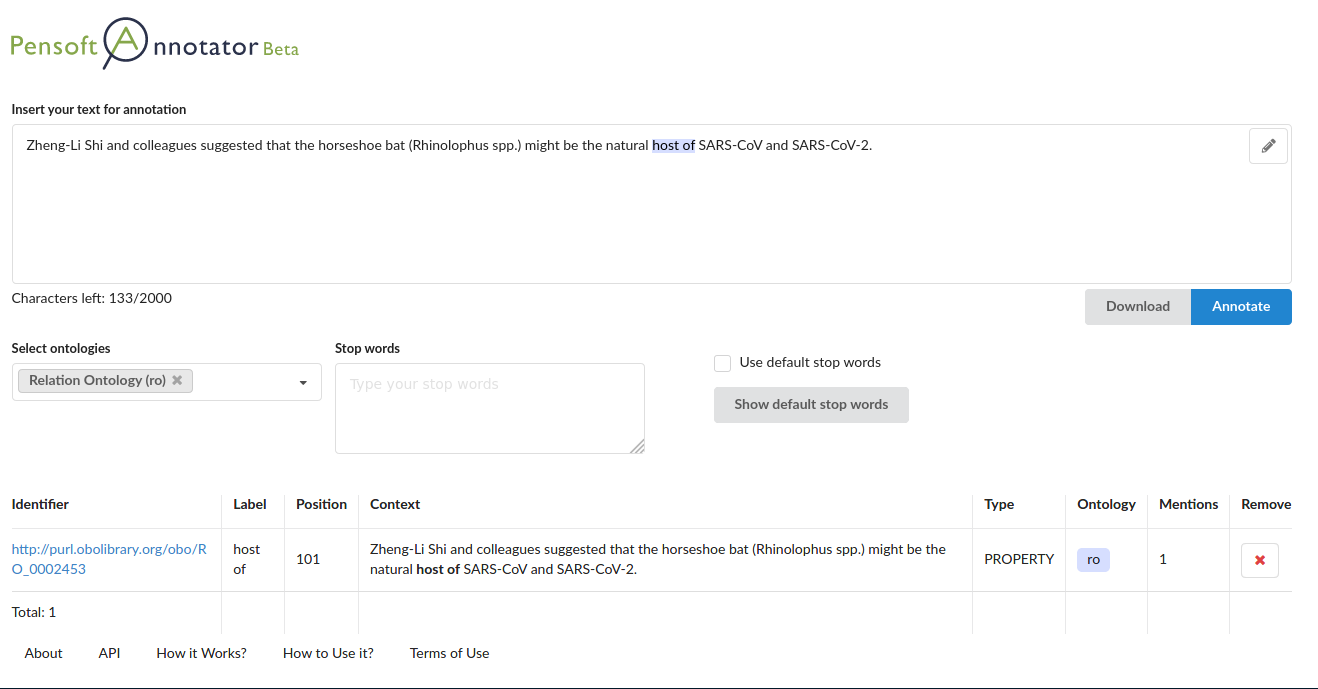
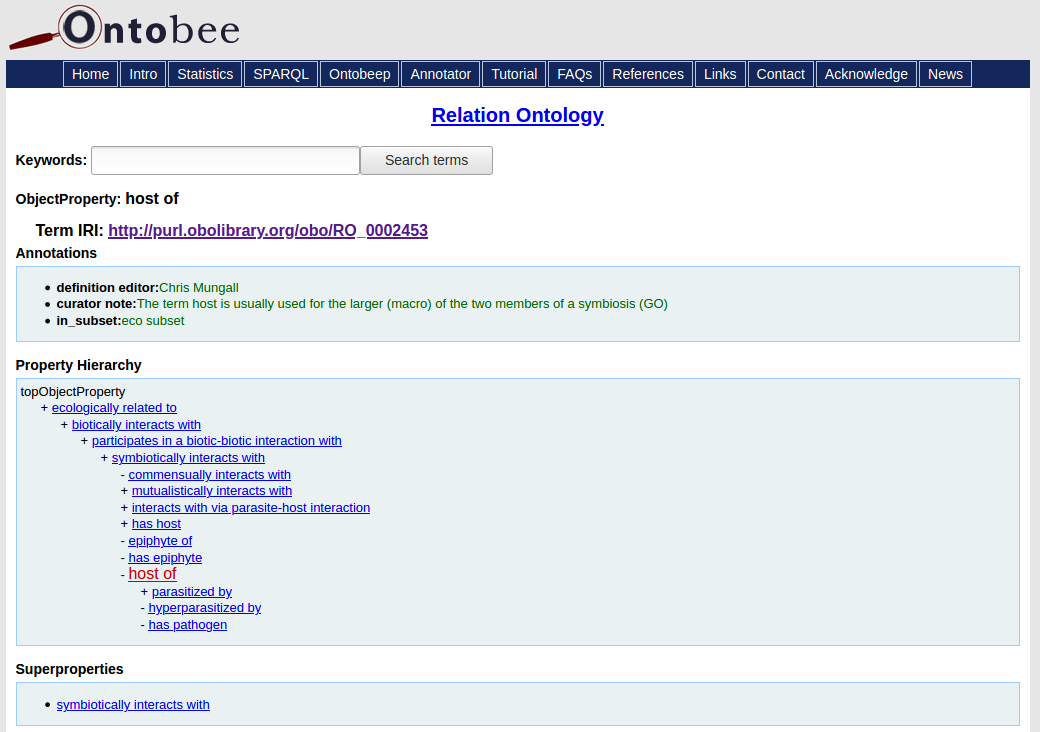
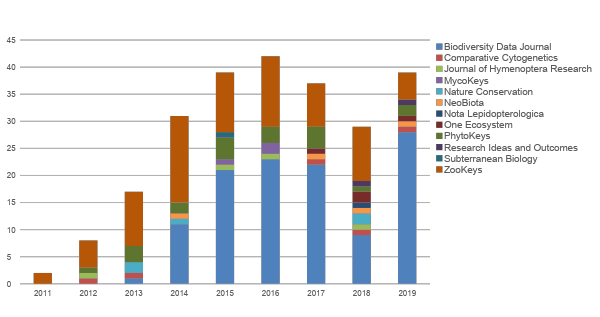
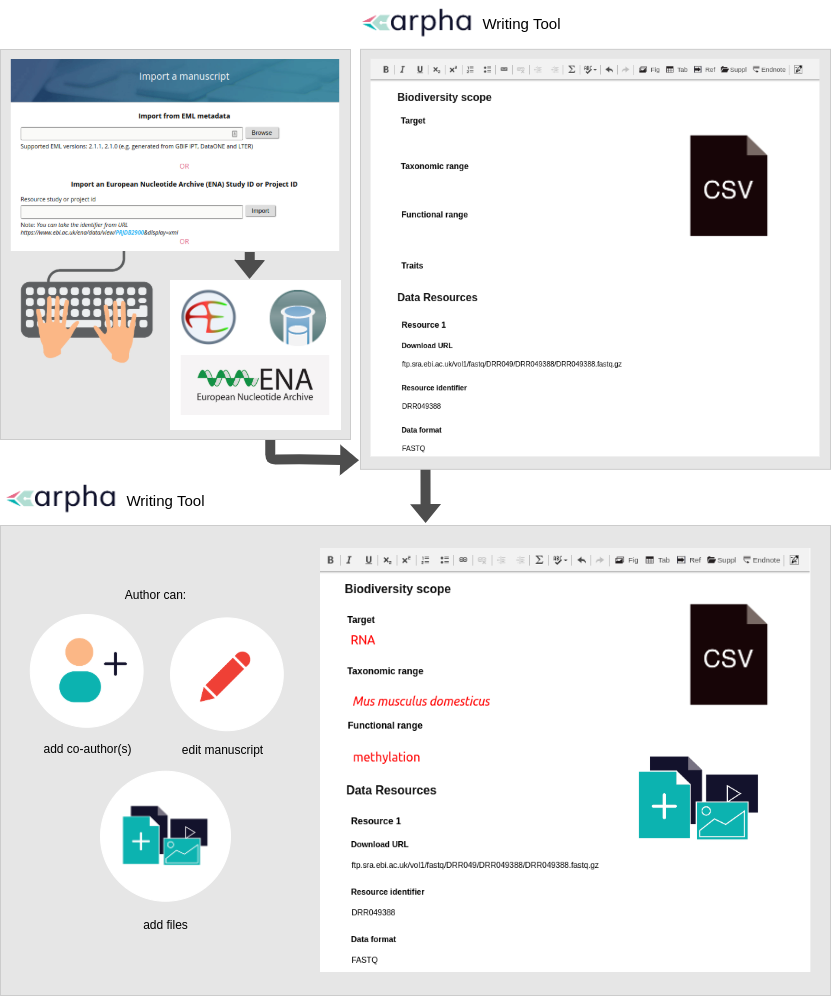
Between 17th and 21st October, about 400 scientists and experts took part in a hybrid meeting dedicated to the development, use and maintenance of biodiversity data, technologies, and standards across the world.
This year, the conference was hosted by Pensoft in collaboration with the National Museum of Natural History (Bulgaria) and the Institute of Biodiversity and Ecosystem Research at the Bulgarian Academy of Science. It ran under the theme “Stronger Together: Standards for linking biodiversity data”.
For the 37th time, the global scientific and educational association Biodiversity Information Standards (TDWG) brought together experts from all over the globe to share and discuss the latest developments surrounding biodiversity data and how they are being gathered, used, shared and integrated across time, space and disciplines.
This was the first time the event happened in a hybrid format. It was attended by 160 people on-site, while another 235 people joined online.

The conference abstracts, submitted by the event’s speakers ahead of the meeting, provide a sneak peek into their presentations and are all publicly available in the TDWG journal Biodiversity Information Science and Standards (BISS).
“It’s wonderful to be in the Balkans and Bulgaria for our Biodiversity Information and Standards (TDWG) 2022 conference! Everyone’s been so welcoming and thoughtfully engaged in conversations about biodiversity information and how we can all collaborate, contribute and benefit,”
said Deborah Paul, Chair of TDWG, a biodiversity informatics specialist and community liaison at the University of Illinois, Prairie Research Institute‘s Illinois Natural History Survey and also an active participant in the Society for the Preservation of Natural History Collections (SPNHC), the Entomological Collections Network (ECN), ICEDIG, the Research Data Alliance (RDA), and The Carpentries.
“Our TDWG mission is to create, maintain and promote the use of open, community-driven standards to enable sharing and use of biodiversity data for all,”
she added.

“We are proud to have been selected to be the hosts of this year’s TDWG annual conference and are definitely happy to have joined and observed so many active experts network and share their know-how and future plans with each other, so that they can collaborate and make further progress in the way scientists and informaticians work with biodiversity information,”
said Pensoft’s founder and CEO Prof. Lyubomir Penev.
“As a publisher of multiple globally renowned scientific journals and books in the field of biodiversity and ecology, at Pensoft we assume it to be our responsibility to be amongst the first to implement those standards and good practices, and serve as an example in the scholarly publishing world. Let me remind you that it is the scientific publications that present the most reliable knowledge the world and science has, due to the scrutiny and rigour in the review process they undergo before seeing the light of day,”
he added.
***
In a nutshell, the main task and dedication of the TDWG association is to develop and maintain standards and data-sharing protocols that support the infrastructures (e.g., The Global Biodiversity Information Facility – GBIF), which aggregate and facilitate use of these data, in order to inform and expand humanity’s knowledge about life on Earth.

It is the goal of everyone volunteering their time and expertise to TDWG to enable the scientists interested in the world’s biodiversity to do their work efficiently and in a manner that can be understood, shared and reused by others. After all, biodiversity data underlie everything we know about the natural world.
If there are optimised and universal standards in the way researchers store and disseminate biodiversity data, all those biodiversity scientists will be able to find, access and use the knowledge in their own work much more easily. As a result, they will be much better positioned to contribute new knowledge that will later be used in nature and ecosystem conservation by key decision-makers.
On Monday, the event opened with welcoming speeches by Deborah Paul and Prof. Lyubomir Penev in their roles of the Chair of TDWG and the main host of this year’s conference, respectively.
The opening ceremony continued with a keynote speech by Prof. Pavel Stoev, Director of the Natural History Museum of Sofia and co-host of TDWG 2022.

He walked the participants through the fascinating biodiversity of Bulgaria, but also the worrying trends in the country associated with declining taxonomic expertise.
He finished his talk with a beam of hope by sharing about the recently established national unit of DiSSCo, whose aim – even if a tad too optimistic – is to digitise one million natural history items in four years, of which 250,000 with photographs. So far, one year into the project, the Bulgarian team has managed to digitise more than 32,000 specimens and provide images to 10,000 specimens.
The plenary session concluded with a keynote presentation by renowned ichthyologist and biodiversity data manager Dr. Richard L. Pyle, who is also a manager of ZooBank – the key international database for newly described species.

In his talk, he highlighted the gaps in the ways taxonomy is being used, thereby impeding biodiversity research and cutting off a lot of opportunities for timely scientific progress.
“There are simple things we can do to change how we use taxonomy as a tool that would dramatically improve our ability to conduct science and understand biodiversity. There is enormous value and utility within existing databases around the world to understand biodiversity, how threatened it is, what impacts human activity has (especially climate change), and how to optimise the protection and preservation of biodiversity,”
he said in an interview for a joint interview by the Bulgarian News Agency and Pensoft.
“But we do not have easy access to much of this information because the different databases are not well integrated. Taxonomy offers us the best opportunity to connect this information together, to answer important questions about biodiversity that we have never been able to answer before. The reason meetings like this are so important is that they bring people together to discuss ways of using modern informatics to greatly increase the power of the data we already have, and prioritise how we fill the gaps in data that exist. Taxonomy, and especially taxonomic data integration, is a very important part of the solution.”
Pyle also commented on the work in progress at ZooBank ten years into the platform’s existence and its role in the next (fifth) edition of the International Code of Zoological Nomenclature, which is currently being developed by the International Commission of Zoological Nomenclature (ICZN).
“We already know that ZooBank will play a more important role in the next edition of the Code than it has for these past ten years, so this is exactly the right time to be planning new services for ZooBank. Improvements at ZooBank will include things like better user-interfaces on the web to make it easier and faster to use ZooBank, better data services to make it easier for publishers to add content to ZooBank as part of their publication workflow, additional information about nomenclature and taxonomy that will both support the next edition of the Code, and also help taxonomists get their jobs done more efficiently and effectively. Conferences like the TDWG one are critical for helping to define what the next version of ZooBank will look like, and what it will do.”
***
During the week, the conference participants had the opportunity to enjoy a total of 140 presentations; as well as multiple social activities, including a field trip to Rila Monastery and a traditional Bulgarian dinner.

While going about the conference venue and field trip localities, the attendees were also actively uploading their species observations made during their stay in Bulgaria on iNaturalist in a TDWG2022-dedicated BioBlitz. The challenge concluded with a total of 635 observations and 228 successfully identified species.

***
In his interview for the Bulgarian News Agency and Pensoft, Dr Vincent Smith, Head of the Informatics Division at the Natural History Museum, London (United Kingdom), co-founder of DiSSCo, the Distributed System of Scientific Collections, and the Editor-in-Chief of Biodiversity Data Journal, commented:
“Biodiversity provides the support systems for all life on Earth. Yet the natural world is in peril, and we face biodiversity and climate emergencies. The consequences of these include accelerating extinction, increased risk from zoonotic disease, degradation of natural capital, loss of sustainable livelihoods in many of the poorest yet most biodiverse countries of the world, challenges with food security, water scarcity and natural disasters, and the associated challenges of mass migration and social conflicts.
Solutions to these problems can be found in the data associated with natural science collections. DiSSCo is a partnership of the institutions that digitise their collections to harness their potential. By bringing them together in a distributed, interoperable research infrastructure, we are making them physically and digitally open, accessible, and usable for all forms of research and innovation.
At present rates, digitising all of the UK collection – which holds more than 130 million specimens collected from across the globe and is being taken care of by over 90 institutions – is likely to take many decades, but new technologies like machine learning and computer vision are dramatically reducing the time it will take, and we are presently exploring how robotics can be applied to accelerate our work.”

In his turn, Dr Donat Agosti, CEO and Managing director at Plazi – a not-for-profit organisation supporting and promoting the development of persistent and openly accessible digital taxonomic literature – said:
“All the data about biodiversity is in our libraries, that include over 500 million pages, and everyday new publications are being added. No person can read all this, but machines allow us to mine this huge, very rich source of data. We do not know how many species we know, because we cannot analyse with all the scientists in this library, nor can we follow new publications. Thus, we do not have the best possible information to explore and protect our biological environment.”

***
At the closing plenary session, Gail Kampmeier – TDWG Executive member and one of the first zoologists to join TDWG in 1996 – joined via Zoom to walk the conference attendees through the 37-year history of the association, originally named the Taxonomic Databases Working Group, but later transformed to Biodiversity Information Standards, as it expanded its activities to the whole range of biodiversity data.
“While this presentation is about TDWG’s history as an organisation, its focus will be on the heart of TDWG: its people. We would like to show how the organisation has evolved in terms of gender balance, inclusivity actions, and our engagement to promote and enhance diversity at all levels. But more importantly, where do we—as a community—want to go in the future?”,
reads the conference abstract of her colleague at TDWG Dr Visotheary Ung (CNRS-MNHN) and herself.
Then, in the final talk of the session, Deborah Paul took to the stage to present the progress and key achievements by the association from 2022.
She gave a special shout-out to the TDWG journal: Biodiversity Information Science and Standards (BISS), where for the 6th consecutive year, the participants of the annual conference submitted and published their conference abstracts ahead of the event.

Launched in 2017 on the Pensoft’s publishing platform ARPHA, the journal provides the quite unique and innovative opportunity to have both abstracts and full-length research papers published in a modern, technologically-advanced scholarly journal. In her speech, Deborah Paul reminded that BISS journal welcomes research articles that demonstrate the development or application of new methods and approaches in biodiversity informatics in the form of case studies.
Amongst the achievements of TDWG and its community, a special place was reserved for the Horizon 2020-funded BiCIKL project (abbreviation for Biodiversity Community Integrated Knowledge Library), involving many of the association’s members.
Having started in 2021, the 3-year project, coordinated by Pensoft, brings together 14 partnering institutions from 10 countries, and 15 biodiversity under the common goal to create a centralised place to connect all key biodiversity data by interlinking a total of 15 research infrastructures and their databases.

In fact, following the week-long TDWG 2022 conference in Sofia, a good many of the participants set off straight for another Bulgarian city and another event hosted by Pensoft. The Second General Assembly of BiCIKL took place between 22nd and 24th October in Plovdiv.
***
You can also explore highlights and live tweets from TDWG 2022 on Twitter via #TDWG2022.