News about scientific projects, where Pensoft takes part as a science communicator, technology developer, scholarly publisher, project coordinator or else.
The beetle species Grebennikovius basilewskyi. Numbers next to arrows indicate patterns of phenotype statements explained in the section “Phenoscript: main patterns of phenotype statements”. Arrow numbers from T1 to T5 illustrate individual body parts. See more in the research study.
One of the most beautiful aspects of Nature is the endless variety of shapes, colours and behaviours exhibited by organisms. These traits help organisms survive and find mates, like how a male peacock’s colourful tail attracts females or his wings allow him to fly away from danger. Understanding traits is crucial for biologists, who study them to learn how organisms evolve and adapt to different environments.
To do this, scientists first need to describe these traits in words, like saying a peacock’s tail is “vibrant, iridescent, and ornate”. This approach works for small studies, but when looking at hundreds or even millions of different animals or plants, it’s impossible for the human brain to keep track of everything.
Computers could help, but not even the latest AI technology is able to grasp human language to the extent needed by biologists. This hampers research significantly because, although scientists can handle large volumes of DNA data, linking this information to physical traits is still very difficult.
To solve this problem, researchers from the Finnish Museum of Natural History, Giulio Montanaro and Sergei Tarasov, along with collaborators, have created a special language called Phenoscript. This language is designed to describe traits in a way that both humans and computers can understand. Describing traits with Phenoscript is like programming a computer code for how an organism looks.
Phenoscript uses something called semantic technology, which helps computers understand the meaning behind words, much like how modern search engines know the difference between the fruit “apple” and the tech company “Apple” based on the context of your search.
“This language is still being tested, but it shows a lot of promise. As more scientists start using Phenoscript, it will revolutionise biology by making vast amounts of trait data available for large-scale studies, boosting the emerging field of phenomics,”
explains Montanaro.
In their research article, newly published in the open-access, peer-reviewed Biodiversity Data Journal, the researchers make use of the new language for the first time, as they create semantic phenotypes for four species of dung beetles from the genus Grebennikovius. Then, to demonstrate the power of the semantic approach, they apply simple semantic queries to the generated phenotypic descriptions.
Finally, the team takes a look yet further ahead into modernising the way scientists work with species information. Their next aim is to integrate semantic species descriptions with the concept of nanopublications, “which encapsulates discrete pieces of information into a comprehensive knowledge graph”. As a result, data that has become part of this graph can be queried directly, thereby ensuring that it remains Findable, Accessible, Interoperable and Reusable (FAIR) through a variety of semantic resources.
***
Research paper:
Montanaro G, Balhoff JP, Girón JC, Söderholm M, Tarasov S (2024) Computable species descriptions and nanopublications: applying ontology-based technologies to dung beetles (Coleoptera, Scarabaeinae). Biodiversity Data Journal 12: e121562. https://doi.org/10.3897/BDJ.12.e121562
What expert recommendations did the BiCIKL consortium give to policy makers and research funders to ensure that biodiversity data is FAIR, linked, open and, indeed, future-proof? Find out in the blog post summarising key lessons learnt from the Horizon 2020 project.
Within theBiodiversity Community Integrated Knowledge Library (BiCIKL) project, 14 European institutions from ten countries, spent the last three years elaborating on services and high-tech digital tools, in order to improve the findability, accessibility, interoperability and reusability (FAIR-ness) of various types of data about the world’s biodiversity. These types of data include peer-reviewed scientific literature, occurrence records, natural history collections, DNA data and more.
By ensuring all those data are readily available and efficiently interlinked to each other, the project consortium’s intention is to provide better tools to the scientific community, so that it can more rapidly and effectively study, assess, monitor and preserve Earth’s biological diversity in line with the objectives of the likes of the EU Biodiversity Strategy for 2030 and the European Green Deal. Their targets require openly available, precise and harmonised data to underpin the design of effective measures for restoration and conservation, reminds the BiCIKL consortium.
Since 2021, the project partners at BiCIKL have been working together to elaborate existing workflows and links, as well as create brand new ones, so that their data resources, platforms and tools can seamlessly communicate with each other, thereby taking the burden off the shoulders of scientists and letting them focus on their actual mission: paving the way to healthy and sustainable ecosystems across Europe and beyond.
Now that the three-year project is officially over, the wider scientific community is yet to reap the fruits of the consortium’s efforts. In fact, the end of the BiCIKL project marks the actual beginning of a European- and global-wide revolution in the way biodiversity scientists access, use and produce data. It is time for the research community, as well as all actors involved in the study of biodiversity and the implementation of regulations necessary to protect and preserve it, to embrace the lessons learned, adopt the good practices identified and build on the knowledge in existence.
This is why amongst the BiCIKL’s major final research outputs, there are two Policy Briefs meant to summarise and highlight important recommendations addressed to key policy makers, research institutions and funders of research. After all, it is the regulatory bodies that are best equipped to share and implement best practices and guidelines.
Most recently, the BiCIKL consortium published two particularly important policy briefs, both addressed to the likes of the European Commission’s Directorate-General for Environment; the European Environment Agency; the Joint Research Centre; as well as science and policy interface platforms, such as the EU Biodiversity Platform; and also organisations and programmes, e.g. Biodiversa+ and EuropaBON, which are engaged in biodiversity monitoring, protection and restoration. The policy briefs are also to be of particular use to national research funds in the European Union.
One of the newly published policy briefs, titled “Uniting FAIR data through interlinked, machine-actionable infrastructures”, highlights the potential benefits derived from enhanced connectivity and interoperability among various types of biodiversity data. The publication includes a list of recommendations addressed to policy-makers, as well as nine key action points. Understandably, amongst the main themes are those of wider international cooperation; inclusivity and collaboration at scale; standardisation and bringing science and policy closer to industry. Another major outcome of the BiCIKL project: the Biodiversity Knowledge Hub portal is noted as central to many of these objectives and tasks in its role of a knowledge broker that will continue to be maintained and updated with additional FAIR data-compliant services as a living legacy of the collaborative efforts at BiCIKL.
The second policy brief, titled “Liberate the power of biodiversity literature as FAIR digital objects”, shares key actions that can liberate data published in non-machine actionable formats and non-interoperable platforms, so that those data can also be efficiently accessed and used; as well as ways to publish future data according to the best FAIR and linked data practices. The recommendations highlighted in the policy brief intend to support decision-making in Europe; expedite research by making biodiversity data immediately and globally accessible; provide curated data ready to use by AI applications; and bridge gaps in the life cycle of research data through digital-born data. Several new and innovative workflows, linkages and integrative mechanisms and services developed within BiCIKL are mentioned as key advancements created to access and disseminate data available from scientific literature.
While all policy briefs and factsheets – both primarily targeted at non-expert decision-makers who play a central role in biodiversity research and conservation efforts – are openly and freely available on the project’s website, the most important contributions were published as permanent scientific records in a BiCIKL-branded dedicated collection in the peer-reviewed open-science journal Research Ideas and Outcomes (RIO). There, the policy briefs are provided as both a ready-to-print document (available as supplementary material) and an extensive academic publication.
Currently, the collection: “Towards interlinked FAIR biodiversity knowledge: The BiCIKL perspective” in the RIO journal contains 60 publications, including policy briefs, project reports, methods papers, conference abstracts, demonstrating and highlighting key milestones and project outcomes from along the BiCIKL’s journey in the last three years. The collection also features over 15 scientific publications authored by people not necessarily involved in BiCIKL, but whose research uses linked open data and tools created in BiCIKL. Their publications were published in a dedicated article collection in the Biodiversity Data Journal.
Leiden – also known as the ‘City of Keys’ and the ‘City of Discoveries’ – was aptly chosen to host the third Empowering Biodiversity Research (EBR III) conference. The two-day conference – this time focusing on the utilisation of biodiversity data as a vehicle for biodiversity research to reach to Policy – was held in a no less fitting locality: the Naturalis Biodiversity Center.
On 25th and 26th March 2024, the delegates got the chance to learn more about the latest discoveries, trends and innovations from scientists, as well as various stakeholders, including representatives of policy-making bodies, research institutions and infrastructures. The conference also ran a poster session and a Biodiversity Informatics market, where scientists, research teams, project consortia, and providers of biodiversity research-related services and tools could showcase their work and meet like-minded professionals.
BiCIKL stops at the Naturalis Biodiversity Center
The main outcome of the BiCIKL project: the Biodiversity Knowledge Hub, a one-stop knowledge portal to interlinked and machine-readable FAIR data.
The famous for its bicycle friendliness country also made a suitable stop for BiCIKL (an acronym for the Biodiversity Community Integrated Knowledge Library): a project funded under the European Commission’s Horizon 2020 programme that aimed at triggering a culture change in the way users access, (re)use, publish and share biodiversity data. To do this, the BiCIKL consortium set off on a 3-year journey to build on the existing biodiversity data infrastructures, workflows, standards and the linkages between them.
Many of the people who have been involved in the project over the last three years could be seen all around the beautiful venue. Above all, Naturalis is itself one of the partnering institutions at BiCIKL. Then, on Tuesday, on behalf of the BiCIKL consortium and the project’s coordinator: the scientific publisher and technology innovator: Pensoft, Iva Boyadzhieva presented the work done within the project one month ahead of its official conclusion at the end of April.
As she talked about the way the BiCIKL consortium took to traverse obstacles to wider use and adoption of FAIR and linked biodiversity data, she focused on BiCIKL’s main outcome: the Biodiversity Knowledge Hub (BKH).
Key results from the BiCIKL project three years into its existence presented by Pensoft’s Iva Boyadzhieva at the EBR III conference.
Intended to act as a knowledge broker for users who wish to navigate and access sources of open and FAIR biodiversity data, guidelines, tools and services, in practicality, the BKH is a one-stop portal for understanding the complex but increasingly interconnected landscape of biodiversity research infrastructures in Europe and beyond. It collates information, guidelines, recommendations and best practices in usage of FAIR and linked biodiversity data, as well as a continuously expanded catalogue of compliant relevant services and tools.
At the core of the BKH is the FAIR Data Place (FDP), where users can familiarise themselves with each of the participating biodiversity infrastructures and network organisations, and also learn about the specific services they provide. There, anyone can explore various biodiversity data tools and services by browsing by their main data type, e.g. specimens, sequences, taxon names, literature.
While the project might be coming to an end, she pointed out, the BKH is here to stay as a navigation system in a universe of interconnected biodiversity research infrastructures.
To do this, not only will the partners continue to maintain it, but it will also remain open to any research infrastructure that wishes to feature its own tools and services compliant with the linked and FAIR data requirements set by the BiCIKL consortium.
Indisputably, the ‘hot’ topics at the EBR III were the novel technologies for remote and non-invasive, yet efficient biomonitoring; the utilisation of data and other input sourced by citizen scientists; as well as leveraging different types and sources of biodiversity data, in order to better inform decision-makers, but also future-proof the scientific knowledge we have collected and generated to date.
Project’s coordinator Dr Quentin Groom presents the B-Cubed’s approach towards standardised access to biodiversity data for the use of policy-making at the EBR III conference.
Amongst the other Horizon Europe projects presented at the EBR III conference was B-Cubed (Biodiversity Building Blocks for policy). On Monday, the project’s coordinator Dr Quentin Groom (Meise Botanic Garden) familiarised the conference participants with the project, which aims to standardise access to biodiversity data, in order to empower policymakers to proactively address the impacts of biodiversity change.
You can find more about B-Cubed and Pensoft’s role in it in this blog post.
Dr France Gerard (UK Centre for Ecology & Hydrology) talks about the challenges in using raw data – including those provided by drones – to derive habitat condition metrics.
MAMBO: another Horizon Europe project where Pensoft has been contributing with expertise in science communication, dissemination and exploitation, was also an active participant at the event. An acronym for Modern Approaches to the Monitoring of BiOdiversity, MAMBO had its own session on Tuesday morning, where Dr Vincent Kalkman (Naturalis Biodiversity Center), Dr France Gerard (UK Centre for Ecology & Hydrology) and Prof. Toke Høye (Aarhus University) each took to the stage to demonstrate how modern technology developed within the project is to improve biodiversity and habitat monitoring. Learn more about MAMBO and Pensoft’s involvement in this blog post.
MAMBO’s project coordinator Prof. Toke T. Høye talked about smarter technologies for biodiversity monitoring, including camera traps able to count insects at a particular site.
On the event’s website you can access the MAMBO’s slides presentations by Kalkman, GerardandHøye, as presented at the EBR III conference.
***
The EBR III conference also saw a presentation – albeit remote – from Prof. Dr. Florian Leese (Dean at the University of Duisburg-Essen, Germany, and Editor-in-Chief at the Metabarcoding and Metagenomics journal), where he talked about the promise, but also the challenges for DNA-based methods to empower biodiversity monitoring.
Amongst the key tasks here, he pointed out, are the alignment of DNA-based methods with the Global Biodiversity Framework; central push and funding for standards and guidance; publication of data in portals that adhere to the best data practices and rules; and the mobilisation of existing resources such as the meteorological ones.
He also made a reference to the Forum Paper “Introducing guidelines for publishing DNA-derived occurrence data through biodiversity data platforms” by R. Henrik Nilsson et al., where the international team provided a brief rationale and an overview of guidelines targeting the principles and approaches of exposing DNA-derived occurrence data in the context of broader biodiversity data. In the study, published in the Metabarcoding and Metagenomics journal in 2022, they also introduced a living version of these guidelines, which continues to encourage feedback and interaction as new techniques and best practices emerge.
***
You can find the programme on the conference website and see highlights on the conference hashtag: #EBR2024.
The city of Cambridge and the Wellcome Campus hosted the Final General Assembly of the EU-funded project BiCIKL (acronym for Biodiversity Community Integrated Knowledge Library): a 36-month endeavour that saw 14 member institutions and 15 research infrastructures representing diverse actors from the biodiversity data realm come together to improve bi-directional links between different platforms, standards, formats and scientific fields. Consortium members who could not attend the meeting in Cambridge joined the meeting remotely.
After a welcome cocktail reception on Monday evening at Hilton Cambridge City Centre, on Tuesday, the consortium made an early start with a recap of BiCIKL’s key milestones and outputs from the last three years. All Work Package leaders had their own timeslot to discuss the results of their collaborations.
They all agreed that the Biodiversity Knowledge Hub – the one-stop portal for understanding the complex – yet increasingly interconnected landscape of biodiversity research infrastructures – is likely the flagship outcome of BiCIKL.
Prof. Lyubomir Penev, project coordinator of BiCIKL and founder/CEO of Pensoft Publishers at the BiCIKL’s third and final General Assembly in Cambridge, United Kingdom.
In the afternoon, the participants focused on the services developed under BiCIKL. Amongst the many services resulting from the project some were not originally planned. Rather those were the ‘natural’ products of the dialogue and collaboration that flourished within the consortium throughout the project. “A symptom of passion,” said Prof. Lyubomir Penev, project coordinator of BiCIKL and founder/CEO of Pensoft Publishers.
An excellent example of one such service is what the partners call the “Biodiversity PMC”, which brings together biodiversity literature from thousands of scholarly journals and over 500,000 taxonomic treatments, in addition to the biomedical content available from NIH’s PubMed Central, into the SIB Literature Services (SIBiLS) database. What’s more, users at SIBiLS – be it human or AI – can now use advanced text- and data-mining tools, including AI-powered factoid question-answering capacities, to query all this full-text indexed content and seek out, for example, species traits and biotic interactions. Read more about the “Biodiversity PMC” in its recent official announcement.
Far from being the only one, the “Biodiversity PMC” is in good company: from the blockchain-based technology of LifeBlock to the curation of the DNA sequences by PlutoF, the BiCIKL project consortium takes pride in having developed twelve services dedicated to FAIR and linked ready-to-use biodiversity data.
On Wednesday, the consortium focused on BiCIKL’s activities from the Transnational and Virtual Access Pillar, which included both presentations by each open call leader and VA leader, as well as open discussions and a recap of what the teams have learnt from these experiences.
A panel discussion took place on Thursday as part of an open event, where BiCIKL partners and ELIXIR Biodiversity and Plant Communities came together to discuss the Future of Biodiversity and Genomics data integration at the EMBL Wellcome Genome Campus.
Thursday was dedicated to an open event where BiCIKL partners and ELIXIR Biodiversity and Plant Communities came together to discuss the Future of Biodiversity and Genomics data integration at the EMBL Wellcome Genome Campus. You can find the agenda on BiCIKL’s website.
After 36 months of action, the BiCIKL project will officially end in April 2024, but does it mean that all will be done and dusted come May 2024? Certainly not, point out the partners.
To ensure that the Biodiversity Knowledge Hub will not only continue to exist but will not cease to grow in both use and participation, the one-stop portal will remain under the maintenance of LifeWatch ERIC.
In conclusion, we could say that an appropriate payoff for the project is “Stick together!” as put by BiCIKL’s Joint Research Activity Leader Dr. Quentin Groom.
Final words at the third and last General Assembly of the BiCIKL project.
You can find highlights from the BiCIKL General Assembly meeting on X via the #BiCIKL_H2020 hashtag (in association with #Cambridge and #finalGA)
All research outputs, including the approved grant proposal, policy briefs, guidelines papers and research articles associated with the project, remain openly accessible from the BiCIKL project outcomes collection in RIO Journal: https://doi.org/10.3897/rio.coll.105.
The indexing is one of the major outcomes from the partnerships within the Horizon 2020-funded project Biodiversity Community Integrated Knowledge Library (BiCIKL)
In a joint effort between the Swiss-based Text Mining group of Patrick Ruch at SIB (developing SIBiLS), the text- and data-mining association Plazi and scientific publisher Pensoft, the long-time collaborators have started feeding full-text content of over 500,000 taxonomic treatments extracted by Plazi and tens of thousands full-text articles from 40 well-renowned biodiversity journals published by Pensoft to the SIBiLS database.
What this means is that users at SIBiLS – be it human or AI – have now gained access to advanced text- and data-mining tools, including AI-powered factoid question-answering capacities, to query all this full-text indexed content and seek out, for example, species traits and biotic interactions.
To index and directly feed the content from its 40+ academic outlets at SIBiLS, Pensoft relies on advanced and full-text TaxPub JATS XML journal publication workflow, powered by the ARPHA publishing platform. Meanwhile, Plazi uses its GoldenGate text- and data-mining software to harvest taxon treatments from over 80 journals stored at TreatmentBank and the Biodiversity Literature Repository, and then further re-used by GBIF, OpenBiodiv and now by SiBILS.
Seen as a pilot, the indexing – the partners believe – could soon be extended with other journals relying on modern publishing or converted legacy publications.
However, there were still gaps left to bridge before SIBiLS could indeed be dubbed “the Biodiversity PMC”, and those have mostly been about volume and breadth of content. While the above-mentioned five journals by Pensoft had long been indexed by SIBiLS through harvesting PMC, those had been quite an exception since, several years ago, a reorganisation at PMC moved the focus of the database to almost exclusively biomedical content, thus leaving biodiversity journals out of the scope of the database.
In the meantime, while Plazi has been feeding SIBiLS a growing volume of taxonomic treatments and visual data, as it was exponentially increasing the number of publishers and journals it mined data from, a lot of biodiversity data (e.g. genetic, molecular, ecological) published in the article narratives that were not taxon treatments could not make it to the portal.
“We all know the advantages and practical uses PMC offers to its users, so we cannot miss the opportunity to incorporate this well-proven approach to navigate the data deluge in biodiversity science. Undoubtedly, it is an extremely ambitious and demanding task. Yet, I believe that, at the BiCIKL consortium, we have made it pretty clear we have the necessary expertise, know-how and aspiration to take on the challenge,”
said Prof. Lyubomir Penev, founder/CEO at Pensoft and project coordinator of BiCIKL.
“For far too long, scientific knowledge about biodiversity has been imprisoned in a continuously growing corpus of scientific outputs, which – most of the time – are published in unstructured formats, such as PDF, or as paywalled content, and often locked by both! This means that they are – at best – difficult to access and comprehend by computer algorithms. In the meantime, we need all that knowledge, in order to accelerate our understanding of the dynamics of the global biodiversity crisis and to efficiently assess the impact of climate change. This is why the need for advanced workflows and tools to annotate, mine, query and discover new facts from the available literature is more than obvious,”
added Dr. Donat Agosti, President at Plazi.
“In the course of the BiCIKL project, at SIBiLS, we started indexing a larger set of biodiversity-related contents in the broad sense, including environmental sciences and ecology, to build a new literature database, or what we now call ‘Biodiversity PMC’. Now, with the help of Plazi and Pensoft, we provide a unique entry point to half a million taxonomic treatments, which were not included into the original PubMed Central. Next on the list is to expand our network of literature sources and continue this exponential growth of queryable biodiversity knowledge to turn Biodiversity PMC into the “One Health” library. We promise to keep you posted,”
said Dr. Patrick Ruch, Group Leader at SIB and Head of Research at HES-SO, HEG Geneva, Switzerland.
SIB is an internationally recognized non-profit organisation, dedicated to biological and biomedical data science. SIB’s data scientists are passionate about creating knowledge and solving complex questions in many fields, from biodiversity and evolution to medicine. They provide essential databases and software platforms as well as bioinformatics expertise and services to academic, clinical, and industry groups. With the recent creation of the Environmental Bioinformatics group, led by Robert Waterhouse, SIB is engaged in an unprecedented effort to streamline data across molecular biology, health and biodiversity. SIB also federates the Swiss bioinformatics community of some 900 scientists, encouraging collaboration and knowledge sharing.
***
About Plazi:
Plazi is an association supporting and promoting the development of persistent and openly accessible digital taxonomic literature. To this end, Plazi maintains TreatmentBank, a digital taxonomic literature repository to enable archiving of taxonomic treatments; develops and maintains TaxPub, an extension of the National Library of Medicine / National Center for Biotechnology Informatics Journal Article Tag Suite for taxonomic treatments; is co-founder of the Biodiversity Literature Repository at Zenodo, participates in the development of new models for publishing taxonomic treatments in order to maximise interoperability with other relevant cyberinfrastructure components such as name servers and biodiversity resources; and advocates and educates about the vital importance of maintaining free and open access to scientific discourse and data. Plazi is a major contributor to the Global Biodiversity Information Facility.
October and November 2023 were active months for the Pensoft team, who represented the publisher’s journals and projects at conferences in Europe, North America, South America, Oceania and Asia.
Let’s take a look back at all the events of the past two months.
The Biodiversity Information Standards Conference 2023
The annual gathering is a crucial platform for sharing insights, innovations, and knowledge related to biodiversity data standards and practices. Key figures from Pensoft took part in the event, presenting new ways to improve the management, accessibility, and usability of biodiversity data.
Prof. Lyubomir Penev, founder and Chief Executive Officer of Pensoft, gave two talks that highlighted the importance of data publishing. His presentation on “The Biodiversity Knowledge Hub (BKH): A Crosspoint and Knowledge Broker for FAIR and Linked Biodiversity Data” underscored the significance of FAIR (Findable, Accessible, Interoperable, and Reusable) data standards. BKH is the major output from the Horizon 2020 project BiCIKL (Biodiversity Community Integrated Knowledge Library) dedicated to linked and FAIR data in biodiversity, and coordinated by Pensoft.
Prof. Lyubomir Penev, Pensoft founder and CEO.
He also introduced the Nanopublications for Biodiversity workflow and format: a promising new tool developed by Knowledge Pixels and Pensoft to communicate key scientific statements in a way that is human-readable, machine-actionable, and in line with FAIR principles. Earlier this year, Biodiversity Data Journal integrated nanopublications into its workflow to allow authors to share their findings even more efficiently.
Chief Technology Officer of Pensoft Teodor Georgiev contributed to the conference by presenting “OpenBiodiv for Users: Applications and Approaches to Explore a Biodiversity Knowledge Graph.” His session highlighted the innovative approaches being taken to explore and leverage a biodiversity knowledge graph, showcasing the importance of technology in advancing biodiversity research.
Metabarcoding and Metagenomics editor-in-chief, Florian Leese.
The theme of the conference was “Monitoring Biodiversity for Action” and there was particular emphasis on the development of best practices and new technologies for biodiversity observations and monitoring to support transformative policy and conservation action.
Metabarcoding & Metagenomics’ editor-in-chief, Florian Leese, was one of the organisers of the “Standardized eDNA-Based Biodiversity Monitoring to Inform Environmental Stewardship Programs” session. Furthermore, the journal was represented at Pensoft’s exhibition booth, where conference participants were able to discuss metabarcoding and metagenomics research.
#geobonconf2023 was great as it linked different actors performing #biodiversity monitoring. Today we discussed #eDNA standardisation. We need formal standards, QA/QC, guidance, 🌐harmonisation to facilitate uptake. Cool to see our @DNAquaNet practical guide in this context. pic.twitter.com/eTOtr3yug8
Following the conference, Metabarcoding & Metagenomics announced a new special issue titled “Towards Standardized Molecular Biodiversity Monitoring.” The special issue is accepting submissions until 15th March 2024.
Asian Mycological Congress2023
The Asian Mycological Congress welcomed researchers from around the world to Busan, Republic of Korea, for an exploration of all things fungi from 10-13 October.
MycoKeys Best Talk award (winner not pictured).
Titled “Fungal World and Its Bioexploitation – in all areas of basic and applied mycology,” the conference covered a range of topics related to all theoretical and practical aspects of mycology. There was a particular emphasis on the development of mycology through various activities associated with mycological education, training, research, and service in countries and regions within Asia.
As one of the sponsors of the congress, Pensoft proudly presented a Best Talk award to Dr Sinang Hongsanan of Chiang Mai University, Thailand. The award entitles the winner to a free publication in Pensoft’s flagship mycology journal, MycoKeys.
Joint ESENIAS and DIAS Scientific Conference 2023
The ESENIAS and DIAS conference took place from 11-14 October and focused on “globalisation and invasive alien species in the Black Sea and Mediterranean regions.” Pensoft shared information on their NeoBiota journal and the important REST-COAST and B-Cubed projects.
Polina Nikova receiving the NeoBiota Best Talk Award.
Polina Nikova of the Bulgarian Academy of Sciences received the NeoBiota Best Talk Award for her presentation titled “First documented records in the wild of American mink (Neogale vision von Schreber, 1776) in Bulgaria.” The award entitles her to a free publication in the NeoBiota journal.
XII European Congress of Entomology
Pensoft took part in the XII European Congress of Entomology (ECE 2023) in Heraklion, Crete, from 16-20 October. The event provided a forum for entomologists from all over the world, bringing together over 900 scientists from 60 countries.
Carla Stoyanova, Teodor Metodiev and Boriana Ovcharova representing Pensoft.
The ECE 2023, organised by the Hellenic Entomological Society, addressed the pressing challenges facing entomology, including climate change, vector-borne diseases, biodiversity loss, and the need to sustainably feed a growing world population. The program featured symposia, lectures, poster sessions, and other types of activities aimed at fostering innovation in entomology. For Pensoft, they were a great opportunity to interact with scientists and share their commitment to advancing entomological research and addressing the critical challenges in the field.
🐝Today at #ECE2023, Prof Denis Michez & Sara Reverté are running a workshop on bee identification!
Throughout the event, conference participants could find Pensoft’s team at thir booth, and learn more about the scholarly publisher’s open-access journals in entomology. In addition, the Pensoft team presented the latest outcomes from the Horizon 2020 projects B-GOOD, Safeguard, and PoshBee, where the publisher takes care of science communication and dissemination as a partner.
Group photo of XIV International Congress of Orthopterology 2023 participants.
Hosted for the first time in Mexico, it attracted experts and enthusiasts from around the world. The congress featured plenary speakers who presented cutting-edge research and insights on various aspects of grasshoppers, crickets, and related insects.
Pensoft’s Journal of Orthoptera Research was represented by Tony Robillard, the editor-in-chief, who presented the latest developments of the journal to attendees.
Symposia, workshops, and meetings facilitated discussions on topics like climate change impacts, conservation, and management of Orthoptera. The event also included introductions to new digital and geospatial tools for Orthoptera research.
The 16th International Conference on Ecology and Management of Alien Plant Invasions
4th International ESP Latin America and Caribbean Conference
The 4th International ESP Latin America and Caribbean Conference (ESP LAC 2023) was held in La Serena, Chile, from 6-10 November. Focused on “Sharing knowledge about ecosystem services and natural capital to build a sustainable future,” the event attracted experts in ecosystem services, particularly from Latin America and the Caribbean.
🤩 So excited to be part of the 4th International ESP Latin America and Caribbean Conference, which opens later today! In a great tradition with the ESP conferences, we are offering three full APC waivers for the three best posters.@ESPartnershiphttps://t.co/O97nwEGnMj
Organised by the Ecosystem Services Partnership, this bi-annual conference was open to both ESP members and non-members, featuring a hybrid format in English and Spanish. Attendees enjoyed an excursion to La Serena’s historical center, adding a cultural dimension to the event.
The conference included diverse sessions and a special recognition by Pensoft’s One Ecosystem journal, which awarded full waivers for publication to the authors of the three best posters.
Magaly Aldave receiving the Best Poster Award.
Magaly Aldave of the Transdisciplinary Center for FES-Systemic Studies claimed first prize with “The voice of children in the conservation of the urban wetland and Ramsar Site Pantanos de Villa in Metropolitan Lima, Peru.” Ana Catalina Copier Guerrero and Gabriela Mallea-Rebolledo, both of the University of Chile, were awarded second and third prize respectively.
The event featured in-person and online participation, catering to a wide audience of researchers, academics, and students. It included workshops, presentations, and discussions, with a focus on enhancing understanding in biosystematics.
Pensoft awarded three student prizes at the event. Putter Tiatragu, Australian National University, received the Best Student Talk award and a free publication in any Pensoft journal for “A big burst of blindsnakes: Phylogenomics and historical biogeography of Australia’s most species-rich snake genus.”
Helen Armstrong, Murdoch University, received the Best Student Lightning Talk for “An enigmatic snapper parasite (Trematoda: Cryptogonimidae) found in an unexpected host.” Patricia Chan, University of Wisconsin-Madison, was the Best Student Lightning Talk runner-up for “Drivers of Diversity of Darwinia’s Common Scents and Inflorescences with Style: Phylogenomics, Pollination Biology, and Floral Chemical Ecology of Western Australian Darwinia (Myrtaceae).”
–
As we approach the end of 2023, Pensoft looks back on its most prolific and meaningful year of conferences and events. Thank you to everyone who contributed to or engaged with Pensoft’s open-access journals, and here’s to another year of attending events, rewarding important research, and connecting with the scientific community.
The initiative, featured in an open-access methods paper in Biodiversity Data Journal, unites the Darwin Core (DwC) and Minimum Information about any (x) Sequence (MIxS) standards.
Biodiversity observation and research rely more and more on biomolecular data. The standardization this data, encompassing both primary and contextual information (metadata), is crucial for enabling data (re-)use, integration, and knowledge generation.
While both the biodiversity and the omics research communities have recognized the urgent need for (meta)data standards, they each have historically developed and adopted their own standards, making collaboration and data integration challenging.
The Task Group assembled a team of experts to build semantically precise and sustained interoperability between TDWG’s DwC standard, and the MIxS checklist from the GSC.
This collaborative effort culminated in a methods paper, in which they report on building sustainable interoperability between DwC and MIxS.
The paper was published in the open-access, peer-reviewed Biodiversity Data Journal, as part of a special collection, supported by the EU-funded project BiCIKL (Biodiversity Community Integrated Knowledge Library), and looking to demonstrate the advantages and novel approaches in accessing and (re-)using linked biodiversity data.
“With representatives from established biodiversity data infrastructures, domain experts, data generators, and publishers, we – ab initio – bridged the conceptual to the application space,”
write the task group members in their paper.
To ensure the sustainability and lasting impact of this initiative, TDWG and GSC have signed a Memorandum of Understanding on creating a continuous model to synchronize their standards.
“We trust that the activities of this TG will inspire similar activities between other metadata standards in this space, to break down silos and open a path to a more collaborative and interoperable future,”
they say in conclusion.
***
Original source:
Meyer R, Appeltans W, Duncan WD, Dimitrova M, Gan Y-M, Stjernegaard Jeppesen T, Mungall C, Paul DL, Provoost P, Robertson T, Schriml L, Suominen S, Walls R, Sweetlove M, Ung V, Van de Putte A, Wallis E, Wieczorek J, Buttigieg PL (2023) Aligning Standards Communities for Omics Biodiversity Data: Sustainable Darwin Core-MIxS Interoperability. Biodiversity Data Journal 11: e112420. https://doi.org/10.3897/BDJ.11.e112420
***
You can find all contributions published in the “Linking FAIR biodiversity data through publications: The BiCIKL approach” article collection in the open-access, peer-reviewed Biodiversity Data Journal on: https://doi.org/10.3897/bdj.coll.209.
Novel nanopublication workflows and templates for associations between organisms, taxa and their environment are the latest outcome of the collaboration between Knowledge Pixels and Pensoft.
Nanopublications complement human-created narratives of scientific knowledge with elementary, machine-actionable, simple and straightforward scientific statements that prompt sharing, finding, accessibility, citability and interoperability.
By making it easier to trace individual findings back to their origin and/or follow-up updates, nanopublications also help to better understand the provenance of scientific data.
With the nanopublication format and workflow, authors make sure that key scientific statements – the ones underpinning their research work – are efficiently communicated in both human-readable and machine-actionable mannerin line with FAIR principles. Thus, their contributions to science are better prepared for a reality driven by AI technology.
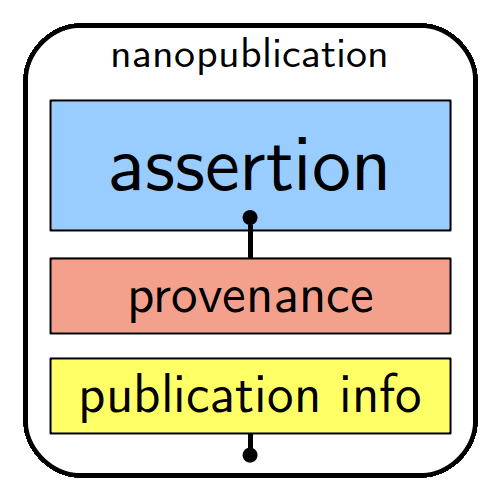
The machine-actionability of nanopublications is a standard due to each assertion comprising a subject, an object and a predicate (type of relation between the subject and the object), complemented by provenance, authorship and publication information. A unique feature here is that each of the elements is linked to an online resource, such as a controlled vocabulary, ontology or standards.
Now, what’s new?
As a result of the partnership between high-tech startup Knowledge Pixels and open-access scholarly publisher and technology provider Pensoft, authors in Biodiversity Data Journal (BDJ) can make use of three types of nanopublications:
Nanopublications associated with a manuscript submitted to BDJ. This workflow lets authors add a Nanopublications section within their manuscript while preparing their submission in the ARPHA Writing Tool (AWT). Basically, authors ‘highlight’ and ‘export’ key points from their papers as nanopublications to further ensure the FAIRness of the most important findings from their publications.
Standalone nanopublication related to any scientific publication, regardless of its author or source. This can be done via the Nanopublications page accessible from the BDJ website. The main advantage of standalone nanopublication is that straightforward scientific statements become available and FAIR early on, and remain ready to be added to a future scholarly paper.
Nanopublications as annotations to existing scientific publications. This feature is available from several journals published on the ARPHA Platform, including BDJ. By attaching an annotation to the entire paper (via the Nanopublication tab) or a text selection (by first adding an inline comment, then exporting it as a nanopublication), a reader can evaluate and record an opinion about any article using a simple template based on the Citation Typing Ontology (CiTO).
Nanopublications for biodiversity data?
At Biodiversity Data Journal (BDJ), authors can now incorporate nanopublications within their manuscripts to future-proofthe most important assertions on biological taxa and organisms or statements about associations of taxa or organisms and their environments.
On top of being shared and archived by means of a traditional research publication in an open-access peer-reviewed journal, scientific statements using the nanopublication format will also remain ‘at the fingertips’ of automated tools that may be the next to come looking for this information, while mining the Web.
Using the nanopublication workflows and templates available at BDJ, biodiversity researchers can share assertions, such as:
So far, the available biodiversity nanopublication templates cover a range of associations, including those between taxa and individual organisms, as well as between those and their environments and nucleotide sequences.
Nanopublication template customised for biodiversity research publications available from Nanodash.
As a result, those easy-to-digest ‘pixels of knowledge’ can capture and disseminate information about single observations, as well as higher taxonomic ranks.
The novel domain-specific publication format was launched as part of thecollaboration betweenKnowledge Pixels – an innovative startup tech company aiming to revolutionise scientific publishing and knowledge sharing and the open-access scholarly publisherPensoft.
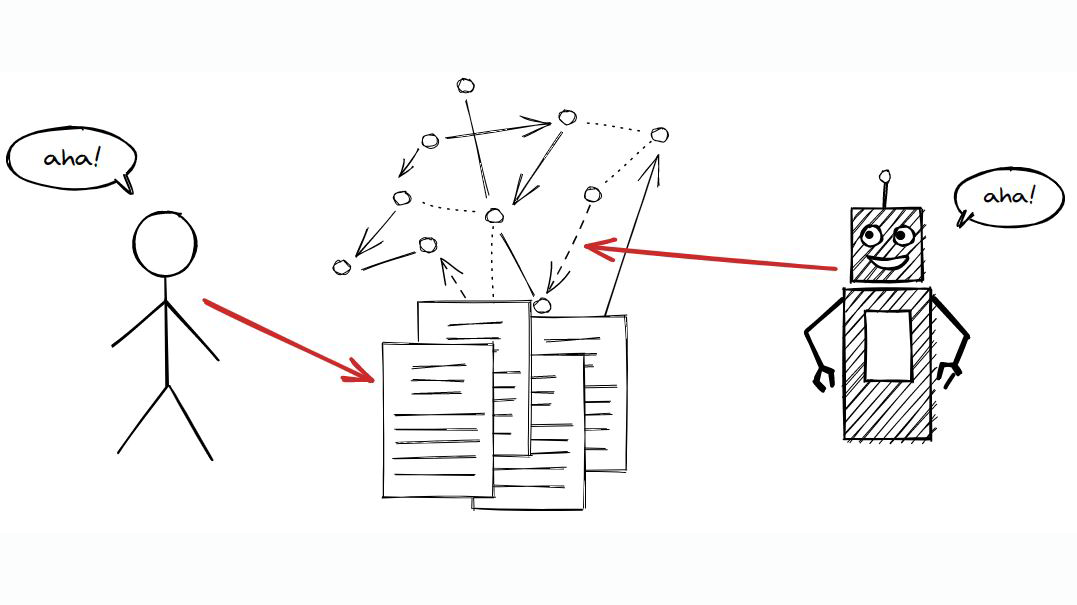
Basically, a nanopublication – unlike a research article – is a tiny snippet of a precise and structured scientific finding (e.g. medication X treats disease Y), which exists as a reusable and cite-able pieces of a growing knowledge graph stored on a decentralised server network in a format that it is readable for humans, but also “understandable” and actionable for computers and their algorithms.
These semantic statements expressed in community-agreed terms, openly available through links to controlled vocabularies, ontologies and standards, are not only freely accessible to everyone in both human-readable and machine-actionable formats, but also easy-to-digest for computer algorithms and AI-powered assistants.
In short, nanopublications allow us to browse and aggregate such findings as part of a complex scientific knowledge graph. Therefore, nanopublications bring us one step closer to the next revolution in scientific publishing, which started with the emergence and increasing adoption of knowledge graphs.
“As pioneers in the semantic open access scientific publishing field for over a decade now, we at Pensoft are deeply engaged with making research work actually available at anyone’s fingertips. What once started as breaking down paywalls to research articles and adding the right hyperlinks in the right places, is time to be built upon,”
By letting computer algorithms access published research findings in a structured format, nanopublications allow for the knowledge snippets that they are intended to communicate to be fully understandable and actionable. With nanopublications, each of those fragmentsof scientific information is interconnected and traceable back to its author(s) and scientific evidence.
A nanopublication is a tiny snippet of a precise and structured scientific finding (e.g. medication X treats disease Y), which exists within a growing knowledge graph stored on a decentralised server network in a format that it is readable for humans, but also “understandable” and actionable for computers and their algorithms. Illustration by Knowledge Pixels.
By building on shared knowledge representation models, these data become Interoperable (as in the Iin FAIR), so that they can be delivered to the right user, at the right time, in the right place , ready to be reused (as per the R in FAIR) in new contexts.
Another issue nanopublications are designed to address is research scrutiny. Today, scientific publications are produced at an unprecedented rate that is unlikely to cease in the years to come, as scholarship embraces the dissemination of early research outputs, including preprints, accepted manuscripts and non-conventional papers.
A network of interlinked nanopublications could also provide a valuable forum for scientists to test, compare, complement and build on each other’s results and approaches to a common scientific problem, while retaining the record of their cooperation each step along the way.
***
We encourage you to try the nanopublications workflow yourself when submitting your next biodiversity paper to Biodiversity Data Journal.
Community feedback on this pilot project and suggestions for additional biodiversity-related nanopublication templates are very welcome!
On the journal website: https://bdj.pensoft.net/, you can find more about the unique features and workflows provided by the Biodiversity Data Journal (BDJ), including innovative research paper formats (e.g. Data Paper, OMICS Data Paper, Software Description, R Package, Species Conservation Profiles, Alien Species Profile), expert-provided data audit for each data paper submission, automated data export and more.
Don’t forget to also sign up for the BDJ newsletter via the Email alert form on the journal’s homepage and follow it on Twitter and Facebook.
Earlier this year, Knowledge Pixels and Pensoft presented several routes for readers and researchers to contribute to research outputs – either produced by themselves or by others – through nanopublications generated through and visualised in Pensoft’s cross-disciplinary Research Ideas and Outcomes (RIO) journal, which uses the same nanopublication workflows.
BKH is a one-stop portal that allows users to access FAIR and interlinked biodiversity data and services in a few clicks. BKH was designed to support a new emerging community of users over time and across the entire biodiversity research cycle providing its services to anybody, anywhere and anytime.
The Knowledge Hub is the main product from our BiCIKL consortium, and we are delighted with the result!
BKH can easily be seen as the beginning of the major shift in the way we search interlinked biodiversity information.”
Biodiversity researchers, research infrastructures and publishers interested in fields ranging from taxonomy to ecology and bioinformatics can now freely use BKH as a compass to navigate the oceans of biodiversity data. BKH will do the linkages.
says Prof. Lyubomir Penev,BiCIKL’s Project coordinator and Founder of Pensoft Publishers.
The BKH is designed to serve a new emerging community of users over time and across the entire biodiversity research cycle.
We have invested our best energies and resources in the development of BKH and the Fair Data Place (FDP), which is the beating heart of the portal,”
BKH has been designed to support a new emerging community of users across the entire biodiversity research cycle.
Its purpose goes beyond the BiCIKL project itself: we are thrilled to say that BKH is meant to stay, aiming to reshape the way biodiversity knowledge is accessed and used.
The BKH outlines how users can navigate and access the linked data, tools and services of the infrastructures cooperating in BiCIKL.
By revealing how they harvest, liberate and reuse data, these increasingly integrated sources enable researchers in the natural sciences to move more seamlessly between specimens and material samples, genomic and metagenomic data, scientific literature, and taxonomic names and units.
Welcomed are taxonomic and other biodiversity-related research articles, which demonstrate the advantages and novel approaches in accessing and (re-)using linked biodiversity data
The EU-funded project BiCIKL (Biodiversity Community Integrated Knowledge Library) will support free of charge publications*submitted to the dedicated topical collection: “Linking FAIR biodiversity data through publications: The BiCIKL approach” in the Biodiversity Data Journal, demonstrating advanced publishing methods of linked biodiversity data, so that they can be easily harvested, distributed and re-used to generate new knowledge.
BiCIKL is dedicated to building a new community of key research infrastructures, researchers and citizen scientists by using linked FAIR biodiversity data at all stages of the research lifecycle, from specimens through sequencing, imaging, identification of taxa, etc. to final publication in novel, re-usable, human-readable and machine-interpretable scholarly articles.
Achieving a culture change in how biodiversity data are being identified, linked, integrated and re-used is the mission of the BiCIKL consortium. By doing so, BiCIKL is to help increase the transparency, trustworthiness and efficiency of the entire research ecosystem.
The new article collection welcomes taxonomic and other biodiversity-related research articles, data papers, software descriptions,and methodological/theoretical papers. These should demonstrate the advantages and novel approaches in accessing and (re-)using linked biodiversity data.
To be eligible for the collection, a manuscript must comply with at least two of the conditions listed below. In the submission form, the author needs tospecify the condition(s) applicable to the manuscript. The author should provide the explanation in a cover letter, using the Notes to the editor field.
All submissions must abide by the community-agreed standards for terms, ontologies and vocabularies used in biodiversity informatics.
Conditions for publication in the article collection:
The authors are expected to use explicit Globally Unique Persistent and Resolvable Identifiers (GUPRI) or other persistent identifiers (PIDs), where such are available, for the different types of data they use and/or cite in the manuscripts (specimens IDs, sequence accession numbers, taxon name and taxon treatment IDs, image IDs, etc.)
Global taxon reviews in the form of “cyber-catalogues” are welcome if they contain links of the key data elements (specimens, sequences, taxon treatments, images, literature references, etc.) to their respective records in external repositories. Taxon names in the text should not be hyperlinked. Instead, under each taxon name in the catalogue, the authors should add external links to, for example, Catalogue of Life, nomenclators (e.g. IPNI, MycoBank, Index Fungorum, ZooBank), taxon treatments in Plazi’s TreatmentBank or other relevant trusted resources.
Taxonomic papers (e.g. descriptions of new species or revisions) must contain persistent identifiers for the holotype, paratypes and at least most of the specimens used in the study.
Specimen records that are used for new taxon descriptions or taxonomic revisions and are associated with a particular Barcode Identification Number (BIN) or Species Hypothesis (SH) should be imported directly from BOLD or PlutoF, respectively, via the ARPHA Writing Tool data-import plugin.
More generally, individual specimen records used for various purposes in taxonomic descriptions and inventories should be imported directly into the manuscript from GBIF, iDigBio, or BOLD via the ARPHA Writing Tool data-import plugin.
In-text citations of taxon treatments from Plazi’s TreatmentBank are highly welcome in any taxonomic revision or catalogue. The in-text citations should be hyperlinked to the original treatment data at TreatmentBank.
Hyperlinking other terms of importance in the article text to their original external data sources or external vocabularies is encouraged.
Tables that list gene accession numbers, specimens and taxon names, should conform to the Biodiversity Data Journal’s linked data tables guidelines.
Theoretical or methodological papers on linking FAIR biodiversity data are eligible for the BiCIKL collection if they provide real examples and use cases.
Data papers or software descriptions are eligible if they use linked data from the BiCIKL’s partnering research infrastructures, or describe tools and services that facilitate access to and linking between FAIR biodiversity data.
Articles that contain nanopublications created or added during the authoring process in Biodiversity Data Journal. A nanopublication is a scientifically meaningful assertion about anything that can be uniquely identified and attributed to its author and serve to communicate a single statement, for example biotic relationship between taxa, or habitat preference of a taxon. The in-built workflow ensures the linkage and its persistence, while the information is simultaneously human-readable and machine-interpretable.
Manuscripts that contain or describe any other novel idea or feature related to linked or semantically enhanced biodiversity data will be considered too.
We recommend authors to get acquainted with these two papers before they decide to submit a manuscript to the collection:
Here are several examples of research questions that might be explored using semantically enriched and linked biodiversity data:
(1) How does linking taxon names or Operational Taxonomic Units (OTUs) to related external data (e.g. specimen records, sequences, distributions, ecological & bionomic traits, images) contribute to a better understanding of the functions and regional/local processes within faunas/floras/mycotas or biotic communities?
(2) How could the production and publication of taxon descriptions and inventories – including those based mostly on genomic and barcoding data – be streamlined?
(3) How could general conclusions, assertions and citations in biodiversity articles be expressed in formal, machine-actionable language, either to update prior work or express new facts (e.g. via nanopublications)?
(4) How could research data and narratives be re-used to support more extensive and data-rich studies?
(5) Are there other taxon- or topic-specific research questions that would benefit from richer, semantically enhanced FAIR biodiversity data?
Once published, specimen records data are being exported in Darwin Core Archive to GBIF.
The data and taxon treatments are also exported to several additional data aggregators, such as TreatmentBank, the Biodiversity Literature Repository, and SiBILS amongst others. The full-text articles are also converted to Linked Open Data indexed in the OpenBiodiv Knowledge Graph.
All articles will need to acknowledge the BiCIKL project, Grant No 101007492 in the Acknowledgements section.
* The publication fee (APC) is waived for standard-sized manuscripts (up to 40,000 characters, including spaces) normally charged by BDJ at € 650. Authors of larger manuscripts will need to cover the surplus charge (€10 for each 1,000 characters above 40,000). See more about the APC policy at Biodiversity Data Journal, or contact the journal editorial team at: bdj@pensoft.net.
Follow the BiCIKL Project on Twitter and Facebook.Join the conservation on via #BiCIKL_H2020.
You can also follow Biodiversity Data Journal on Twitter and Facebook.