Several of the BiCIKL partners signed the Leiden Declaration on FAIR Digital Objects, thereby committing to “a new environment that works as a truly meaningful data space,” as framed by the organisers of the conference, whose first instalment turned out to be the perfect occasion for the formal publication of the pact.
Key figures from Naturalis Biodiversity Center, Plazi and Pensoft were amongst the first to sign the Declaration at the closing session of the First International Conference on FAIR Digital Objects (FDO2022), which took place in October 2022 in Leiden, the Netherlands, where it was hosted by the Naturalis Biodiversity Center.
***
The conference brought together key international technical, scientific, industry and science-policy stakeholders with the aim to boost the development and implementation of FAIR Digital Objects (FDOs) worldwide. It was organised by the FDO Forum, an initiative supported by major global initiatives and by a variety of regional and national initiatives with the shared goal to achieve a better coherence amongst the increasing number of initiatives working on FDO-based designs and implementations.
By joining the Declaration’s signees, the BiCIKL partners formally committed to:
- Support the FAIR guiding principles to be applied (ultimately) to each digital object in a web of FAIR data and services;
- Support open standards and protocols;
- Support data and services to be as open as possible, and only as restricted as necessary;
- Support distributed solutions where useful to achieve robustness and scalability, but recognise the need for centralised approaches where necessary;
- Support the restriction of standards and protocols to the absolute minimum;
- Support freedom to operate wherever possible;
- Help to avoid monopolies and provider lock-in wherever possible.
***
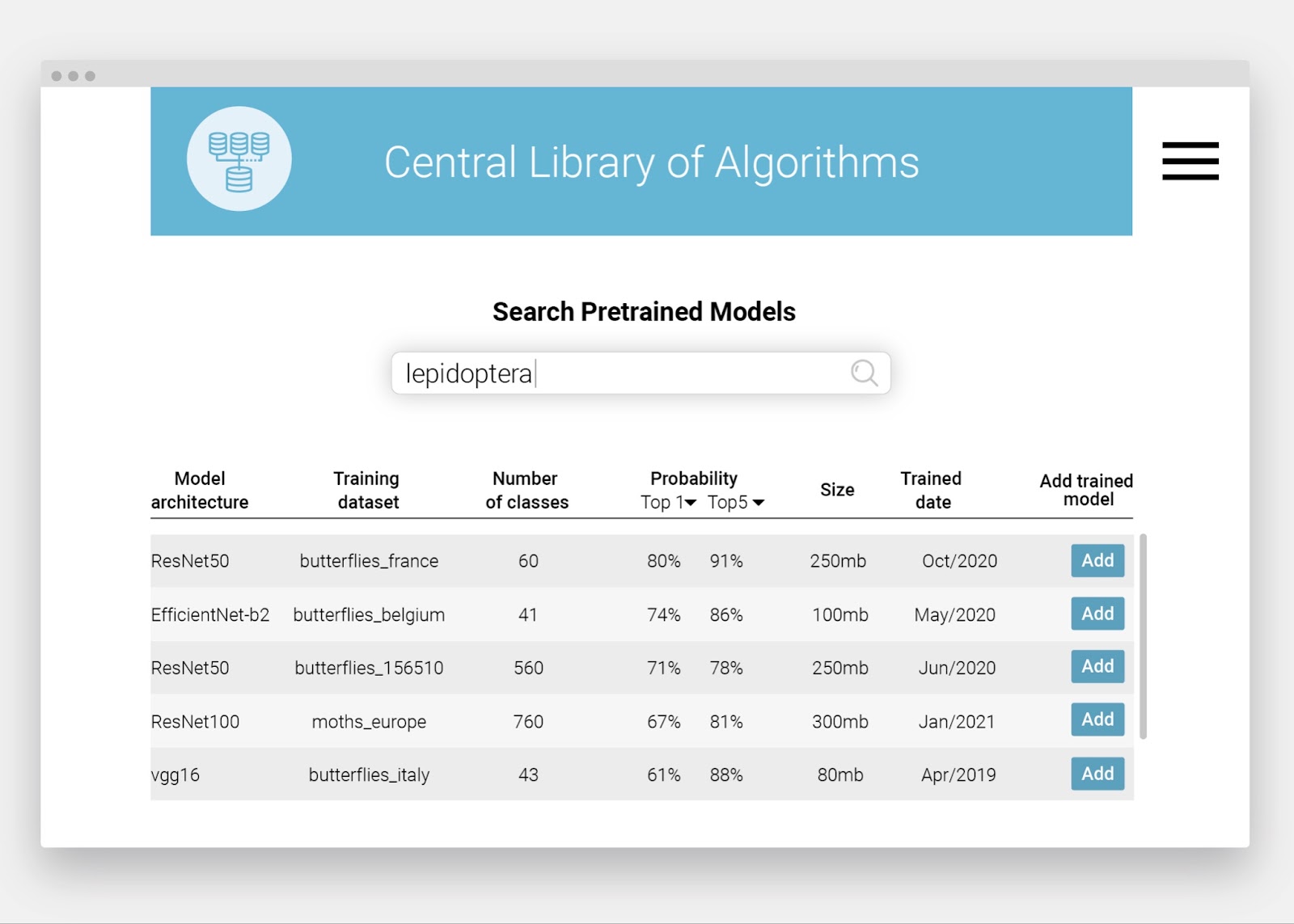
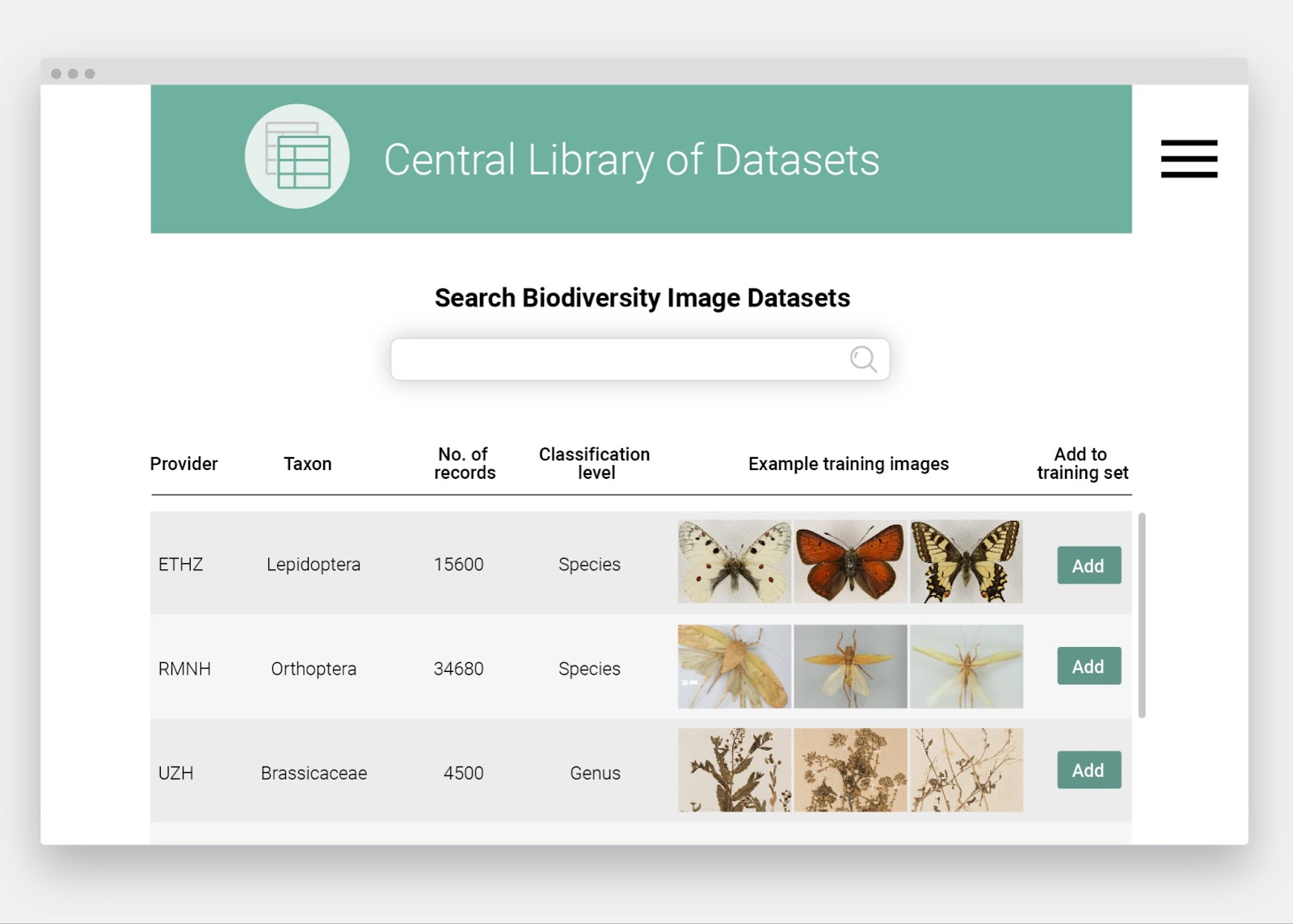
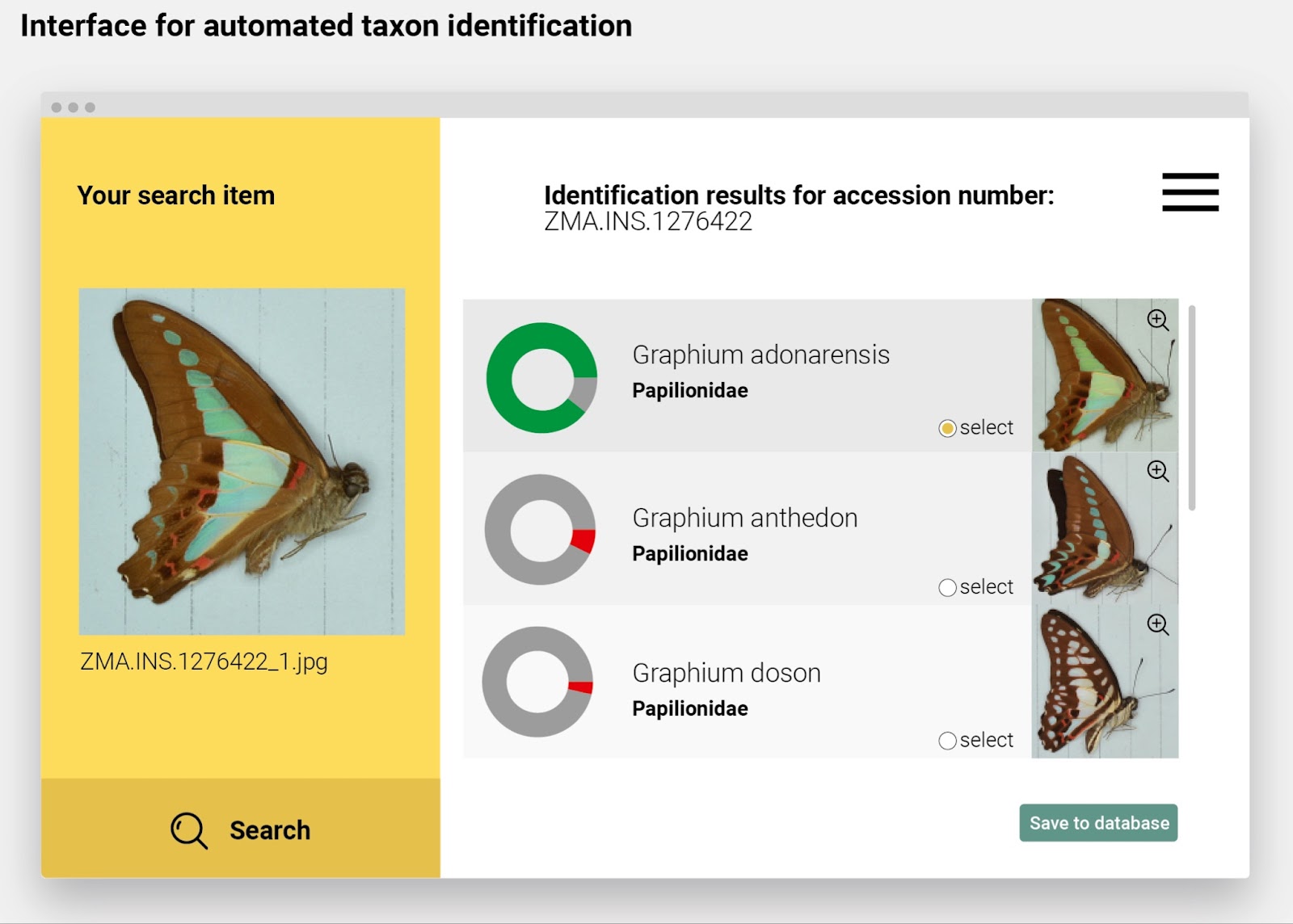
During the event, Plazi and Pensoft held a presentation demonstrating how their Biodiversity Literature Repository turns taxonomic treatments ‘locked’ in legacy scientific literature into FAIR Digital Objects. As a result of the collaboration between Plazi and Pensoft – a partnership long-preceding their involvement in BiCIKL – this workflow has also been adapted to modern-day publishing, in order to FAIRify data as soon as it is published.

***
Ahead of FDO2022, all submitted conference abstracts – including the one associated with Plazi’s presentation – were made publicly available in a collection of their own in Pensoft’s open-science journal Research Ideas and Outcomes (RIO). Thus, not only did the organisers make the conference outputs available to the participants early on, so that they can familiarise themselves with the upcoming talks and topics in advance, but they also ensure that the contributions are permanently preserved and FAIR in their own turn.
The conference collection, guest edited by Tina Loo (Naturalis Biodiversity Center), contains a total of 51 conference abstracts, where each is published in HTML, XML and PDF formats, and assigned with its own persistent identifier (DOI) just like the collection in its entirety (10.3897/rio.coll.190).
***
Read more about the declaration and sign it yourself from this link. You can also follow the FDO Forum on Twitter (@FAIRDOForum).