Researchers studying the distribution of species need information about where the plant or animal species in question occurs. This usually requires a field study, which is costly, time-consuming and often CO2-intensive. In addition, not all locations where species occur are accessible to humans, such as high mountain areas. As a result, the full range of species is often not covered and the availability of species information is a major challenge for ecological research.
Social media and citizen science projects offer a great potential to increase this availability. Citizen science refers to the involvement of non-experts in scientific projects. In the case of ecological studies, for example, this is the sampling of species occurrences. Thanks to smartphones – capable of capturing high-quality photos and recording precise locations – the ability to gather and share species information has grown significantly. It’s quite simple: take a photo, save the coordinates, upload it, and researchers can use this data to map species distributions. User-friendly platforms or Apps like iNaturalist have become invaluable for this purpose, enabling researchers and citizen scientists to share and utilize occurrence data to advance ecological understanding.
Process of species occurrence data sampling by citizen science projects.
Although some people are interested in and help with such projects, they do not yet reach a broad mass of people. In our study, we explore the potential of the social media platform Instagram, which is one of the largest social media platforms with 2 billion users worldwide and millions of daily uploads. We hypothesize that even more species occurrence data is being generated on this platform, often without users realising its scientific value.
We searched for Instagram posts from 2021 to 2022 in which the tree species Nothofagus pumilio and the location of the photo can be identified. The deciduous species N. pumilio occurs at the treeline in the southern Andes. The species’ vibrant orange-red autumn colouring, in combination to spectacular landscapes, makes it a popular photo motif for tourists, hikers, and locals alike resulting in numerous Instagram posts. Because treelines are often sensitive to climate change, studying the distribution and dynamics of this species is of particular interest.
Nothofagus pumilio at Mount Fitz Roy, Patagonia (Marina Zvada, 2024 available at:https://unsplash.com/de/fotos/blick-auf-ein-gebirge-in-der-ferne-vMoLf1OrB-k?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash)
Our study began by searching Instagram for specific hashtags related to the species (#nothofaguspumilio and #lenga), as well as for locations through location tags, hashtags, and descriptions within posts. This approach allowed us to identify as many images with N. pumilio as possible, even if the users were unaware of its presence.
To select suitable posts, we focused on those where the species could be clearly identified, the location was described, and landscape elements (e.g. mountains, waterbodies, glaciers, urban and tourist area) are visible in the image, that could also be recognised in satellite imagery. For each post, we mapped at least one point at the location where the photo was taken. Additionally, we included occurrences of N. pumilio visible in the background, such as autumn-coloured treelines. This approach ensured a more comprehensive and evenly distributed sampling of the species’ range. The next image illustrates the sampling process of a post captured at Laguna Capri with Mount Fitz Roy in the background.
Suitable Instagram post (fernando.v.fotografia, 2022, left) and four transferred points with landscape elements (red boxes, right) that helped to identify the location, which is also described in the post with location tag and post caption.
In this way, we were able to generate 1238 Instagram ground truthing points. These points can be directly used in ecological studies. However, it is important to note that our Instagram ground truthing points, like most citizen science data, is spatially biased. This means that locations can only be captured where people have access, leaving remote or high-altitude areas unrepresented.
For this reason, we added a remote sensing method to our study. As this deciduous species forms mono-species forests at the treeline, it can also be identified in satellite imagery. The occurrence data obtained through supervised classification was then validated using the Instagram ground truthing points. This approach allows us to generate less-biased occurrence data for the species across its entire 2000 km latitudinal range.
All 1238 Instagram ground truthing points sampled by our approach (left) and the remote sensing result (right).
Participating in citizen science projects is an essential contribution to research. We encourage you to explore citizen science platforms such as iNaturalist, eBird, or naturgucker, and to include hashtags and detailed location descriptions – ideally with coordinates – when posting your holiday or everyday photos on Instagram. Every contribution helps!
Research article:
Werner M, Weidinger J, Böhner J, Schickhoff U, Bobrowski M (2024) Instagram data for validating Nothofagus pumilio distribution mapping in the Southern Andes: A novel ground truthing approach. Frontiers of Biogeography 17: e140606. https://doi.org/10.21425/fob.17.140606
Revolutionary environmental DNA analysis holds great potential for the future of biodiversity monitoring, concludes a new study
Collection of water samples for eDNA metabarcoding bioassessment. Photo by Till-Hendrik Macher.
In times of exacerbating biodiversity loss, reliable data on species occurrence are essential, in order for prompt and adequate conservation actions to be initiated. This is especially true for freshwater ecosystems, which are particularly vulnerable and threatened by anthropogenic impacts. Their ecological status has already been highlighted as a top priority by multiple national and international directives, such as the European Water Framework Directive.
However, traditional monitoring methods, such as electrofishing, trapping methods, or observation-based assessments, which are the current status-quo in fish monitoring, are often time- and cost-consuming. As a result, over the last decade, scientists progressively agree that we need a more comprehensive and holistic method to assess freshwater biodiversity.
Meanwhile, recent studies have continuously been demonstrating that eDNA metabarcoding analyses, where DNA traces found in the water are used to identify what organisms live there, is an efficient method to capture aquatic biodiversity in a fast, reliable, non-invasive and relatively low-cost manner. In such metabarcoding studies, scientists sample, collect and sequence DNA, so that they can compare it with existing databases and identify the source organisms.
Furthermore, as eDNA metabarcoding assessments use samples from water, often streams, located at the lowest point, one such sample usually contains not only traces of specimens that come into direct contact with water, for example, by swimming or drinking, but also collects traces of terrestrial species indirectly via rainfalls, snowmelt, groundwaters etc.
In standard fish eDNA metabarcoding assessments, these ‘bycatch data’ are typically left aside. Yet, from a viewpoint of a more holistic biodiversity monitoring, they hold immense potential to also detect the presence of terrestrial and semi-terrestrial species in the catchment.
In their new study, reported in the open-access scholarly journalMetabarcoding and Metagenomics, German researchers from the University of Duisburg-Essen and the German Environment Agency successfully detected an astonishing quantity of the local mammals and birds native to the Saxony-Anhalt state by collecting as much as 18 litres of water from across a two-kilometre stretch along the river Mulde.
After water filtration the eDNA filter is preserved in ethanol until further processing in the lab. Photo by Till-Hendrik Macher.
In fact, it took only one day for the team, led by Till-Hendrik Macher, PhD student in the German Federal Environmental Agency-funded GeDNA project, to collect the samples. Using metabarcoding to analyse the DNA from the samples, the researchers identified as much as 50% of the fishes, 22% of the mammal species, and 7.4% of the breeding bird species in the region.
However, the team also concluded that while it would normally take only 10 litres of water to assess the aquatic and semi-terrestrial fauna, terrestrial species required significantly more sampling.
Unlocking data from the increasingly available fish eDNA metabarcoding information enables synergies among terrestrial and aquatic biodiversity monitoring programs, adding further important information on species diversity in space and time.
“We thus encourage to exploit fish eDNA metabarcoding biodiversity monitoring data to inform other conservation programs,”
says lead author Till-Hendrik Macher.
“For that purpose, however, it is essential that eDNA data is jointly stored and accessible for different biodiversity monitoring and biodiversity assessment campaigns, either at state, federal, or international level,”
concludes Florian Leese, who coordinates the project.
Original source:
Macher T-H, Schütz R, Arle J, Beermann AJ, Koschorreck J, Leese F (2021) Beyond fish eDNA metabarcoding: Field replicates disproportionately improve the detection of stream associated vertebrate species. Metabarcoding and Metagenomics 5: e66557. https://doi.org/10.3897/mbmg.5.66557
by Mariya Dimitrova, Jorrit Poelen, Georgi Zhelezov, Teodor Georgiev, Lyubomir Penev
Fig. 1. Pensoft-GloBI workflow for indexing biotic interactions from scholarly literature
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species, etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 2 in Fig. 1).. We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as json to a GitHub repository, from where they could be accessed by GloBI.
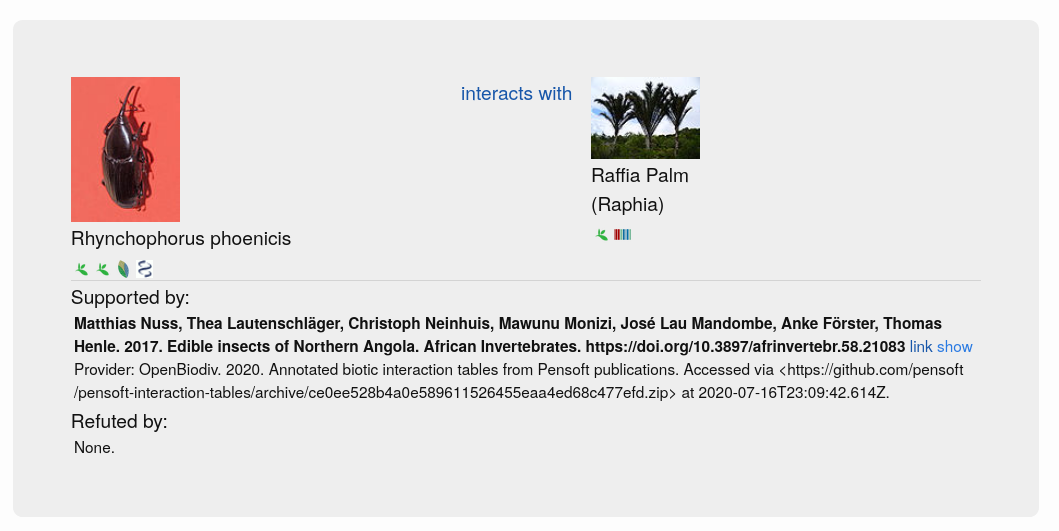
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ (Fig. 2) because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
Fig. 2. Example of a biotic interaction indexed by GloBI.
Examples of species interactions provided by OpenBiodiv and indexed by GloBI are available on GloBI’s website.
In the future we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6,993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 1 in Fig. 1). We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as JSON to a GitHub repository, from where they could be accessed by GloBI.
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
In the future, we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
References
Jorrit H. Poelen, James D. Simons and Chris J. Mungall. (2014). Global Biotic Interactions: An open infrastructure to share and analyze species-interaction datasets. Ecological Informatics. https://doi.org/10.1016/j.ecoinf.2014.08.005.
Additional Information
The work has been partially supported by the International Training Network (ITN) IGNITE funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 764840.