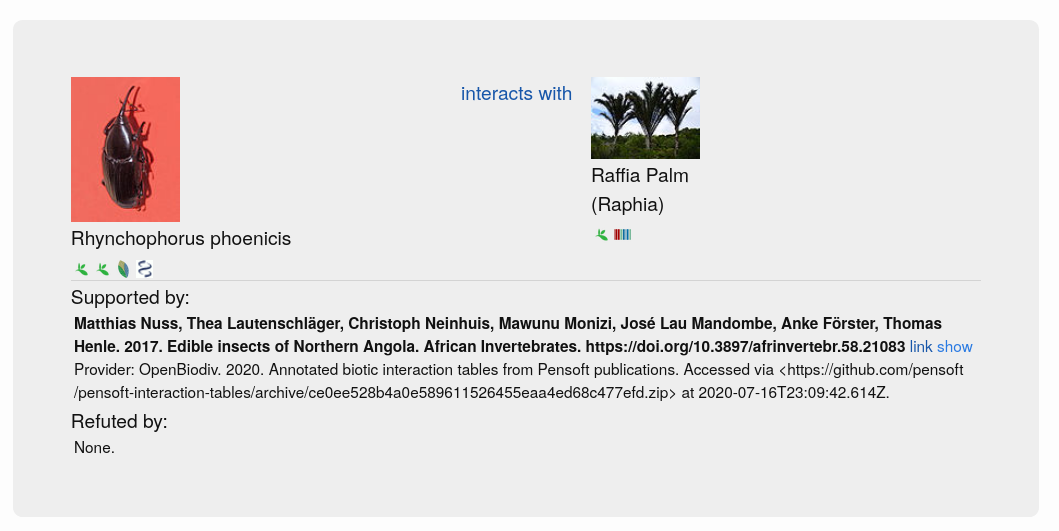
“The genera Chrysilla and Phintelloides revisited with the description of a new species (Araneae, Salticidae) using digital specimen DOIs and nanopublications” is the first scientific publication that uses digital specimen DOIs.

Linking data across collections
It is nothing new that our planet is facing a number of serious threats: climate change, biodiversity loss, pandemics… If you have been watching the news, all this is probably familiar to you. The wealth of data hosted in Natural history collections can contribute to finding a response to these challenges.Alas, today’s practices of working with collected bio- and geodiversity specimens lack some efficiency, thus limiting what our scientists can achieve.
In particular, there is a rather serious absence of linkages between specimen data. Sure, each specimen in a collection usually has its own catalogue ID that is unique within that collection, but the moment collections attempt to work with other collections -as they should in the face of planetary threats- problems start to arise because usually, each collection has its own way of identifying their data, thus leading to confusion.
Persistent identifiers: the DOIs
To avoid this problem, several initiatives have been launched in recent years to establish a globally accepted system of persistent identifiers (PIDs) that guarantee the “uniqueness” of collection specimens—physical or digital—over time.

You can think of a PID as a marker, an identifier that points at a single individual object and only one, differentiating it from any other in the world. You must have heard of acronyms such as ISBN or ORCID. Those are PIDs for books and individual scholars, respectively. For digital research content, the most widely used PID is the DOI (Digital Object Identifier), proposed by the DOI Foundation.
A DOI is an alphanumeric code that looks like this: 10.prefix/sufix
For example, if you type https://doi.org/10.15468/w6ubjx in your browser, you will reach the Royal Belgian Institute of Natural Sciences’s mollusk collection database, accessed through GBIF. This specific DOI will never point at anything else, and the identifier will remain the same in the future, even if changes occur in the content of this particular database.
DiSSCo and the DOIs
The Distributed System of Scientific Collections (DiSSCo) aims to provide a DOI for all individual digital specimens in European natural history collections. The point is not only to accurately identify specimens. That is, of course, crucial, but the DOI of a digital specimen provides a number of other advantages that are extremely interesting for DiSSCo and natural history collections in general. Among them, two are simply revolutionary.

Firstly, using DOIs allows linking the digital specimen to all other relevant information about the same specimen that might be hosted in other repositories (e.g. ecological data, genomic data, etc.). In creating this extended digital specimen that links different data types, digital specimen DOIs make a huge contribution to inter-institutional scientific work, filling the gap that is described at the beginning of this piece. Now scientists will be in a much better position to really exchange and link data across institutions.
Second, in contrast to most other persistent identifiers, the DOI of a digital specimen stores additional metadata (e.g. name, catalogue number) beyond the URL to which it redirects. This allows access to some information about the specimen without having to retrieve the full data object, i.e. without having to be redirected to the specimen HTML page. This metadata facilitates AI systems to quickly navigate billions of digital specimens and perform different automated work on them, saving us (humans) precious time.
Use of DOIs in publications
With all this in mind, it is easier to understand why being able to cite digital specimens in scholarly publications using DOIs is an important step. So far, the only DOIs that we could use in publications were those at the dataset level, not at the individual specimen level. In the example above, if a scientist were to publish an article about a specific type of bivalve in the Belgian collection, the only DOI that she or he would have available for citation in the article would be that of the entire mollusk database -containing hundreds or thousands of specimens- not the one of the specific oyster or scallop that might be the focus of the publication.

The publication in Biodiversity Data Journal about the Chrysilla and Phintelloides genera is the first of its kind and opens the door to citing not only dataset-level objects but also individual specimens in publications using DOIs. You can try it yourself: Hover over the DOIs that are cited in the publication and you will get some basic information that might save you the time of visiting the page of the institution where the specimen is. Click on it and you will be taken to DiSSCo’s sandbox -the future DiSSCover service- where you will find all the information about the digital specimen. There you will also be able to comment, annotate the specimen, and more, thus making science in a more dynamic and efficient way than until now.
A note about Christa Deeleman-Reinhold
At 94 years old, the Dutch arachnologist Christa Deeleman-Reinhold is not only one of the authors of the Chrysilla and Phintelloides article but also one of the most important arachnologists in the world. Born in 1930 on the island of Java -then part of the Dutch East Indies- Christa gained her PhD from Leiden University in 1978. Since then, she has developed a one-of-a-kind scientific career, mainly focused on spider species from South Asia. In her Forest Spiders of South East Asia (2001), Dr. Deeleman-Reinhold revised six spider families, describing 18 new genera and 115 new species. The Naturalis Biodiversity Center hosts the Christa Laetitia Deeleman-Reinhold collection, with more than 20,000 specimens.
Text and images provided by DiSSCo RI.
Research article:
Deeleman-Reinhold CL, Addink W, Miller JA (2024) The genera Chrysilla and Phintelloides revisited with the description of a new species (Araneae, Salticidae) using digital specimen DOIs and nanopublications. Biodiversity Data Journal 12: e129438. https://doi.org/10.3897/BDJ.12.e129438