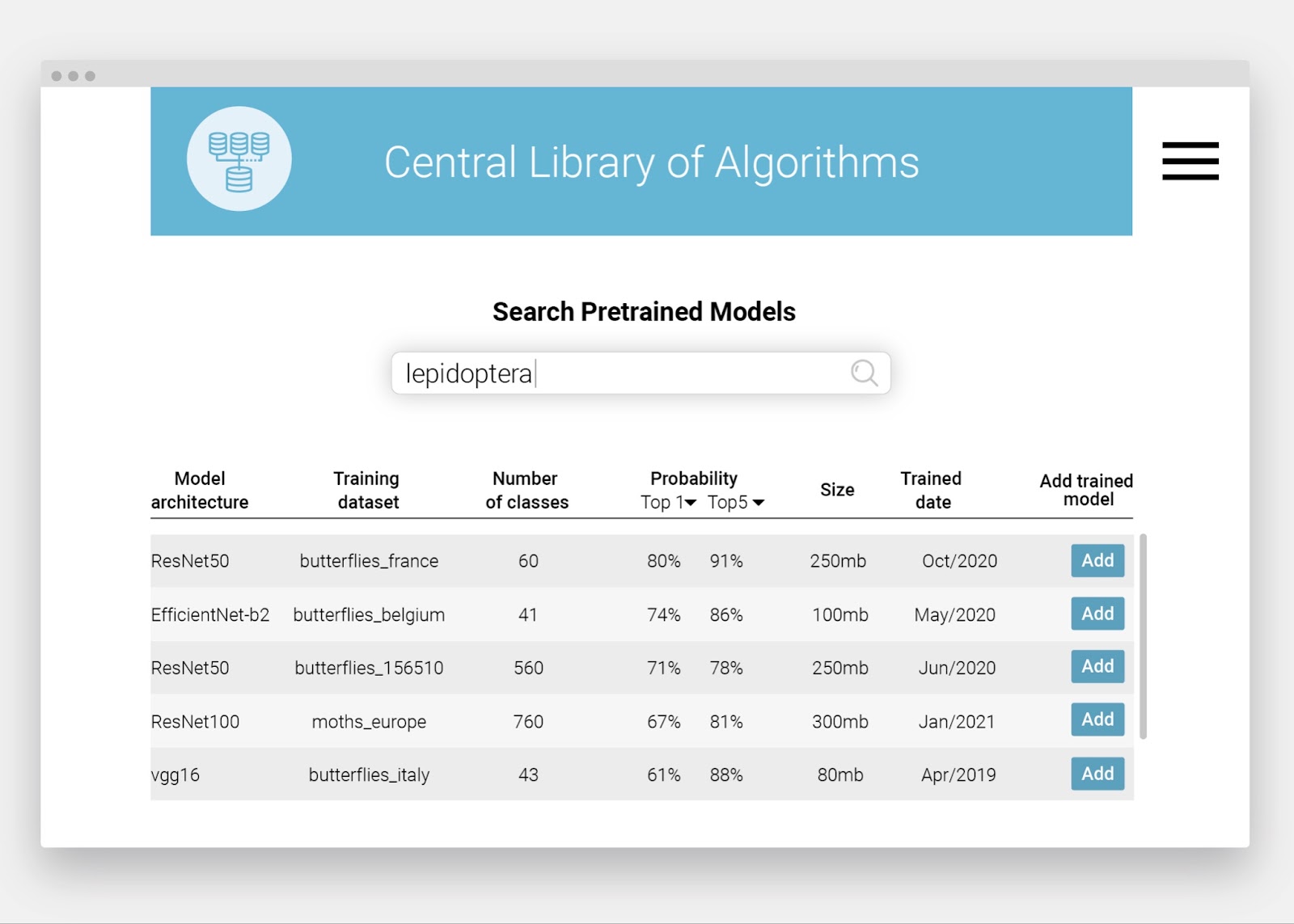
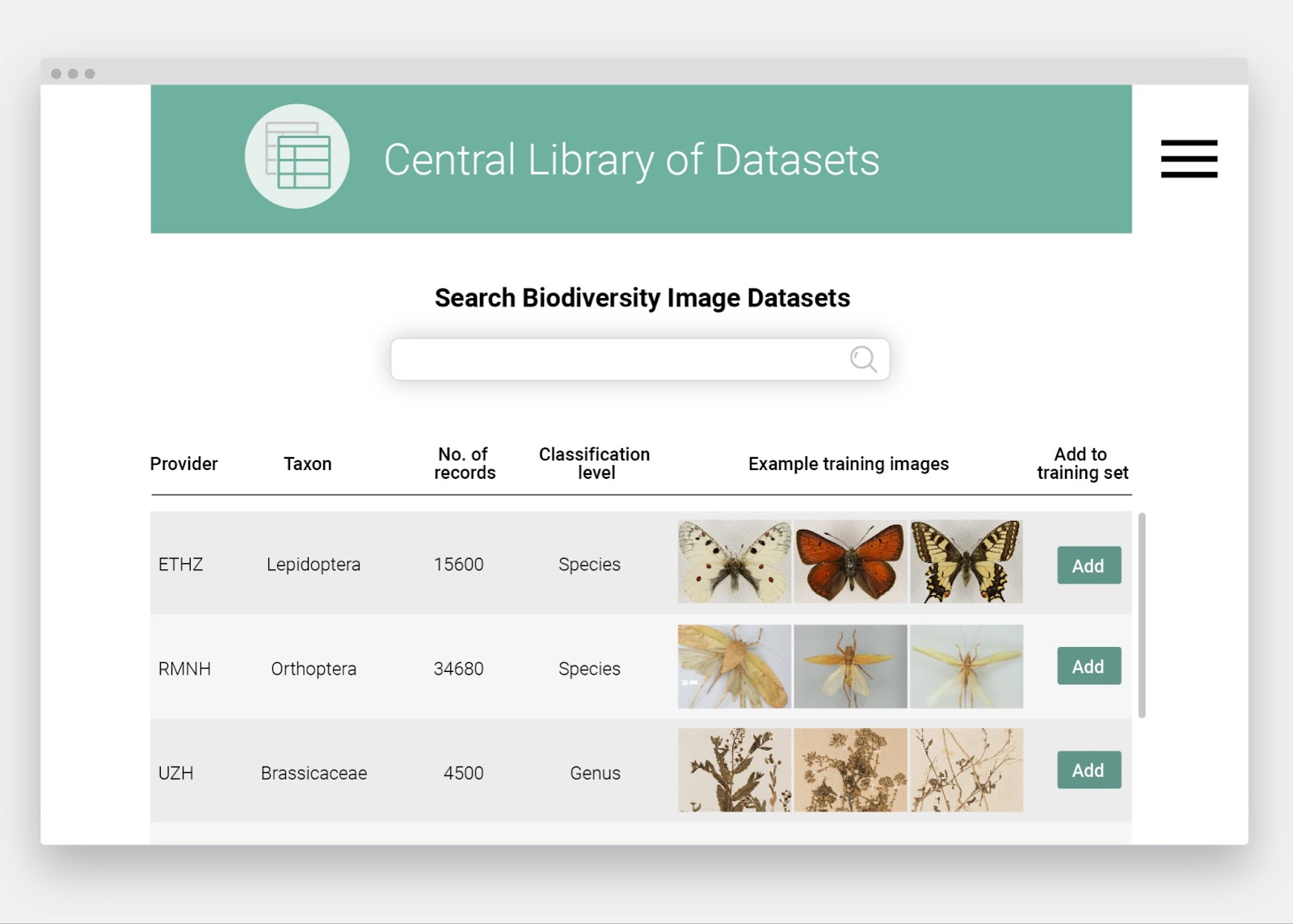
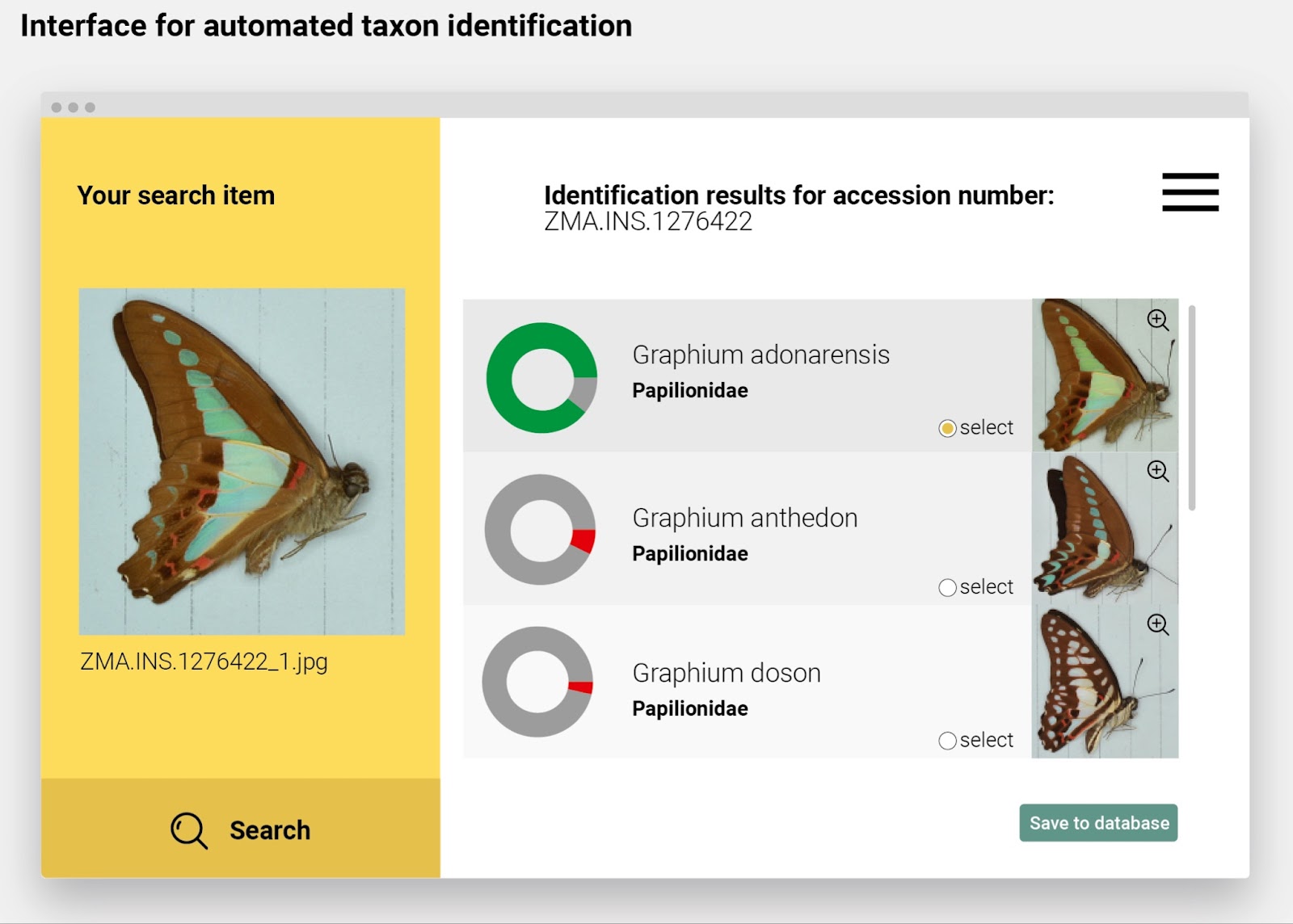
Photo by Michelle Kuo (c).
There are over three billion specimens and cultural objects housed in natural history collections around the world—things like fossils, dried plants, and pinned insects. Close to forty million of them are at the Field Museum in Chicago, mostly behind the scenes in a vast library documenting life on Earth.
These collections are used by scientists at the museum and around the world to explore what lived where and when and how living things have changed over time.
However, much of the information about these collections is hard to access, because there are no digital records of it.

Photo by John Weinstein.
Community scientists volunteering at the Field Museum who have formed a Collections Club are helping to solve this problem.
So far, they’ve digitized more than a quarter-million collections items and records.
The Field Museum recently published a scientific paper in the journal Natural History Collections and Museumomics about the work of these community scientists as a record of what they’ve accomplished and as a blueprint for other natural history collections to work with volunteers in their communities.
By the way, the Field Museum prefers to use the term “community scientists” rather than the synonymous “citizen scientists”, in order to emphasize that the work is a community effort. They also wish to be inclusive of all volunteers regardless of their citizenship status. Several community scientists are in fact listed as co-authors of the new.
“What’s remarkable is how the enthusiasm has sustained and grown,” says Matt von Konrat, Head of Botanical Collections at the Field Museum and the lead author of the paper.
“Our surveys show that participants are increasingly motivated by altruistic reasons—they want to contribute to science and support the museum’s mission.
The fact that many of our volunteers are now co-authors on this scientific paper shows how far we’ve come in breaking down traditional barriers between professional scientists and community researchers.”
Since 2015, over 3,800 volunteers have contributed more than 13,500 hours helping to digitize, catalog, and preserve specimens—equivalent to nearly eight years of full-time work. Their efforts have processed over 300,000 scientific specimens, records and objects, making valuable data accessible to researchers worldwide.
“At its core, the Field Museum strives to connect people to the natural world and the human story. The Collections Club reflects this mission by transforming over 300,000 specimens into a digital and physical legacy, providing scientists across the globe with the data they need to understand and protect our biodiversity,”
says von Konrat.
The program’s success has been driven by both in-person and virtual engagement opportunities, particularly through initiatives like WeDigBio (Worldwide Engagement for Digitizing Biocollections) and the Field Museum’s Collections Club. During the height of the COVID-19 pandemic, the program successfully pivoted to virtual participation, maintaining strong community connections when they were needed most.

Photo by Robert Salm.
“There were so many dynamics working against us during COVID: sporadic closures and re-openings in Chicago of restaurants, parks, museums, and businesses. The ability for me to continue cataloging and repackaging specimens for the Field Museum was the only constant and sane reference for me; days of the week and working hours had no boundaries. I don’t think any other museum in Chicago had volunteers as dedicated as the Field Museum, and I was happy to be part of the experience.”
says Robert Salm, a volunteer in the Field Museum’s botanical collections.

Photo by Erryn Blake.
The impact extends beyond adults to inspire the next generation of scientists. In one touching example highlighted in the paper, two fifth-grade students were so inspired by their participation that they created their own “Mobile Museum” to share natural history with other young people. These young scientists are among the paper’s co-authors, demonstrating the program’s commitment to elevating youth voices in science.
According to the Blake family, whose children Winnie and Gwen created the Mobile Museum, “Collections Club makes science tangible, accessible, and real. It shows students that away from a conventional classroom setting, where science can feel like a chore, this program helps in contributing to a global community benefiting countless research efforts. The Mobile Museum was created as an extension of Collections Club to bring the passion for science to kids of all ages.”

Photo by Erryn Blake.
The Field Museum’s model demonstrates how institutions of any size can engage their communities in meaningful scientific work. The paper provides detailed recommendations and checklists for other organizations looking to develop similar programs.
“This success story wouldn’t have been possible without Chicago’s vibrant media landscape helping us reach new audiences,” said von Konrat.
“From local blogs to major television networks, each platform played a vital role in building this community of scientists.
We hope this model inspires other museums and research institutions to build similar programs.
Together, we are fostering a shared legacy that underscores the value of biodiversity and scientific heritage for future generations.”
The full research paper, published in the journal Natural History Collections and Museomics, provides a comprehensive overview of the program’s development and impact over nearly a decade of community engagement, while setting a new standard for inclusive scientific authorship.
For more information about getting involved in community science at the Field Museum, visit https://www.fieldmuseum.org/activity/collections-club—the next event is coming up in January 2025!
Stay up-to-date with publications and news from the Natural History Collections and Museomics (NHCM) journal on social media on BlueSky, X and Facebook.
Research article:
von Konrat M, Rodriguez Y, Bailey C, Gwilliam III GF, Christian C, Aguero B, Ahn J, Albion Z, Allen JR, Bailey C, Blake E, Blake W, Blake G, Briscoe L, Budke JM, Campbell T, Chansler M, Clark D, Delapena R, Denslow M, Dodinval D, Dux E, Ellis S, Ellwood E, Enkhbayer M, Ens B, Evans NM, Fabian A, Ferguson A, Gaswick W, Golembiewski K, Grant S, Hancock L, Hansen K, Janney B, Jones J, Kachian Z, Kawasaki ML, Kellum K, Leek O, Lichamer A, Maier C, Mast A, Martinec JL, Mayer P, Mladek M, Nadhifah A, Neefus C, Nodulman M, Oliver M, Overberg K, Townsend Peterson A, Qazi-Lampert A, Rothfels C, Ryan ZA, Salm R, Schreiner D, Schreiner M, Tepe EJ, Turcatel M, Vega A, Wade H, Webbink K, Weinand D, Widhelm T, Zwingelberg M (2024) From spectators to stewards: Transforming public involvement in natural history collections. Natural History Collections and Museomics 1: 1-33. https://doi.org/10.3897/nhcm.1.138247
News announcement originally published by the Field Museum. Republished with permission.