Pensoft is among the first signatories dedicated to fully leveraging biodiversity knowledge from research publications within an open science framework by 2035
Some of the world’s leading institutions, experts and scientific infrastructures relating to biodiversity information are uniting around a new 10-year roadmap to ‘liberate’ data presently trapped in research publications.
The initiative aims to enable the creation of a ‘Libroscope’ – a mechanism for unlocking and linking data from scientific literature to support understanding of biodiversity, as the microscope and telescope previously revolutionized science. The plan largely builds on existing technology and workflows, and does not rely on construction of a new technical infrastructure.
The proposals result from a symposium involving 51 experts from 10 countries held in August 2024 at the 7th-century monastery at Disentis in the Swiss Alps, supported financially by the Arcadia Fund. The symposium was a 10-year follow-up to the 2014 meeting at Meise Botanic Garden in Belgium, which led to the Bouchout Declaration on open biodiversity knowledge management. The Disentis meeting evaluated progress since then, and identified priorities for the decade ahead.
Group photo from the Disentis meeting (Switzerland, August 2024).
While acknowledging major advances in the sharing and use of open biodiversity data, the participants noted that accessing data within research publications is often very cumbersome, with databases disconnected from each other and from the source literature. Liberating and linking data from such publications – estimated to encompass more than 500 million total pages – would represent a compelling mission for the next decade.
A roadmap for staged action over the next decade was agreed by the symposium participants, with the following vision: “By 2035, the power of biodiversity knowledge from research publications will be fully leveraged within an open science framework, including unencumbered data discovery, access, and re-use across scientific disciplines and policy applications.”
The ‘Disentis Roadmap’, further developed following the symposium, and now released publicly, has already been signed by 26 institutions and a further 46 individual experts on five continents – among them major natural history collections such as Meise Botanic Garden, Botanic Garden and Botanical Museum Berlin, the National Museum of Natural History in Paris, and Royal Botanic Gardens, Kew; infrastructures such as the Global Biodiversity Information Facility (GBIF), Biodiversity Heritage Library (BHL), Catalogue of Life, LifeWatch ERIC and the Swiss Institute of Bioinformatics (SIB); journal publishers such as Pensoft Publishers and the European Journal of Taxonomy; research institutions such as Chinese Academy of Sciences and the Senckenberg Society for Nature Research; and networks such as TDWG Biodiversity Information Standards and Consortium of European Taxonomic Facilities (CETAF). See the full list of signatories here.
The roadmap remains open for further signatures, ahead of the launch of an action plan at the Living Data conference in Bogotá, Colombia in October 2025. The original signatories hope that a much broader group of institutions and individuals, across global regions and disciplines, will join the initiative and help to shape implementation of its vision. Engagement of funders will also be critical to realize its objectives.
The specific goals of the roadmap are that by 2035:
All major public biodiversity research funders and academic publishers will encourage and enable publication of data adhering to the FAIR principles (findable, accessible, interoperable and reusable);
Biodiversity-focussed publications will be accessible in machine-actionable formats, with all non-copyrightable parts of articles flowing into public data repositories;
Published research on biodiversity will be ‘fully AI-ready’, that is openly available for AI training and properly labelled for ingestion by machine-learning modelled, within appropriate ethical and legal frameworks;
Dedicated funding from research and infrastructure grants will be reserved for ensuring access to biodiversity data and knowledge.
“We finally have a chance to make a quantum leap in understanding and monitoring biodiversity, by leveraging the power of digital technologies, and combining modern genomic methods with the vast amount of research data published daily and currently stuck in the publication prison. The ‘Libroscope’ will help to explore the universe of existing knowledge, accumulated over hundreds of years, and bring it to the forefront of developments in the digital age, helping nature and people across the globe.”
commented Donat Agosti of the Swiss organization Plazi, who convened the Disentis symposium.
A recent demonstration of the principles of the ‘Libroscope’ was the launch of data portals for the European Journal of Taxonomy (EJT) and the Biodiversity Data Journal, as part of the GBIF hosted portal programme. The new portals showcase the data contained within taxonomic literature published by the journals, making use of the workflow originally developed by Plazi and partners to extract re-usable data from articles traditionally locked in static PDF files. Once created, these data objects then flow into platforms such as GBIF, Catalogue of Life, ChecklistBank and the BiodiversityPMC, and are stored in the Biodiversity Literature Repository at Zenodo hosted by CERN. This process enables data on new species and the location of related specimens cited in the literature to be openly accessible in near-real time, and available for long-term access.
The newly launched Biodiversity Data Journal data portal is part of the GBIF-hosted portal programme. It showcase the data contained within taxonomic literature published by the journal.
“As a publisher of dozens of renowned academic journals in the field of biodiversity and systematics with experience in technology development, at Pensoft, we have always recognised the key role of academic publishers in scholarly communication. It’s not only about publishing the latest research. Above all, it’s about putting scientific work in the hands of those who need it: be it future researchers, policy-makers or their AI-powered assistants. Now that the Disentis roadmap is already a fact, we hope that many others will also join us on this ambitious journey to open up the knowledge we have today for those who will need it tomorrow.”
said Prof. Dr. Lyubomir Penev, founder and CEO at Pensoft, who attended the Disentis symposium.
“By repositioning scientific publications as an essential part of the research cycle, the Disentis Roadmap encourages publishers and the scientific community to move beyond open access towards FAIR access. Proactively ensuring data quality and dissemination is the core mission of the European Journal of Taxonomy. In this way, EJT enhances the immediate discoverability and usability of the taxonomic information it publishes, making it more valuable to the scientific community as a whole. Adherence to the Disentis vision marks a crucial step in the liberation and enrichment of knowledge about biodiversity.”
said Laurence Bénichou, founder and liaison officer of the European Journal of Taxonomy.
The Chief Executive Officer of Meise Botanic Garden, Steven Dessein, who attended the Disentis Symposium, commented:
“Meise Botanic Garden fully supports the Disentis Roadmap, which builds on the foundation laid by the Bouchout Declaration. Open biodiversity data is essential to tackling today’s pressing environmental challenges, from biodiversity loss to climate change. By ensuring research publications become more accessible and interconnected, this roadmap represents a critical step toward harnessing biodiversity knowledge for science, policy, and conservation.”
Christophe Déssimoz, Executive Director of the SIB Swiss Institute of Bioinformatics, another signatory of the Disentis Roadmap, added:
“We have long championed the principles of open, structured, and interoperable data to advance life sciences. The Disentis Roadmap applies these same principles to biodiversity knowledge, ensuring that critical data is not just available, but truly actionable for research, policy, and conservation.”
The director of the Botanic Garden and Botanical Museum of Berlin, Thomas Borsch, noted that more than any other branch of science, taxonomic research depended on the machine-actionable availability of biodiversity data from the literature:
“The ‘Libroscope’ postulated in the Disentis Roadmap will enable a new generation of research workflows through its interoperable approach,” said Professor Borsch. “This will be very helpful to address pressing issues in biodiversity research and in particular to improve the use of quality information on organisms in national and global assessments.”
The chief scientist of the national museum of natural history in Paris (MNHN) said:
“We, like all similar museums and taxonomic institutions, are focussed on linking taxonomic and collection data with digital reproductions and molecular information to create the ‘extended digital specimen.’ However, the potential of taxonomic publications and text mining should not be underestimated either. On the contrary, it is a smart and accessible way to dig into scientific publications so as to retrieve, link and consolidate, research data of great relevance to many disciplines. This is why our institution fully supports the Disentis initiative.”
Christos Arvanitidis, CEO of the Biodiversity and Ecosystem e-Science Infrastructure LifeWatch ERIC, commented:
“LifeWatch ERIC is proud to be part of this initiative, as providing access and support to biodiversity and ecosystem data is fully aligned with our mission. The Disentis Roadmap opens up new opportunities for our research infrastructure to help make what science has provided us accessible and usable, and to improve the FAIRness of data for research and science-based policy.”
Tim Robertson, deputy director and head of informatics at the Global Biodiversity Information Facility (GBIF), who also attended the Disentis meeting added:
“We’re excited to see the results from Disentis partners like Plazi, BHL, Pensoft and the European Journal of Taxonomy who are focussed on liberating data connected with scientific publications,” said . “GBIF will continue to do our part to improve the standards, tools and services that help expand both the benefits and the impact of FAIR and open data on biodiversity science and policy.”
Olaf Bánki, Executive Director of the Catalogue of Life, commented:
“We call out to the scientific community, especially the younger generation, to join our effort in unlocking biodiversity data from literature. Actionable biodiversity and taxonomic data from digitized literature contributes to creating an index of all described organisms of all life on earth. We need such data to tackle and understand the current biodiversity crisis.”
Welcomed are taxonomic and other biodiversity-related research articles, which demonstrate the advantages and novel approaches in accessing and (re-)using linked biodiversity data
The EU-funded project BiCIKL (Biodiversity Community Integrated Knowledge Library) will support free of charge publications*submitted to the dedicated topical collection: “Linking FAIR biodiversity data through publications: The BiCIKL approach” in the Biodiversity Data Journal, demonstrating advanced publishing methods of linked biodiversity data, so that they can be easily harvested, distributed and re-used to generate new knowledge.
BiCIKL is dedicated to building a new community of key research infrastructures, researchers and citizen scientists by using linked FAIR biodiversity data at all stages of the research lifecycle, from specimens through sequencing, imaging, identification of taxa, etc. to final publication in novel, re-usable, human-readable and machine-interpretable scholarly articles.
Achieving a culture change in how biodiversity data are being identified, linked, integrated and re-used is the mission of the BiCIKL consortium. By doing so, BiCIKL is to help increase the transparency, trustworthiness and efficiency of the entire research ecosystem.
The new article collection welcomes taxonomic and other biodiversity-related research articles, data papers, software descriptions,and methodological/theoretical papers. These should demonstrate the advantages and novel approaches in accessing and (re-)using linked biodiversity data.
To be eligible for the collection, a manuscript must comply with at least two of the conditions listed below. In the submission form, the author needs tospecify the condition(s) applicable to the manuscript. The author should provide the explanation in a cover letter, using the Notes to the editor field.
All submissions must abide by the community-agreed standards for terms, ontologies and vocabularies used in biodiversity informatics.
Conditions for publication in the article collection:
The authors are expected to use explicit Globally Unique Persistent and Resolvable Identifiers (GUPRI) or other persistent identifiers (PIDs), where such are available, for the different types of data they use and/or cite in the manuscripts (specimens IDs, sequence accession numbers, taxon name and taxon treatment IDs, image IDs, etc.)
Global taxon reviews in the form of “cyber-catalogues” are welcome if they contain links of the key data elements (specimens, sequences, taxon treatments, images, literature references, etc.) to their respective records in external repositories. Taxon names in the text should not be hyperlinked. Instead, under each taxon name in the catalogue, the authors should add external links to, for example, Catalogue of Life, nomenclators (e.g. IPNI, MycoBank, Index Fungorum, ZooBank), taxon treatments in Plazi’s TreatmentBank or other relevant trusted resources.
Taxonomic papers (e.g. descriptions of new species or revisions) must contain persistent identifiers for the holotype, paratypes and at least most of the specimens used in the study.
Specimen records that are used for new taxon descriptions or taxonomic revisions and are associated with a particular Barcode Identification Number (BIN) or Species Hypothesis (SH) should be imported directly from BOLD or PlutoF, respectively, via the ARPHA Writing Tool data-import plugin.
More generally, individual specimen records used for various purposes in taxonomic descriptions and inventories should be imported directly into the manuscript from GBIF, iDigBio, or BOLD via the ARPHA Writing Tool data-import plugin.
In-text citations of taxon treatments from Plazi’s TreatmentBank are highly welcome in any taxonomic revision or catalogue. The in-text citations should be hyperlinked to the original treatment data at TreatmentBank.
Hyperlinking other terms of importance in the article text to their original external data sources or external vocabularies is encouraged.
Tables that list gene accession numbers, specimens and taxon names, should conform to the Biodiversity Data Journal’s linked data tables guidelines.
Theoretical or methodological papers on linking FAIR biodiversity data are eligible for the BiCIKL collection if they provide real examples and use cases.
Data papers or software descriptions are eligible if they use linked data from the BiCIKL’s partnering research infrastructures, or describe tools and services that facilitate access to and linking between FAIR biodiversity data.
Articles that contain nanopublications created or added during the authoring process in Biodiversity Data Journal. A nanopublication is a scientifically meaningful assertion about anything that can be uniquely identified and attributed to its author and serve to communicate a single statement, for example biotic relationship between taxa, or habitat preference of a taxon. The in-built workflow ensures the linkage and its persistence, while the information is simultaneously human-readable and machine-interpretable.
Manuscripts that contain or describe any other novel idea or feature related to linked or semantically enhanced biodiversity data will be considered too.
We recommend authors to get acquainted with these two papers before they decide to submit a manuscript to the collection:
Here are several examples of research questions that might be explored using semantically enriched and linked biodiversity data:
(1) How does linking taxon names or Operational Taxonomic Units (OTUs) to related external data (e.g. specimen records, sequences, distributions, ecological & bionomic traits, images) contribute to a better understanding of the functions and regional/local processes within faunas/floras/mycotas or biotic communities?
(2) How could the production and publication of taxon descriptions and inventories – including those based mostly on genomic and barcoding data – be streamlined?
(3) How could general conclusions, assertions and citations in biodiversity articles be expressed in formal, machine-actionable language, either to update prior work or express new facts (e.g. via nanopublications)?
(4) How could research data and narratives be re-used to support more extensive and data-rich studies?
(5) Are there other taxon- or topic-specific research questions that would benefit from richer, semantically enhanced FAIR biodiversity data?
Once published, specimen records data are being exported in Darwin Core Archive to GBIF.
The data and taxon treatments are also exported to several additional data aggregators, such as TreatmentBank, the Biodiversity Literature Repository, and SiBILS amongst others. The full-text articles are also converted to Linked Open Data indexed in the OpenBiodiv Knowledge Graph.
All articles will need to acknowledge the BiCIKL project, Grant No 101007492 in the Acknowledgements section.
* The publication fee (APC) is waived for standard-sized manuscripts (up to 40,000 characters, including spaces) normally charged by BDJ at € 650. Authors of larger manuscripts will need to cover the surplus charge (€10 for each 1,000 characters above 40,000). See more about the APC policy at Biodiversity Data Journal, or contact the journal editorial team at: bdj@pensoft.net.
Follow the BiCIKL Project on Twitter and Facebook.Join the conservation on via #BiCIKL_H2020.
You can also follow Biodiversity Data Journal on Twitter and Facebook.
by Mariya Dimitrova, Jorrit Poelen, Georgi Zhelezov, Teodor Georgiev, Lyubomir Penev
Fig. 1. Pensoft-GloBI workflow for indexing biotic interactions from scholarly literature
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species, etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 2 in Fig. 1).. We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as json to a GitHub repository, from where they could be accessed by GloBI.
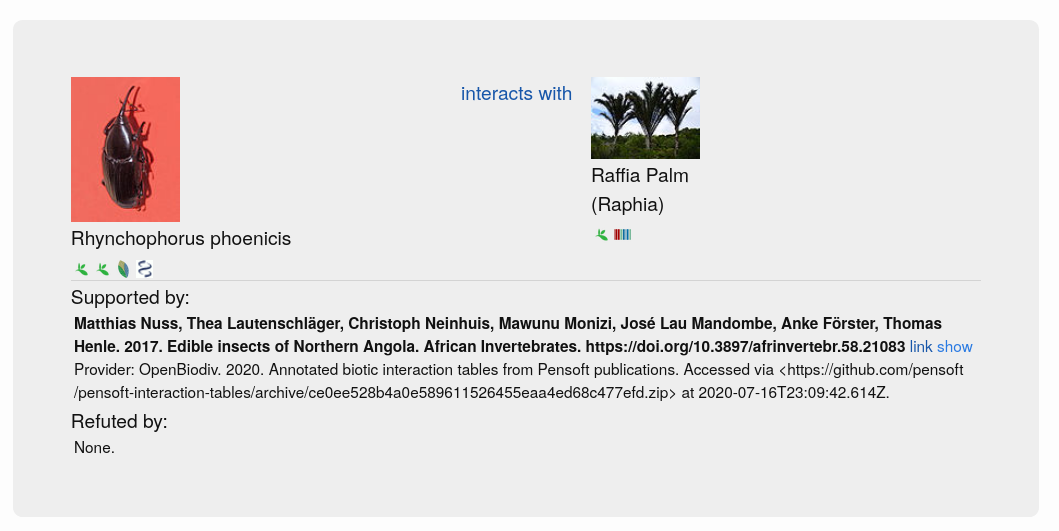
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ (Fig. 2) because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
Fig. 2. Example of a biotic interaction indexed by GloBI.
Examples of species interactions provided by OpenBiodiv and indexed by GloBI are available on GloBI’s website.
In the future we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6,993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 1 in Fig. 1). We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as JSON to a GitHub repository, from where they could be accessed by GloBI.
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
In the future, we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
References
Jorrit H. Poelen, James D. Simons and Chris J. Mungall. (2014). Global Biotic Interactions: An open infrastructure to share and analyze species-interaction datasets. Ecological Informatics. https://doi.org/10.1016/j.ecoinf.2014.08.005.
Additional Information
The work has been partially supported by the International Training Network (ITN) IGNITE funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 764840.
A colony of what is apparently a new species of the genus Hipposideros found in an abandoned gold mine in Western Kenya Photo by B. D. Patterson / Field Museum
Newly published findings about the phylogenetics and systematics of some previously known, but also other yet to be identified species of Old World Leaf-nosed bats, provide the first contribution to a recently launched collection of research articles, whose task is to help scientists from across disciplines to better understand potential hosts and vectors of zoonotic diseases, such as the Coronavirus. Bats and pangolins are among the animals already identified to be particularly potent vehicles of life-threatening viruses, including the infamous SARS-CoV-2.
The article, publicly available in the peer-reviewed scholarly journal ZooKeys, also pilots a new generation of Linked Open Data (LOD) publishing practices, invented and implemented to facilitate ongoing scientific collaborations in times of urgency like those we experience today with the COVID-19 pandemic currently ravaging across over 230 countries around the globe.
In their study, an international team of scientists, led by Dr Bruce Patterson, Field Museum‘s MacArthur curator of mammals, point to the existence of numerous, yet to be described species of leaf-nosed bats inhabiting the biodiversity hotspots of East Africa and Southeast Asia. In order to expedite future discoveries about the identity, biology and ecology of those bats, they provide key insights into the genetics and relations within their higher groupings, as well as further information about their geographic distribution.
“Leaf-nosed bats carry coronaviruses–not the strain that’s affecting humans right now, but this is certainly not the last time a virus will be transmitted from a wild mammal to humans. If we have better knowledge of what these bats are, we’ll be better prepared if that happens,”
says Dr Terrence Demos, a post-doctoral researcher in Patterson’s lab and a principal author of the paper.
One of the possibly three new to science bat species, previously referred to as Hipposideros caffer or Sundevall’s leaf-nosed bat Photo by B. D. Patterson / Field Museum
“With COVID-19, we have a virus that’s running amok in the human population. It originated in a horseshoe bat in China. There are 25 or 30 species of horseshoe bats in China, and no one can determine which one was involved. We owe it to ourselves to learn more about them and their relatives,”
comments Patterson.
In order to ensure that scientists from across disciplines, including biologists, but also virologists and epidemiologists, in addition to health and policy officials and decision-makers have the scientific data and evidence at hand, Patterson and his team supplemented their research publication with a particularly valuable appendix table. There, in a conveniently organized table format, everyone can access fundamental raw genetic data about each studied specimen, as well as its precise identification, origin and the natural history collection it is preserved. However, what makes those data particularly useful for researchers looking to make ground-breaking and potentially life-saving discoveries is that all that information is linked to other types of data stored at various databases and repositories contributed by scientists from anywhere in the world.
Furthermore, in this case, those linked and publicly available data or Linked Open Data (LOD) are published in specific code languages, so that they are “understandable” for computers. Thus, when a researcher seeks to access data associated with a particular specimen he/she finds in the table, he/she can immediately access additional data stored at external data repositories by means of a single algorithm. Alternatively, another researcher might want to retrieve all pathogens extracted from tissues from specimens of a specific animal species or from particular populations inhabiting a certain geographical range and so on.
###
The data publication and dissemination approach piloted in this new study was elaborated by the science publisher and technology provider Pensoft and the digitisation company Plazi for the purposes of a special collection of research papers reporting on novel findings concerning the biology of bats and pangolins in the scholarly journal ZooKeys. By targeting the two most likely ‘culprits’ at the roots of the Coronavirus outbreak in 2020: bats and pangolins, the article collection aligns with the agenda of the COVID-19 Joint Task Force, a recent call for contributions made by the Consortium of European Taxonomic Facilities (CETAF), the Distributed System for Scientific Collections (DiSSCo) and the Integrated Digitized Biocollections (iDigBio).
###
Original source:
Patterson BD, Webala PW, Lavery TH, Agwanda BR, Goodman SM, Kerbis Peterhans JC, Demos TC (2020) Evolutionary relationships and population genetics of the Afrotropical leaf-nosed bats (Chiroptera, Hipposideridae). ZooKeys 929: 117-161. https://doi.org/10.3897/zookeys.929.50240