
In their Research Idea, published in Research Ideas and Outcomes (RIO Journal), Swiss-Dutch research team present a promising machine-learning ecosystem to unite experts around the world and make up for lacking expert staff
Guest blog post by Luc Willemse, Senior collection manager at Naturalis Biodiversity Centre (Leiden, Netherlands)
Imagine the workday of a curator in a national natural history museum. Having spent several decades learning about a specific subgroup of grasshoppers, that person is now busy working on the identification and organisation of the holdings of the institution. To do this, the curator needs to study in detail a huge number of undescribed grasshoppers collected from all sorts of habitats around the world.
The problem here, however, is that a curator at a smaller natural history institution – is usually responsible for all insects kept at the museum, ranging from butterflies to beetles, flies and so on. In total, we know of around 1 million described insect species worldwide. Meanwhile, another 3,000 are being added each year, while many more are redescribed, as a result of further study and new discoveries. Becoming a specialist for grasshoppers was already a laborious activity that took decades, how about knowing all insects of the world? That’s simply impossible.
Then, how could we expect from one person to sort and update all collections at a museum: an activity that is the cornerstone of biodiversity research? A part of the solution, hiring and training additional staff, is costly and time-consuming, especially when we know that experts on certain species groups are already scarce on a global scale.
We believe that automated image recognition holds the key to reliable and sustainable practises at natural history institutions.
Today, image recognition tools integrated in mobile apps are already being used even by citizen scientists to identify plants and animals in the field. Based on an image taken by a smartphone, those tools identify specimens on the fly and estimate the accuracy of their results. What’s more is the fact that those identifications have proven to be almost as accurate as those done by humans. This gives us hope that we could help curators at museums worldwide take better and more timely care of the collections they are responsible for.
However, specimen identification for the use of natural history institutions is still much more complex than the tools used in the field. After all, the information they store and should be able to provide is meant to serve as a knowledge hub for educational and reference purposes for present and future generations of researchers around the globe.
This is why we propose a sustainable system where images, knowledge, trained recognition models and tools are exchanged between institutes, and where an international collaboration between museums from all sizes is crucial. The aim is to have a system that will benefit the entire community of natural history collections in providing further access to their invaluable collections.
We propose four elements to this system:
- A central library of already trained image recognition models (algorithms) needs to be created. It will be openly accessible, so any other institute can profit from models trained by others.
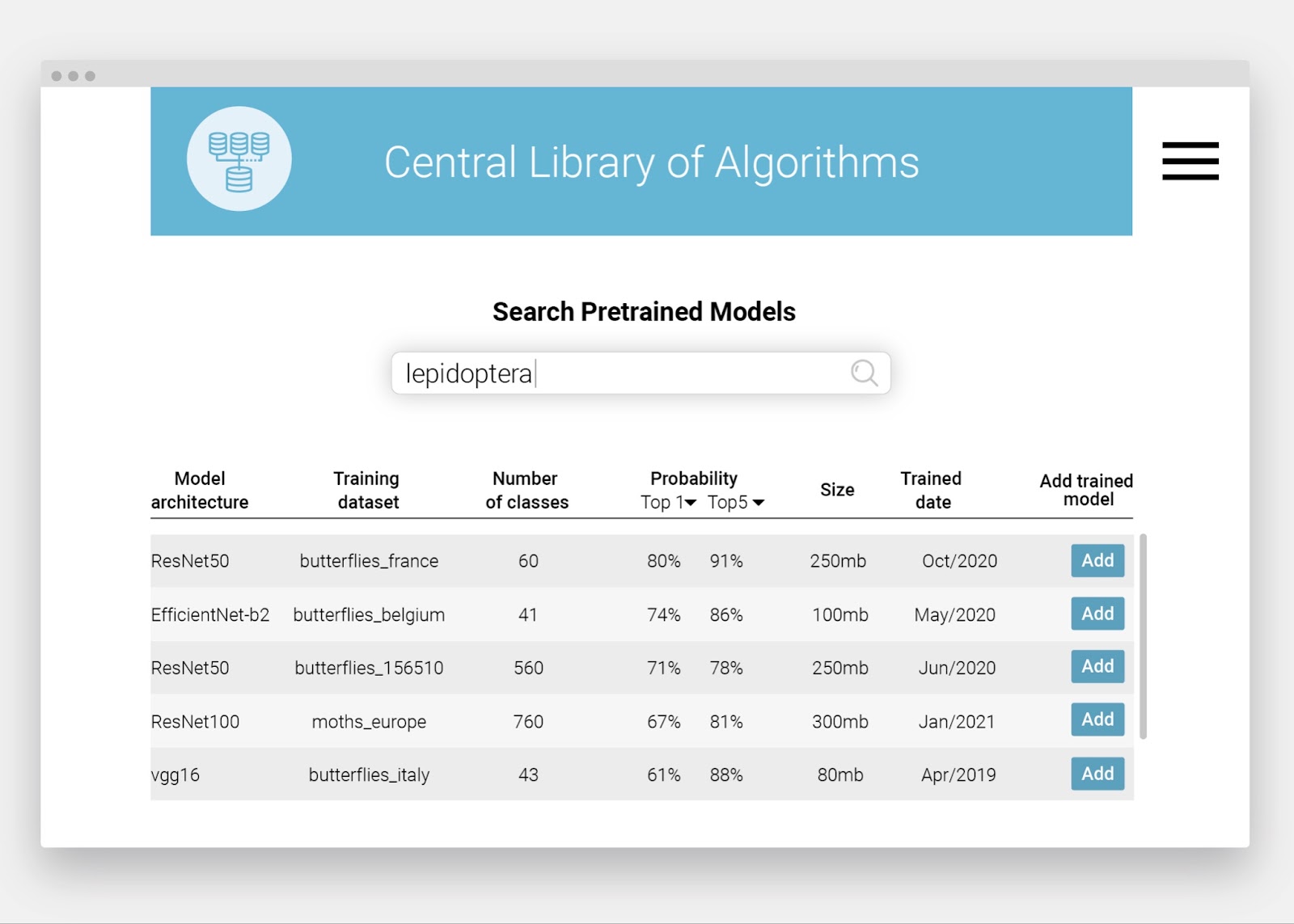
- A central library of datasets accessing images of collection specimens that have recently been identified by experts. This will provide an indispensable source of images for training new algorithms.
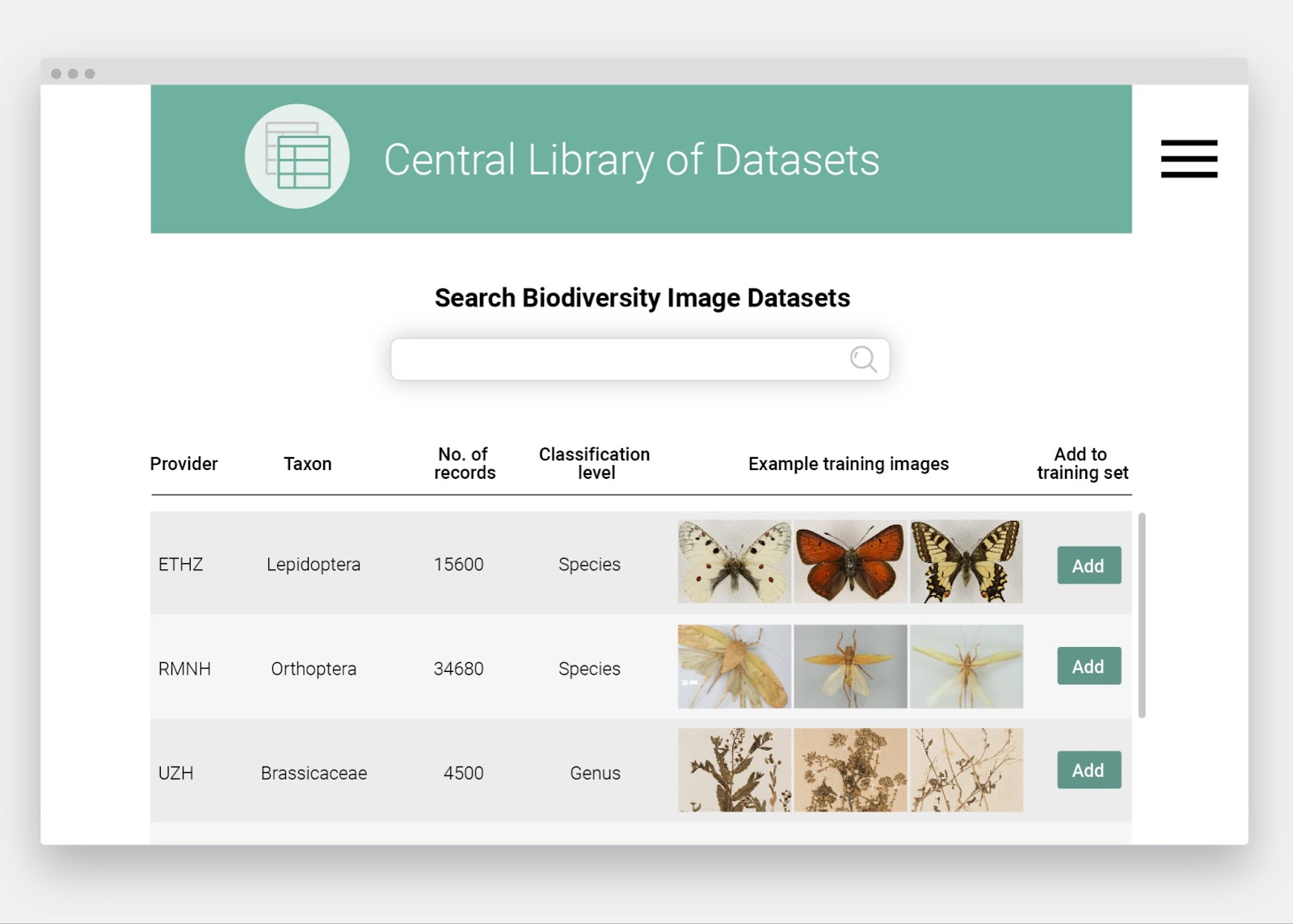
- A digital workbench that provides an easy-to-use interface for inexperienced users to customise the algorithms and datasets to the particular needs in their own collections.
- As the entire system depends on international collaboration as well as sharing of algorithms and datasets, a user forum is essential to discuss issues, coordinate, evaluate, test or implement novel technologies.
How would this work on a daily basis for curators? We provide two examples of use cases.
First, let’s zoom in to a case where a curator needs to identify a box of insects, for example bush crickets, to a lower taxonomic level. Here, he/she would take an image of the box and split it into segments of individual specimens. Then, image recognition will identify the bush crickets to a lower taxonomic level. The result, which we present in the table below – will be used to update object-level registration or to physically rearrange specimens into more accurate boxes. This entire step can also be done by non-specialist staff.


Another example is to incorporate image recognition tools into digitisation processes that include imaging specimens. In this case, image recognition tools can be used on the fly to check or confirm the identifications and thus improve data quality.
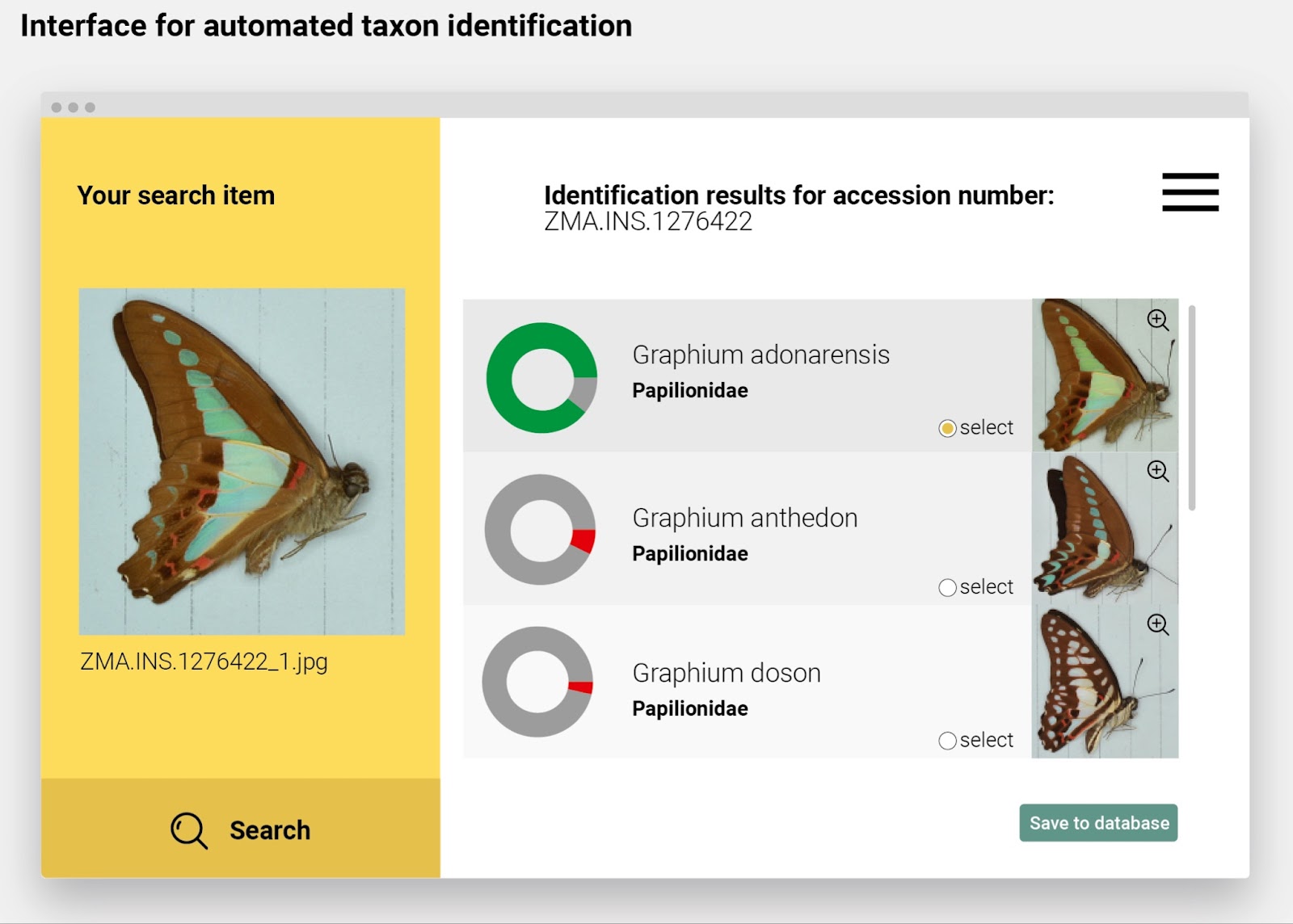
Using image recognition tools to identify specimens in museum collections is likely to become common practice in the future. It is a technical tool that will enable the community to share available taxonomic expertise.
Using image recognition tools creates the possibility to identify species groups for which there is very limited to none in-house expertise. Such practises would substantially reduce costs and time spent per treated item.
Image recognition applications carry metadata like version numbers and/or datasets used for training. Additionally, such an approach would make identification more transparent than the one carried out by humans whose expertise is, by design, in no way standardised or transparent.
*
Follow RIO Journal on Twitter and Facebook.
*
Research publication:
Greeff M, Caspers M, Kalkman V, Willemse L, Sunderland BD, Bánki O, Hogeweg L (2022) Sharing taxonomic expertise between natural history collections using image recognition. Research Ideas and Outcomes 8: e79187. https://doi.org/10.3897/rio.8.e79187





 One of the reasons tools like Xper3 are so fast and efficient is that the key’s author can list all descriptive characters in a specific order and give them different weight in species delimitation. Thus, whenever an entomologist tries to identify a wasp specimen, the software will first run a check against the descriptors at the top, so that it can exclude non-matching taxons and provide a list of the remaining names. Whenever multiple names remain, a check further down the list is performed, until there is a single one left, which ought to be the one corresponding to the specimen. At any point, the researcher can access the chronology, in order to check for any potential mismatches without interrupting the process.
One of the reasons tools like Xper3 are so fast and efficient is that the key’s author can list all descriptive characters in a specific order and give them different weight in species delimitation. Thus, whenever an entomologist tries to identify a wasp specimen, the software will first run a check against the descriptors at the top, so that it can exclude non-matching taxons and provide a list of the remaining names. Whenever multiple names remain, a check further down the list is performed, until there is a single one left, which ought to be the one corresponding to the specimen. At any point, the researcher can access the chronology, in order to check for any potential mismatches without interrupting the process.
 Another worrying result concerned type specimens – the reference specimens upon which scientific names are based. On a number of occasions, the aggregators were found to have replaced the name of a type specimen with a name tied to an entirely different type specimen.
Another worrying result concerned type specimens – the reference specimens upon which scientific names are based. On a number of occasions, the aggregators were found to have replaced the name of a type specimen with a name tied to an entirely different type specimen.