this day, let alone think that we’d be sharing it with all of you: our journal readers, authors, editors and reviewers, collaborators in innovation, project partners, and advisors.
Long story short, we wanted to do something special and fun to wrap up our anniversary year. While we have been active in various areas, including development of publishing technology concerning open and FAIR access and linkage for research outcomes and underlying data; and multiple EU-supported scientific projects, we have always been associated with our biodiversity journal portfolio.
Besides, who doesn’t like to learn about the latest curious creature that has evaded scientific discovery throughout human history up until our days? 😉
Soil and its macrofauna are an integral part of many ecosystems, playing an important role in decomposition and nutrient recycling. However, soil biodiversity remains understudied globally.
To help fill this gap and reveal the diversity of soil fauna in Hong Kong, a team of scientists from The Chinese University of Hong Kong initiated a citizen science project involving universities, non-governmental organisations and secondary school students and teachers.
“Involving citizens as part of the new knowledge generation process is important in promoting the understanding of biodiversity. Training younger-generation citizens to learn about biodiversity is of utmost importance and crucial to conservation engagement”
– say the researchers in their study, which was published in the open-access Biodiversity Data Journal.
The soil sampling methodology that the students employed in this study. Video by Sheung Yee Lai, Ka Wai Ting, Tze Kiu Chong and Wai Lok So.
Working side by side with university academics, taxonomists and non-governmental organisation members, students from 21 schools/institutes were recruited to collect soil animals near their campusesfor a year and record their observations.
Between October 2019 and October 2020, they monitored and sampled species across 21 sites of urban and semi-natural habitats in Hong Kong, collecting a total of 3,588 individual samples. Their efforts yielded 150 soil macrofaunal species, identified as arthropods (including insects, spiders, centipedes and millipedes), worms, and snails.
Most often, the students found millipedes (23 out of 150 species). They even helped identify two millipede species that are new to Hong Kong’s fauna: Monographis queenslandica and Alloproctoides remyi. The former is usually found in Australia – the researchers suggest it might have been introduced to the area many decades ago from Queensland or vice versa – and the latter has been observed in Reunion and Mauritius.
Two polyxenid millipede species, collected in this study, turned out to had never before been recorded from Hong Kong. Left: Monographis queenslandica and Alloproctoides remyi (right). Image by Sheung Yee Lai, Ka Wai Ting and Wai Lok So.
Millipedes like these two species can accelerate litter decomposition and regulate the soil carbon and phosphorus cycling, while earthworms can modify the soil structure and regulate water and organic matter cycling.
“Before the beginning of this project, the understanding of soil biodiversity in Hong Kong, including the understanding of its contained millipede species, was inadequate”
the researchers write in their paper.
Now, they believe that the identified macrofauna species and their 646 DNA barcodes have established a solid foundation for further research in soil biodiversity in the area.
Their project also serves an additional purpose. Unlike most conventional scientific studies, which are usually carried out by the government, non-governmental organisations or academics in universities alone, this study utilised a citizen science approach through creating a big community engaged with biodiversity. In doing so, it helped educate the public and raise awareness on the use of basic science techniques in understanding local biodiversity.
So, it may have inspired a new generation of future scientists: some students started millipede cultures in their own schools, and one school used the millipede breeding model to participate in a science and technology competition.
This study is a proof that local institutes and high schools can unite together with research teams at universities and perform scientific work, the study’s authors believe.
It “has raised public awareness and potentially opens up opportunities for the general public to engage in scientific research in the future.”
The team hopes that their approach could inspire future biodiversity sampling and monitoring studies to engage more citizen scientists.
***
Research article:
So WL, Ting KW, Lai SY, Huang EYY, Ma Y, Chong TK, Yip HY, Lee HT, Cheung BCT, Chan MK, Consortium HKSB, Nong W, Law MMS, Lai DYF, Hui JHL (2022) Revealing the millipede and other soil-macrofaunal biodiversity in Hong Kong using a citizen science approach. Biodiversity Data Journal 10: e82518. https://doi.org/10.3897/BDJ.10.e82518
New Research Idea, published in RIO Journal presents a promising machine-learning ecosystem to unite experts around the world and make up for lacking taxonomic expertise.
In their Research Idea, published in Research Ideas and Outcomes (RIO Journal), Swiss-Dutch research team present a promising machine-learning ecosystem to unite experts around the world and make up for lacking expert staff
Guest blog post by Luc Willemse, Senior collection manager at Naturalis Biodiversity Centre (Leiden, Netherlands)
Imagine the workday of a curator in a national natural history museum. Having spent several decades learning about a specific subgroup of grasshoppers, that person is now busy working on the identification and organisation of the holdings of the institution. To do this, the curator needs to study in detail a huge number of undescribed grasshoppers collected from all sorts of habitats around the world.
The problem here, however, is that a curator at a smaller natural history institution – is usually responsible for all insects kept at the museum, ranging from butterflies to beetles, flies and so on. In total, we know of around 1 million described insect species worldwide. Meanwhile, another 3,000 are being added each year, while many more are redescribed, as a result of further study and new discoveries. Becoming a specialist for grasshoppers was already a laborious activity that took decades, how about knowing all insects of the world? That’s simply impossible.
Then, how could we expect from one person to sort and update all collections at a museum: an activity that is the cornerstone of biodiversity research? A part of the solution, hiring and training additional staff, is costly and time-consuming, especially when we know that experts on certain species groups are already scarce on a global scale.
We believe that automated image recognition holds the key to reliable and sustainable practises at natural history institutions.
Today, image recognition tools integrated in mobile apps are already being used even by citizen scientists to identify plants and animals in the field. Based on an image taken by a smartphone, those tools identify specimens on the fly and estimate the accuracy of their results. What’s more is the fact that those identifications have proven to be almost as accurate as those done by humans. This gives us hope that we could help curators at museums worldwide take better and more timely care of the collections they are responsible for.
However, specimen identification for the use of natural history institutions is still much more complex than the tools used in the field. After all, the information they store and should be able to provide is meant to serve as a knowledge hub for educational and reference purposes for present and future generations of researchers around the globe.
This is why we propose a sustainable system where images, knowledge, trained recognition models and tools are exchanged between institutes, and where an international collaboration between museums from all sizes is crucial. The aim is to have a system that will benefit the entire community of natural history collections in providing further access to their invaluable collections.
We propose four elements to this system:
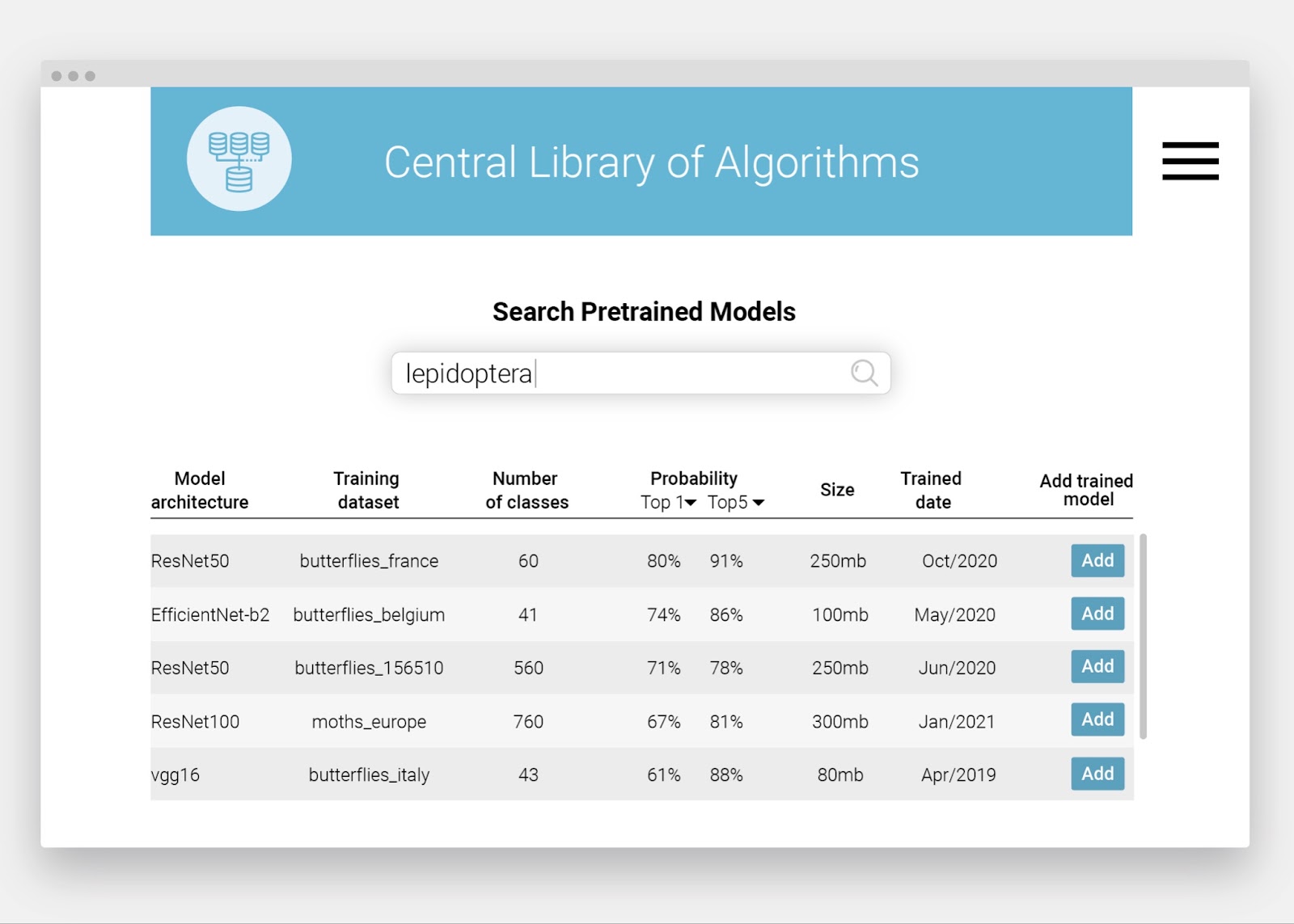
A central library of already trained image recognition models (algorithms) needs to be created. It will be openly accessible, so any other institute can profit from models trained by others.
Mock-up of a Central Library of Algorithms.
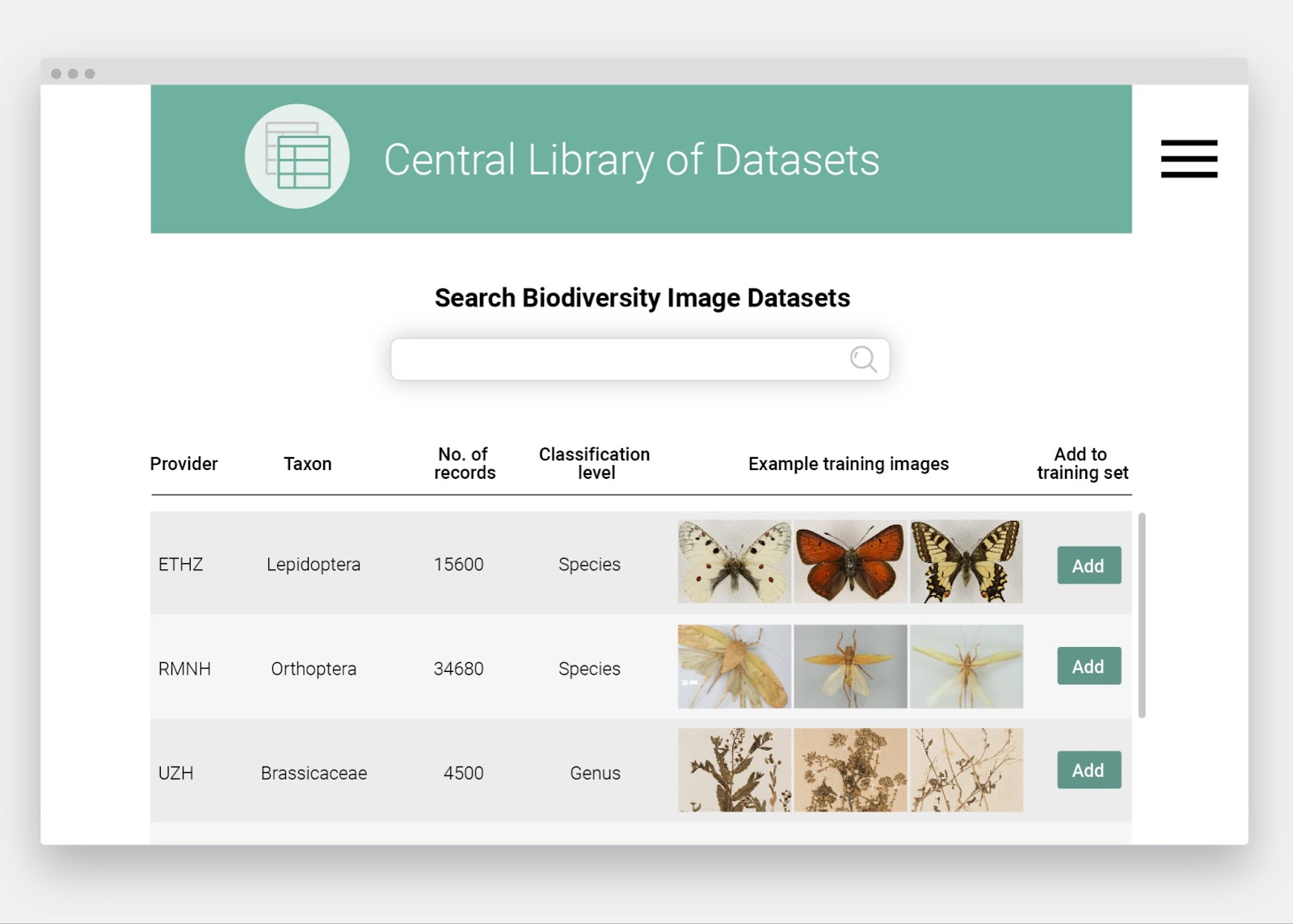
A central library of datasets accessing images of collection specimens that have recently been identified by experts. This will provide an indispensable source of images for training new algorithms.
Mock-up of a Central Library of Datasets.
A digital workbench that provides an easy-to-use interface for inexperienced users to customise the algorithms and datasets to the particular needs in their own collections.
As the entire system depends on international collaboration as well as sharing of algorithms and datasets, a user forum is essential to discuss issues, coordinate, evaluate, test or implement novel technologies.
How would this work on a daily basis for curators? We provide two examples of use cases.
First, let’s zoom in to a case where a curator needs to identify a box of insects, for example bush crickets, to a lower taxonomic level. Here, he/she would take an image of the box and split it into segments of individual specimens. Then, image recognition will identify the bush crickets to a lower taxonomic level. The result, which we present in the table below – will be used to update object-level registration or to physically rearrange specimens into more accurate boxes. This entire step can also be done by non-specialist staff.
Mock-up of box with grasshoppers mentioned in the above table
Results of automated image recognition identify specimens to a lower taxonomic level.
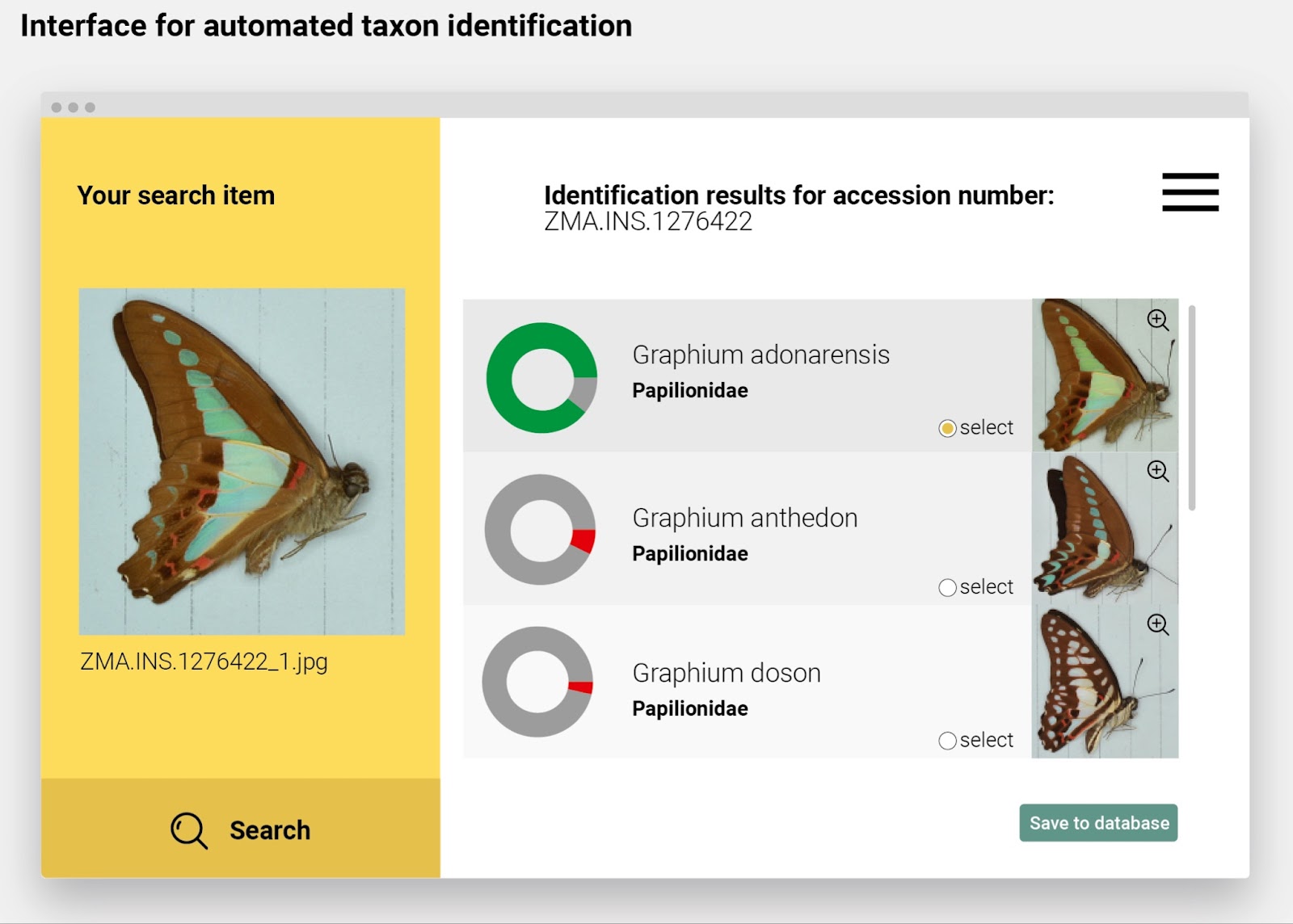
Another example is to incorporate image recognition tools into digitisation processes that include imaging specimens. In this case, image recognition tools can be used on the fly to check or confirm the identifications and thus improve data quality.
Mock-up of an interface for automated taxon identification.
Using image recognition tools to identify specimens in museum collections is likely to become common practice in the future. It is a technical tool that will enable the community to share available taxonomic expertise.
Using image recognition tools creates the possibility to identify species groups for which there is very limited to none in-house expertise. Such practises would substantially reduce costs and time spent per treated item.
Image recognition applications carry metadata like version numbers and/or datasets used for training. Additionally, such an approach would make identification more transparent than the one carried out by humans whose expertise is, by design, in no way standardised or transparent.
Greeff M, Caspers M, Kalkman V, Willemse L, Sunderland BD, Bánki O, Hogeweg L (2022) Sharing taxonomic expertise between natural history collections using image recognition. Research Ideas and Outcomes 8: e79187. https://doi.org/10.3897/rio.8.e79187
Revolutionary environmental DNA analysis holds great potential for the future of biodiversity monitoring, concludes a new study
Collection of water samples for eDNA metabarcoding bioassessment. Photo by Till-Hendrik Macher.
In times of exacerbating biodiversity loss, reliable data on species occurrence are essential, in order for prompt and adequate conservation actions to be initiated. This is especially true for freshwater ecosystems, which are particularly vulnerable and threatened by anthropogenic impacts. Their ecological status has already been highlighted as a top priority by multiple national and international directives, such as the European Water Framework Directive.
However, traditional monitoring methods, such as electrofishing, trapping methods, or observation-based assessments, which are the current status-quo in fish monitoring, are often time- and cost-consuming. As a result, over the last decade, scientists progressively agree that we need a more comprehensive and holistic method to assess freshwater biodiversity.
Meanwhile, recent studies have continuously been demonstrating that eDNA metabarcoding analyses, where DNA traces found in the water are used to identify what organisms live there, is an efficient method to capture aquatic biodiversity in a fast, reliable, non-invasive and relatively low-cost manner. In such metabarcoding studies, scientists sample, collect and sequence DNA, so that they can compare it with existing databases and identify the source organisms.
Furthermore, as eDNA metabarcoding assessments use samples from water, often streams, located at the lowest point, one such sample usually contains not only traces of specimens that come into direct contact with water, for example, by swimming or drinking, but also collects traces of terrestrial species indirectly via rainfalls, snowmelt, groundwaters etc.
In standard fish eDNA metabarcoding assessments, these ‘bycatch data’ are typically left aside. Yet, from a viewpoint of a more holistic biodiversity monitoring, they hold immense potential to also detect the presence of terrestrial and semi-terrestrial species in the catchment.
In their new study, reported in the open-access scholarly journalMetabarcoding and Metagenomics, German researchers from the University of Duisburg-Essen and the German Environment Agency successfully detected an astonishing quantity of the local mammals and birds native to the Saxony-Anhalt state by collecting as much as 18 litres of water from across a two-kilometre stretch along the river Mulde.
After water filtration the eDNA filter is preserved in ethanol until further processing in the lab. Photo by Till-Hendrik Macher.
In fact, it took only one day for the team, led by Till-Hendrik Macher, PhD student in the German Federal Environmental Agency-funded GeDNA project, to collect the samples. Using metabarcoding to analyse the DNA from the samples, the researchers identified as much as 50% of the fishes, 22% of the mammal species, and 7.4% of the breeding bird species in the region.
However, the team also concluded that while it would normally take only 10 litres of water to assess the aquatic and semi-terrestrial fauna, terrestrial species required significantly more sampling.
Unlocking data from the increasingly available fish eDNA metabarcoding information enables synergies among terrestrial and aquatic biodiversity monitoring programs, adding further important information on species diversity in space and time.
“We thus encourage to exploit fish eDNA metabarcoding biodiversity monitoring data to inform other conservation programs,”
says lead author Till-Hendrik Macher.
“For that purpose, however, it is essential that eDNA data is jointly stored and accessible for different biodiversity monitoring and biodiversity assessment campaigns, either at state, federal, or international level,”
concludes Florian Leese, who coordinates the project.
Original source:
Macher T-H, Schütz R, Arle J, Beermann AJ, Koschorreck J, Leese F (2021) Beyond fish eDNA metabarcoding: Field replicates disproportionately improve the detection of stream associated vertebrate species. Metabarcoding and Metagenomics 5: e66557. https://doi.org/10.3897/mbmg.5.66557
A new species of tiny cave snail that glistens in the light and has a muffin-top-like bulge, was discovered by Marina Ferrand of the French Club Etude et Exploration des Gouffres et Carrières (EEGC), during the Phouhin Namno caving expedition in Tham Houey Yè cave in Laos in March 2019. The new species, named Laoennea renouardi was described in the open-access, peer-reviewed journal Subterranean Biology.
Tham Houey Yè cave (Vientiane Province, Laos), inhabited by the newly discovered “muffin-topped” snail species Laoennea renouardi. Photo by Jean-Francois Fabriol.
A new species of tiny cave snail that glistens in the light and has a muffin-top-like bulge, was discovered by Marina Ferrand of the French Club Etude et Exploration des Gouffres et Carrières (EEGC), during the Phouhin Namno caving expedition in Tham Houey Yè cave in Laos in March 2019. The new species, Laoennea renouardi, is 1.80 mm tall and is named after the French caver,Louis Renouard, who explored and mapped the only two caves in Laos known to harbor this group of tiny snails. Only two species of Laoennea snail are known so far, L. carychioides and now, L. renouardi.
The new transparent “muffin-topped” snail, Laoennea renouardi. Photo by Estée Bochud.
“The discovery and description of biodiversity before it disappears is a major priority for biologists worldwide. The caves in Laos are still largely underexplored and the snails known from them remain few in number,”
points out Dr. Jochum.
The fact that two species of tiny cave snails of the same group were found in two caves located in two independent karstic networks 3.4 km apart, caused the authors to question evolutionary processes in these underground hotspots of biodiversity. The authors hypothesise that the two caves might have been connected during the Quaternary, around 100–200 thousand years ago. In time, the river Yè might have formed a barrier, thus disconnecting the cave systems and separating the populations. As a result, the snails evolved into two different species.
A new species of tiny cave snail that glistens in the light and has a muffin-top-like bulge, was discovered by Marina Ferrand of the French Club Etude et Exploration des Gouffres et Carrie?res (EEGC), during the Phouhin Namno caving expedition in Tham Houey Yè cave in Laos in March 2019. The new species, Laoennea renouardi, is 1.80 mm tall and is named after the French caver, Louis Renouard, who explored and mapped the only two caves in Laos known to harbor this group of tiny snails. Only two species of Laoennea snail are known so far, L. carychioides and now, L. renouardi.
Map of the two caves on opposite sides of the River Yè, Vientiane Province, Laos. Image by Louis Renouard.
The fact that two species of tiny cave snails of the same group were found in two caves located in two independent karstic networks 3.4 km apart, caused the authors to question evolutionary processes in these underground hotspots of biodiversity. The authors hypothesise that the two caves might have been connected during the Quaternary, around 100-200 thousand years ago. In time, the river Yè might have formed a barrier, thus disconnecting the cave systems and separating the populations. As a result, the snails evolved into two different species.
***
Original Source:
Jochum A, Bochud E, Favre A, Ferrand M, Wackenheim Q (2020) A new species of Laoennea microsnail (Stylommatophora, Diapheridae) from a cave in Laos. Subterranean Biology 36: 1-9. https://doi.org/10.3897/subtbiol.36.58977
by Mariya Dimitrova, Jorrit Poelen, Georgi Zhelezov, Teodor Georgiev, Lyubomir Penev
Fig. 1. Pensoft-GloBI workflow for indexing biotic interactions from scholarly literature
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species, etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 2 in Fig. 1).. We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as json to a GitHub repository, from where they could be accessed by GloBI.
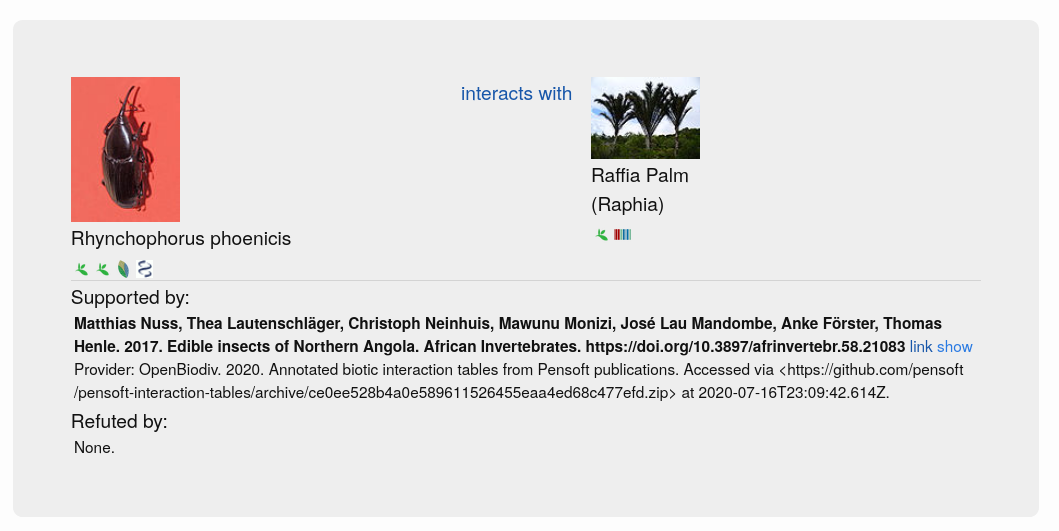
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ (Fig. 2) because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
Fig. 2. Example of a biotic interaction indexed by GloBI.
Examples of species interactions provided by OpenBiodiv and indexed by GloBI are available on GloBI’s website.
In the future we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6,993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 1 in Fig. 1). We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as JSON to a GitHub repository, from where they could be accessed by GloBI.
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
In the future, we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
References
Jorrit H. Poelen, James D. Simons and Chris J. Mungall. (2014). Global Biotic Interactions: An open infrastructure to share and analyze species-interaction datasets. Ecological Informatics. https://doi.org/10.1016/j.ecoinf.2014.08.005.
Additional Information
The work has been partially supported by the International Training Network (ITN) IGNITE funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 764840.
The researchers compared wild bee communities in the tropical dry forest of Mexico living in three habitat conditions: preserved vegetation, agricultural sites and urbanised areas
Changes in land use negatively affect bee species richness and diversity, and cause major shifts in species composition, reports a recent study of native wild bees, conducted at the Sierra de Quila Flora and Fauna Protection Area and its influence zone in Mexico.
Having registered a total of 14,054 individual bees representing 160 species, 52 genera, and five families over the span of a year, the scientists conclude that the studied preserved areas demonstrated “significantly greater” richness and diversity.
In their paper, published in the open-access Journal of Hymenoptera Research, a research team from the University of Guadalajara, Mexico, led by Alejandro Muñoz-Urias, compare three conditions within the tropical dry forest study site: preserved vegetation, an agricultural area with crops and livestock, and an urbanised area.
This bee species (Aztecanthidium xochipillium) is known exclusively from Mexico.
The researchers confirm earlier information that an increase in anthropogenic disturbances leads to a decrease in bee richness and diversity. While availability of food and nesting sites are the key factors for bee communities, changes in land use negatively impact flower richness and floral diversity. Thereby, turning habitats into urbanised or agricultural sites significantly diminishes the populations of the bees which rely on specific plants for nectar and pollen. These are the species whose populations are threatened with severe declines up to the point of local extinction.
According to their data, about half of the bees recorded were Western honey bees (49.9%), whereas polyester bees turned out to be the least abundant (1.2 %).
On the other hand, some generalist bees, which feed on a wide range of plants, seem to thrive in urbanised areas, as they take advantage of people watering wild and ornamental plants at times where draughts might be eradicating native vegetation.
“That is the reason why bees that can use a wide variety of resources are often able to compensate when circumstances change, although some species disappear due to land use changes,” explain the scientists.
This is a tropical dry forest in the dry (left) and rainy season (right).
In conclusion, the authors recommend that the tropical dry forests of both the study area and Mexico in general need to be protected in order for these essential pollinators to be conserved.
“Pollinators are a key component for global biodiversity, because they assist in the sexual reproduction of many plant species and play a crucial role in maintaining terrestrial ecosystems and food security for human beings,” they remind.
###
Original source:
Razo-León AE, Vásquez-Bolaños M, Muñoz-Urias A, Huerta-Martínez FM (2018) Changes in bee community structure (Hymenoptera, Apoidea) under three different land-use conditions. Journal of Hymenoptera Research 66: 23-38. https://doi.org/10.3897/jhr.66.27367