The global community is facing a number of urgent challenges, such as emerging diseases, epidemics, antimicrobial resistance, food safety, water scarcity, environmental contamination, and severe changes in biodiversity. All of them are intensified by the widespread impact of climate change. These interconnected threats demand “a fundamental shift towards systemic, integrated solutions,” a systemic change of perspective in risk management, and a long-term, action-focused strategic vision, point out representatives of Europe’s leading biodiversity, ecology and engineering communities, coordinated by the LifeWatch European Research Infrastructure Consortium (ERIC).
Together, the partners offer a unified, systemic response to these critical challenges. In the Crete Declaration, published in a policy brief in the open-science journal Research Ideas and Outcomes, they outline how scientific cooperation can be transformed into actionable policy and robust innovation.
Recognising the “intimate and inseparable link between the health of people, animals and plants and how they interact within ecosystems,” the signatories aim to significantly strengthen Europe’s resilience and global leadership by sharing data and expertise, developing innovative solutions, and promoting evidence-based policies.
They argue that research infrastructures across Europe are uniquely positioned to provide solutions “that are firmly grounded in robust science and evidence-based insights into the functioning of our living environment.”
A key message the team would like to get across is that “[p]olicies anchored in reliable data are robust and, when rooted in societal participation, they will become more feasible, impactful and widely adopted.”
In addition, research infrastructures can provide unified data and service integration through collaboration and co-creation with users and stakeholders. To this end, it is essential to embrace and support open science as a driver for scientific and social innovation.
To realise this vision, the parties commit to strengthening strategic collaboration. Another critical commitment is to advance data integration andFAIR Principles for open science by ensuring equitable access to data resources, software, workflows, standards, and protocols across domains.
To support open innovation in critical areas such as conservation, sustainable food systems, and water security, the signatories will establish a “trusted, inclusive platform for stakeholder engagement.”
Finally, they commit to providing integrated scientific knowledge to inform the policy and public, supporting effective, evidence-based policy-making and engaging citizens.
The Declaration was developed during a special assembly held in Crete in June 2025, hosted by theInstitute of Marine Biology, Biotechnology and Aquaculture at the Hellenic Centre for Marine Research.
The policy brief containing the Crete Declaration is the latest contribution to the LifeWatch ERIC Strategic Working Plan Outcomes open-science collection in the Research Ideas and Outcomes journal, a one-stop access point to the most important deliverables by the research infrastructure consortium.
Original source:
Arvanitidis C, Ameixa O, Basset A, Chatzinikolaou E, Coman C, Companys B, De Leo F, Deneudt K, Drago F, Eriksson J, Ferrari T, Georgiev T, Giuliano G, Gruber S, Habermann J, Heil K, Hubbard T, Huertas Olivares C, Kotoulas G, Koureas D, Manola N, Marrocco V, Pade N, Portugal Melo A, Provenzale A, Psomopoulos F, Raes N, Robinson S, Ruch P, Schaap D, Stanica A, Stavropoulos T, Teixeira H, van Tienderen P, Tsigenopoulos C, Waterhouse R, Aprea G, Boër M, Casino A, Delauney L, Ewbank J, Mirtl M, Pavlic-Zupanc J, Penev L, Piera J, Pitta P, Puillat I, Richter D, Stepanyan D, Ussi A, Węsławski J, Zuquim G (2025) The Crete Declaration: Uniting Science for One Health. Research Ideas and Outcomes 11: e176120. https://doi.org/10.3897/rio.11.e176120
Adverse drug reactions (ADRs) are a significant cause of hospital admissions and treatment discontinuation worldwide. Conventional approaches often fail to detect rare or delayed effects of medicinal products. In order to improve early detection, a research team from the Medical University of Sofia developed a deep learning model to predict the likelihood of ADRs based solely on a drug’s chemical structure.
The model was built using a neural network trained using reference pharmacovigilance data. Input features were derived from SMILES codes – a standard format representing molecular structure. Predictions were generated for six major ADRs: hepatotoxicity, nephrotoxicity, cardiotoxicity, neurotoxicity, hypertension, and photosensitivity.
Visual representation of SMILES and the process of molecular deconstruction. Adapted from Wu JN, Wang T, Chen Y, Tang LJ, Wu HL, Yu RQ. t-SMILES: a fragment-based molecular representation framework for de novo ligand design. Nat Commun. 2024 Jun 11;15(1): 4993. https://doi.org/10.1038/s41467-024-49388-6.
“We could conclude that it successfully identified many expected reactions while producing relatively few false positives,” the researchers write in their paper published in the journal Pharmacia, concluding it “demonstrates acceptable accuracy in predicting ADRs.”
Testing of the model with well-characterized drugs resulted in predictions consistent with known side-effect profiles. For example, it estimated a 94.06% probability of hepatotoxicity for erythromycin, 88.44% for nephrotoxicity and 75.8% for hypertension in cisplatin. Additionally, 22% photosensitivity was predicted for cisplatin, while 64.8% photosensitivity was estimated for the experimental compound ezeprogind. For enadoline, a novel molecule, the model returned low probability scores across all ADRs, suggesting minimal risk.
Notably, these results demonstrate the model’s potential as a decision-support tool in early-phase drug discovery and regulatory safety monitoring. The authors acknowledge that performance of the infrastructure could be further enhanced by incorporating factors such as dose levels and patient-specific parameters.
Research article:
Ruseva V, Dobrev S, Getova-Kolarova V, Peneva A, Getov I, Dimitrova M, Petkova V (2025) In situ development of an artificial intelligence (AI) model for early detection of adverse drug reactions (ADRs) to ensure drug safety. Pharmacia 72: 1–8. https://doi.org/10.3897/pharmacia.72.e160997
By using natural language processing, researchers created a reliable system that can automatically read and pull useful data from thousands of articles.
Guest blog post by Joseph Cornelius, Harald Detering, Oscar Lithgow-Serrano, Donat Agosti, Fabio Rinaldi, and Robert M Waterhouse
In a groundbreaking new study, scientists are using powerful computer tools to gather key information about arthropods—creatures like insects, spiders, and crustaceans—from the large and growing collection of scientific papers. The research focuses on finding details in published texts about how these animals live and interact with their environment. By using natural language processing (a type of artificial intelligence that helps computers understand human language), the team created a reliable system that can automatically read and pull useful data from thousands of articles. This innovative method not only helps us learn more about the variety of life on Earth, but also supports efforts to solve environmental challenges by making it easier to access important biological information.
Mining the literature to identify species, their traits, and associated values.
The challenge
Scientific literature contains vast amounts of essential data about species—like what arthropods eat, where they live, and how big they are. However, this information is often trapped in hard-to-access files and old publications, making large-scale analysis almost impossible. So how can we convert these pages into usable data?
The goal
The team set out to develop an automatic text‑mining system using Natural Language Processing (NLP) and machine learning to scan thousands of biology papers and extract structured information about insects and other arthropods to build a database linking species names with traits like “leg length” or “forest habitat” or “predator”.
How it works in practice
Collect curated vocabularies of terms to be searched for in the texts:
Identified ~656,000 entities (species, traits, values) and ~339,000 links between them
Publish results in an open searchable online resource:
Developed ArTraDB, an interactive web database where users can search, view, and visualise species‑trait pairs and full species‑trait‑value triples
Text-mining is a conceptually and computationally challenging task.
What is needed for the next steps
Annotation complexity: Even experts struggled to agree on boundaries and precise relationships, underscoring the need for clearer guidelines and more training examples to improve the performance of the models
Gaps in the vocabularies of terms: Many were unrecognised due to missing synonyms, outdated species names, and variations in phrasing. Expanding vocabularies will help improve the ability to find the species, traits, and values
Community curation: Planned features in ArTraDB will allow scientists and citizen curators to improve annotations, helping retrain and refine the models over time
How it impacts science
Speeds up research: Scientists can find species‑trait data quickly and accurately, boosting studies in ecology, evolution, and biodiversity
Scale and scope: This semi‑automated method can eventually be extended well beyond arthropods to other species
Supports global biodiversity efforts: Enables creation of large, quantitative trait datasets essential for monitoring ecosystem changes, climate impact, and conservation strategies
A long-term vision to connect species with knowledge about their biology.
The outcomes
This innovative work demonstrates how combining text mining, expert curation, and interactive databases can unlock centuries of biological research. It lays a scalable foundation for building robust, open-access trait databases—empowering both scientists and the public to explore the living world in unprecedented ways.
Research article:
Cornelius J, Detering H, Lithgow-Serrano O, Agosti D, Rinaldi F, Waterhouse R (2025) From literature to biodiversity data: mining arthropod organismal traits with machine learning. Biodiversity Data Journal 13: e153070. https://doi.org/10.3897/BDJ.13.e153070
It is nothing new that our planet is facing a number of serious threats: climate change, biodiversity loss, pandemics… If you have been watching the news, all this is probably familiar to you. The wealth of data hosted in Natural history collections can contribute to finding a response to these challenges.Alas, today’s practices of working with collected bio- and geodiversity specimens lack some efficiency, thus limiting what our scientists can achieve.
In particular, there is a rather serious absence of linkages between specimen data. Sure, each specimen in a collection usually has its own catalogue ID that is unique within that collection, but the moment collections attempt to work with other collections -as they should in the face of planetary threats- problems start to arise because usually, each collection has its own way of identifying their data, thus leading to confusion.
Persistent identifiers: the DOIs
To avoid this problem, several initiatives have been launched in recent years to establish a globally accepted system of persistent identifiers (PIDs) that guarantee the “uniqueness” of collection specimens—physical or digital—over time.
Digital specimen DOIs can point to individual specimens in a collections.
You can think of a PID as a marker, an identifier that points at a single individual object and only one, differentiating it from any other in the world. You must have heard of acronyms such as ISBN or ORCID. Those are PIDs for books and individual scholars, respectively. For digital research content, the most widely used PID is the DOI (Digital Object Identifier), proposed by the DOI Foundation.
A DOI is an alphanumeric code that looks like this: 10.prefix/sufix
For example, if you type https://doi.org/10.15468/w6ubjx in your browser, you will reach the Royal Belgian Institute of Natural Sciences’s mollusk collection database, accessed through GBIF. This specific DOI will never point at anything else, and the identifier will remain the same in the future, even if changes occur in the content of this particular database.
DiSSCo and the DOIs
The Distributed System of Scientific Collections (DiSSCo) aims to provide a DOI for all individual digital specimens in European natural history collections. The point is not only to accurately identify specimens. That is, of course, crucial, but the DOI of a digital specimen provides a number of other advantages that are extremely interesting for DiSSCo and natural history collections in general. Among them, two are simply revolutionary.
The digital specimen DOI stores quick-access, basic metadata about the specimen.
Firstly, using DOIs allows linking the digital specimen to all other relevant information about the same specimen that might be hosted in other repositories (e.g. ecological data, genomic data, etc.). In creating this extended digital specimen that links different data types, digital specimen DOIs make a huge contribution to inter-institutional scientific work, filling the gap that is described at the beginning of this piece. Now scientists will be in a much better position to really exchange and link data across institutions.
Second, in contrast to most other persistent identifiers, the DOI of a digital specimen stores additional metadata (e.g. name, catalogue number) beyond the URL to which it redirects. This allows access to some information about the specimen without having to retrieve the full data object, i.e. without having to be redirected to the specimen HTML page. This metadata facilitates AI systems to quickly navigate billions of digital specimens and perform different automated work on them, saving us (humans) precious time.
Use of DOIs in publications
With all this in mind, it is easier to understand why being able to cite digital specimens in scholarly publications using DOIs is an important step. So far, the only DOIs that we could use in publications were those at the dataset level, not at the individual specimen level. In the example above, if a scientist were to publish an article about a specific type of bivalve in the Belgian collection, the only DOI that she or he would have available for citation in the article would be that of the entire mollusk database -containing hundreds or thousands of specimens- not the one of the specific oyster or scallop that might be the focus of the publication.
Main page of DiSSCo’s sandbox, the future DiSSCover service.
The publication in Biodiversity Data Journalabout the Chrysilla and Phintelloides genera is the first of its kind and opens the door to citing not only dataset-level objects but also individual specimens in publications using DOIs. You can try it yourself: Hover over the DOIs that are cited in the publication and you will get some basic information that might save you the time of visiting the page of the institution where the specimen is. Click on it and you will be taken to DiSSCo’s sandbox -the future DiSSCover service- where you will find all the information about the digital specimen. There you will also be able to comment, annotate the specimen, and more, thus making science in a more dynamic and efficient way than until now.
A note about Christa Deeleman-Reinhold
At 94 years old, the Dutch arachnologist Christa Deeleman-Reinhold is not only one of the authors of the Chrysilla and Phintelloides article but also one of the most important arachnologists in the world. Born in 1930 on the island of Java -then part of the Dutch East Indies- Christa gained her PhD from Leiden University in 1978. Since then, she has developed a one-of-a-kind scientific career, mainly focused on spider species from South Asia. In her Forest Spiders of South East Asia (2001), Dr. Deeleman-Reinhold revised six spider families, describing 18 new genera and 115 new species. The Naturalis Biodiversity Center hosts the Christa Laetitia Deeleman-Reinhold collection, with more than 20,000 specimens.
Text and images provided by DiSSCo RI.
Research article:
Deeleman-Reinhold CL, Addink W, Miller JA (2024) The genera Chrysilla and Phintelloides revisited with the description of a new species (Araneae, Salticidae) using digital specimen DOIs and nanopublications. Biodiversity Data Journal 12: e129438. https://doi.org/10.3897/BDJ.12.e129438
A post on social media asked about plant genera named for women and sparked a lively discussion with many contributors. This simple question was not as easily answered as initially thought. The resulting informal working group tackled this topic remotely during the COVID-19 pandemic and beyond. The team was motivated by the desire to amplify the contribution of women to botany through eponymy. The work of this team has so far resulted in a paper in Biodiversity Data Journal, presentations at several conferences, and a linked open dataset.
Prior to our international collaboration, no dataset was available to answer these simple questions and the required information was scattered in many different data sources. We set out to bring these data together and in doing so developed and refined our workflow. Our data paper documents this innovative workflow bringing together the various data elements needed to answer our research questions. Ultimately we created a Linked Open Data (LOD) dataset that amplified the names of women and female mythological beings celebrated through generic names of flowering plants.
🙋🏻♀️Inspired by the melastome plant genus 𝘔𝘦𝘳𝘪𝘢𝘯𝘪𝘢: which plant genera do you know that honor women? Who were/are they? 🌺 ¿Qué géneros de plantas dedicados a mujeres conoces? ¿Quienes fueron/son? 🧵👇🏽 #WomenInSTEMhttps://t.co/QWpyaMfihTpic.twitter.com/XBCYD6hmx1
During our research process we focused on pulling data from a wide variety of sources while at the same time proactively sharing the data generated as widely as possible. This was done by adding and linking it to multiple public databases and sources (push-pull) including the International Plant Name Index (hereafter IPNI), Tropicos®, Wikidata, Bionomia and the Biodiversity Heritage Library (hereafter BHL).
Visualisation of our workflow to create a working list of flowering plant genera named for women.
For our list of genera, each of the protologues were reviewed to confirm the etymology or eponymy. To find the generic prologues, we searched botanical databases such as IPNI and Tropicos, openly accessible providers of digital publications and other digital libraries and websites that provide free access to such publications. Here the BHL was invaluable as the majority of protologues and many other relevant publications were openly accessible through this digital library. Where no digital publication was available we accessed scientific literature through our affiliated institutions.
For the women, our starting point was the “Index of Eponymic Plant Names – Extended Edition” by Lotte Burkhardt (2018). We manually extracted all genera honouring women. This dataset was supplemented with other sources including IPNI (2023), Mari Mut (2017-2021), a 2022 updated version of Burkhardt’s document (Burkhardt 2022), as well as suggestions received from colleagues and generated from our own research.
We collected the following information as structured data: information on the woman honoured, the genera named in honour of the woman, the year and place of the protologue or original publication (the nomenclatural reference), the author(s) of the genus name, and the link to the protologue or original publication if available online.
Wikidata
Wikidata was the central data repository and linking mechanism for this project as it provided structured data that can be read and edited by humans and machines and it acts as a hub for other identifiers. As such Wikidata played a central role in semantic linking and enriching of our data.
Wikidata items for the plant genera were created or enriched with information about the name, the author(s) of the genus and the year of publication. Those statements were referenced using the original publication. If the protologue was available on BHL, the BHL bibliographic or page number was added to that reference, thus creating a digital link improving access to the protologue. While undertaking this work we also collated a list of all those public domain publications that appeared to be absent from BHL. We passed on this list to BHL and requested these texts be scanned and added to BHL for the benefit of everyone.
We then added a named afterstatement to the Wikidata item for the appropriate plant genera linking that item to the Wikidata item for the woman honoured. Wikidata items for the women honoured were newly created or enriched. We researched each person and her contributions, plus information on mythological figures where necessary, and added this information to Wikidata items. Our work also included disambiguating the woman from other people with identical or similar names.
To amplify the women’s contributions to science and to enrich the wider (biodiversity) data ecosystem, we linked to other Wikidata items and websites or databases by adding other relevant identifiers. For example if the women were botanists, botanical collectors or other naturalists, we used the author property to link the women to publications written by them. In addition, we added the women to Bionomia and attributed specimens collected or identified by them to their profiles.
Our work also included enriching Wikidata items of taxon authors. IPNI and Tropicos were searched for these author names, and websites such as BHL, the Global Biodiversity Information Facility (GBIF) or other specialist databases were consulted. Corrections or newly researched information on taxon authors was placed not just in Wikidata but was also sent together with the corresponding references to IPNI and Tropicos. This information was then used by those organizations to update these databases accordingly.
As a result of our data being placed in Wikidata it is available to be queried via the Wikidata Query Service.
Our Goal Achieved
As a result of our project, we published a dataset of 728 genera honouring women or female beings. This was a nearly twenty-fold increase in the number of genera linked to women in Wikidata. Our analysis paper on this data is forthcoming.
Notable Women
Monsonia L.
All of us came away from this research with a favourite story. One that stood out was Ann Monson, for whom Linnaeus named Monsonia. Linnaeus wrote a delightful letter to her about their creating, platonically of course, a kind of plant love-child between them, in the form of this new genus.
Translated from Latin: “….Lock these [seeds] in a pot, and place them in the window of the chamber towards the sun, when it bursts forth in February, and in the first summer the sun blooms and lasts the most beautiful Alstromeria, which no one has seen in England, and you bring forth no flowers. If it should come to pass, as I wish, if you offer our flames, I would only wish to beget with you an only child, as a pledge of my love, little Monsonia, by which you may perpetuate the fame of Lady in the kingdom of Flora, who was the Queen of Women.”
Fittonia Coem.
Two eponymous women with an interesting story are Sarah Mary Fitton and her sister Elizabeth. They wrote Conversations on Botany in 1817 accompanied by colour engravings of flowers which popularised botany with women. The genus Fittonia was named in their honour.
Chanekia Lundell
Another woman honoured in a plant genus was Mercedes Chanek, a Mayan plant collector who worked in the 1930’s for Cyrus Longworth Lundell and collected for the University of Michigan in British Honduras, today Belize. Very little is known about her life and work. However, her collections are detailed in Tropicos and Bionomia, and you can see the genus named for her by Lundell in IPNI under Chanekia.
An example of a mythological female being honoured in several plant names is that of Medusa, who has the most genera named after her, six, more than any real woman!
We hope that our data paper inspires others to use the methodology and workflow described to create other linked open datasets, e.g. celebrating and amplifying the contributions of underrepresented or marginalised groups in science.
Data paper:
von Mering S, Gardiner LM, Knapp S, Lindon H, Leachman S, Ulloa Ulloa C, Vincent S, Vorontsova MS (2023) Creating a multi-linked dynamic dataset: a case study of plant genera named for women. Biodiversity Data Journal 11: e114408. https://doi.org/10.3897/BDJ.11.e114408
Measuring the extent and dynamics of the global biodiversity crisis is a challenging task that demands rapid, reliable and repeatable biodiversity monitoring data. Such data is essential for policymakers to be able to assess policy options effectively and accurately. To achieve this, however, there is a need to enhance the integration of biodiversity data from various sources, including citizen scientists, museums, herbaria, and researchers.
B-Cubed’s response
B-Cubed (Biodiversity Building Blocks for policy) hopes to tackle this challenge by reimagining the process of biodiversity monitoring, making it more adaptable and responsive.
B-Cubed’s approach rests on six pillars:
Improved alignment between policy and biodiversity data. Working closely with existing biodiversity initiatives to identify and meet policy needs.
Evidence base. Leveraging data cubes to standardise access to biodiversity data using the Essential Biodiversity Variables framework. These cubes are the basis for models and indicators of biodiversity.
Cloud computing environment. Providing users with access to the models in real-time and on demand.
Automated workflows. Developing exemplary automated workflows for modelling using biodiversity data cubes and for calculating change indicators.
Case studies. Demonstrating the effectiveness of B-Cubed’s tools.
Capacity building. Ensuring that the solutions meet openness standards and training end-users to employ them.
Pensoft’s role
Harnessing its experience in the communication, dissemination and exploitation of numerous EU projects, Pensoft focuses on maximising B-Cubed’s impact and ensuring the adoption and long-term legacy of its results. This encompasses a wide array of activities, ranging all the way from building the project’s visual and online presence to translating its results into policy recommendations. Pensoft also oversees B-Cubed’s data management by developing a Data Management Plan which ensures the implementation of the FAIR data principles and maximises the access to and re-use of the project’s research outputs.
Proofreading the text of scientific papers isn’t hard, although it can be tedious. Are all the words spelled correctly? Is all the punctuation correct and in the right place? Is the writing clear and concise, with correct grammar? Are all the cited references listed in the References section, and vice-versa? Are the figure and table citations correct?
Proofreading of text is usually done first by the reviewers, and then finished by the editors and copy editors employed by scientific publishers. A similar kind of proofreading is also done with the small tables of data found in scientific papers, mainly by reviewers familiar with the management and analysis of the data concerned.
But what about proofreading the big volumes of data that are common in biodiversity informatics? Tables with tens or hundreds of thousands of rows and dozens of columns? Who does the proofreading?
Sadly, the answer is usually “No one”. Proofreading large amounts of data isn’t easy and requires special skills and digital tools. The people who compile biodiversity data often lack the skills, the software or the time to properly check what they’ve compiled.
The result is that a great deal of the data made available through biodiversity projects like GBIF is — to be charitable — “messy”. Biodiversity data often needs a lot of patient cleaning by end-users before it’s ready for analysis. To assist end-users, GBIF and other aggregators attach “flags” to each record in the database where an automated check has found a problem. These checks find the most obvious problems amongst the many possible data compilation errors. End-users often have much more work to do after the flags have been dealt with.
In 2017, Pensoft employed a data specialist to proofread the online datasets that are referenced in manuscripts submitted to Pensoft’s journals as data papers. The results of the data-checking are sent to the data paper’s authors, who then edit the datasets. This process has substantially improved many datasets (including those already made available through GBIF) and made them more suitable for digital re-use. At blog publication time, more than 200 datasets have been checked in this way.
Note that a Pensoft data audit does not check the accuracy of the data, for example, whether the authority for a species name is correct, or whether the latitude/longitude for a collecting locality agrees with the verbal description of that locality. For a more or less complete list of what does get checked, see the Data checklist at the bottom of this blog post. These checks are aimed at ensuring that datasets are correctly organised, consistently formatted and easy to move from one digital application to another. The next reader of a digital dataset is likely to be a computer program, not a human. It is essential that the data are structured and formatted, so that they are easily processed by that program and by other programs in the pipeline between the data compiler and the next human user of the data.
Pensoft’s data-checking workflow was previously offered only to authors of data paper manuscripts. It is now available to data compilers generally, with three levels of service:
Basic: the compiler gets a detailed report on what needs fixing
Standard: minor problems are fixed in the dataset and reported
Premium: all detected problems are fixed in collaboration with the data compiler and a report is provided
Because datasets vary so much in size and content, it is not possible to set a price in advance for basic, standard and premium data-checking. To get a quote for a dataset, send an email with a small sample of the data topublishing@pensoft.net.
—
Data checklist
Minor problems:
dataset not UTF-8 encoded
blank or broken records
characters other than letters, numbers, punctuation and plain whitespace
more than one version (the simplest or most correct one) for each character
unnecessary whitespace
Windows carriage returns (retained if required)
encoding errors (e.g. “Dum?ril” instead of “Duméril”)
missing data with a variety of representations (blank, “-“, “NA”, “?” etc)
Major problems:
unintended shifts of data items between fields
incorrect or inconsistent formatting of data items (e.g. dates)
different representations of the same data item (pseudo-duplication)
for Darwin Core datasets, incorrect use of Darwin Core fields
data items that are invalid or inappropriate for a field
data items that should be split between fields
data items referring to unexplained entities (e.g. “habitat is type A”)
truncated data items
disagreements between fields within a record
missing, but expected, data items
incorrectly associated data items (e.g. two country codes for the same country)
duplicate records, or partial duplicate records where not needed
For details of the methods used, see the author’s online resources:
Pensoft creates a specialised data paper article type for the omics community within Biodiversity Data Journal to reflect the specific nature of omics data. The scholarly publisher and technology provider established a manuscript template to help standardise the description of such datasets and their most important features.
By Mariya Dimitrova, Raïssa Meyer, Pier Luigi Buttigieg, Lyubomir Penev
Data papers are scientific papers which describe a dataset rather than present and discuss research results. The concept was introduced to the biodiversity community by Chavan and Penev in 2011 as the result of a joint project of GBIF and Pensoft.
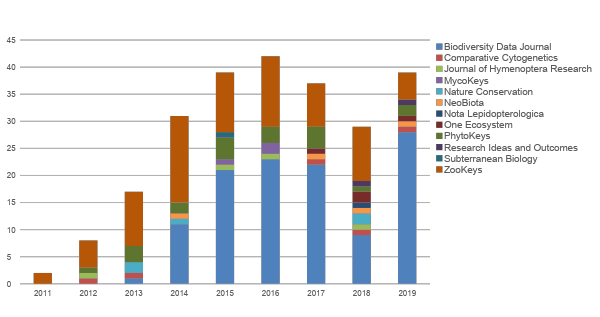
Since then, Pensoft has implemented the data paper in several of its journals (Fig. 1). The recognition gained through data papers is an important incentive for researchers and data managers to author better quality metadata and to make it Findable, Accessible, Interoperable and Re-usable (FAIR). High quality and FAIRness of (meta)data are promoted through providing peer review, data audit, permanent scientific record and citation credit as for any other scholarly publication. One can read more on the different types of data papers and how they help to achieve these goals in the Strategies and guidelines for scholarly publishing of biodiversity data (https://doi.org/10.3897/rio.3.e12431).
Fig. 1 Number of data papers published in Pensoft’s journals since 2011.
The data paper concept was initially based on the standard metadata descriptions, using the Ecological Metadata Language (EML). Apart from distinguishing a specialised place for dataset descriptions by creating a data paper article type, Pensoft has developed multiple workflows for streamlined import of metadata from various repositories and their conversion into data paper a manuscripts in Pensoft’s ARPHA Writing Tool (AWT). You can read more about the EML workflow in this blog post.
Similarly, we decided to create a specialised data paper article type for the omics community within Pensoft’s Biodiversity Data Journal to reflect the specific nature of omics data. We established a manuscript template to help standardise the description of such datasets and their most important features. This initiative was supported in part by the IGNITE project.
How can authors publish omics data papers?
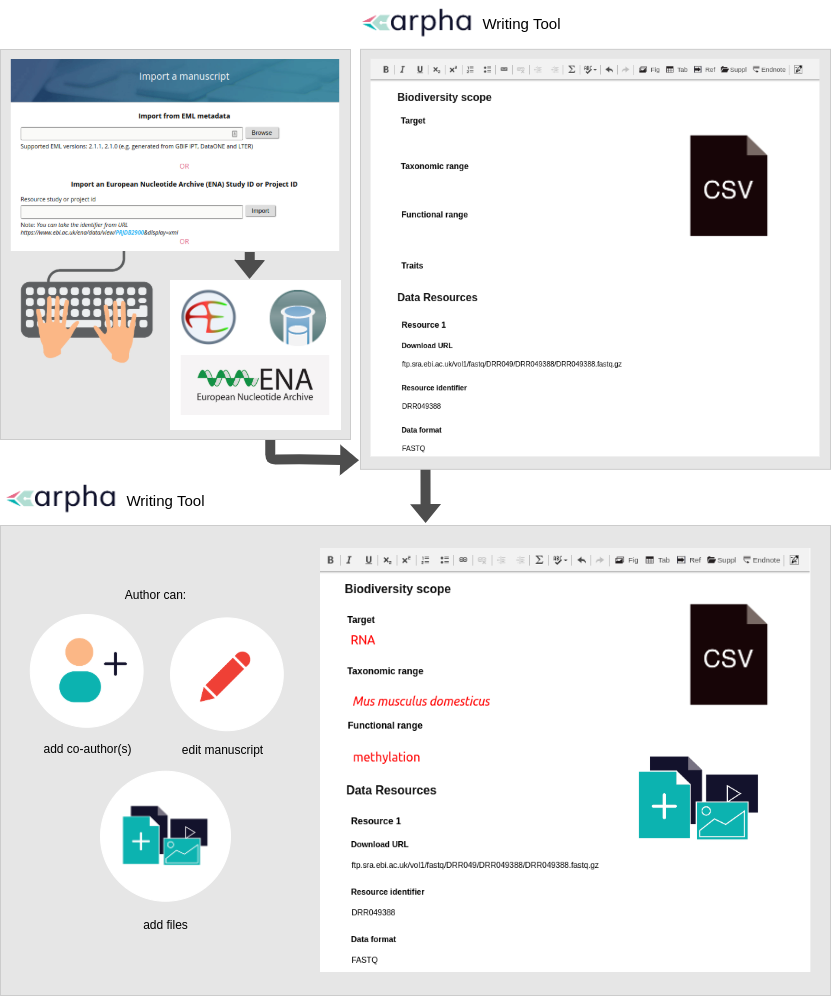
There are two ways to do publish omics data papers – (1) to write a data paper manuscript following the respective template in the ARPHA Writing Tool (AWT) or (2) to convert metadata describing a project or study deposited in EMBL-EBI’s European Nucleotide Archive (ENA) into a manuscript within the AWT.
The first method is straightforward but the second one deserves more attention. We focused on metadata published in ENA, which is part of the International Nucleotide Sequence Database Collaboration (INSDC) and synchronises its records with these of the other two members (DDBJ and NCBI). ENA is linked to the ArrayExpress and BioSamples databases, which describe sequencing experiments and samples, and follow the community-accepted metadata standards MINSEQE and MIxS. To auto populate a manuscript with a click of a button, authors can provide the accession number of the relevant ENA Study of Project and our workflow will automatically retrieve all metadata from ENA, as well as any available ArrayExpress or BioSamples records linked to it (Fig. 2). After that, authors can edit any of the article sections in the manuscript by filling in the relevant template fields or creating new sections, adding text, figures, citations and so on.
An important component of the OMICS data paper manuscript is a supplementary table containing MIxS-compliant metadata imported from BioSamples. When available, BioSamples metadata is automatically converted to a long table format and attached to the manuscript. The authors are not permitted to edit or delete it inside the ARPHA Writing Tool. Instead, if desired, they should correct the associated records in the sourced BioSamples database. We have implemented a feature allowing the automatic re-import of corrected BioSamples records inside the supplementary table. In this way, we ensure data integrity and provide a reliable and trusted source for accessing these metadata.
Fig. 2 Automated generation of omics data paper manuscripts through import and conversion of metadata associated with the Project ID or Study ID at ENA
Here is a step-by-step guide for conversion of ENA metadata into a data paper manuscript:
The author has published a dataset to any of the INSDC databases. They copy its ENA Study or Project accession number.
The author goes to the Biodiversity Data Journal (BDJ) webpage, clicks the “Start a manuscript” buttоn and selects OMICS Data Paper template in the ARPHA Writing Tool (AWT). Alternatively, the author can also start from the AWT website, click “Create a manuscript”, and select “OMICS Data Paper” as the article type, the Biodiversity Data Journal will be automatically marked by the system. The author clicks the “Import a manuscript” button at the bottom of the webpage.
The author pastes the ENA Study or Project accession number inside the relevant text box (“Import an European Nucleotide Archive (ENA) Study ID or Project ID”) and clicks “Import”.
The Project or Study metadata is converted into an OMICS data paper manuscript along with the metadata from ArrayExpress and BioSamples if available. The author can start making changes to the manuscript, invite co-authors and then submit it for technical evaluation, peer review and publication.
Our innovative workflow makes authoring omics data papers much easier and saves authors time and efforts when inserting metadata into the manuscript. It takes advantage of existing links between data repositories to unify biodiversity and omics knowledge into a single narrative. This workflow demonstrates the importance of standardisation and interoperability to integrate data and metadata from different scientific fields.
We have established a special collection for OMICS data papers in the Biodiversity Data Journal. Authors are invited to describe their omics datasets by using the novel streamlined workflow for creating a manuscript at a click of a button from metadata deposited in ENA or by following the template to create their manuscript via the non-automated route.
To stimulate omics data paper publishing, the first 10 papers will be published free of charge. Upon submission of an omics data paper manuscript, do not forget to assign it to the collection Next-generation publishing of omics data.
Teams from Ghana, Malawi, Namibia and Rwanda during the inception meeting of the African Biodiversity Challenge Project in Kigali, Rwanda. Photo by Yvette Umurungi.
The establishment and implementation of a long-term strategy for freshwater biodiversity data mobilisation, sharing, processing and reporting in Rwanda is to support environment monitoring and the implementation of Rwanda’s National Biodiversity Strategy (NBSAP). In addition, it is to also help us understand how economic transformation and environmental change is affecting freshwater biodiversity and its resulting ecosystem services.
The CoEB has a national mandate to lead on biodiversity data mobilisation and implementation of the NBSAP in collaboration with REMA. This includes digitising data from reports, conducting analyses and reporting for policy and research, as indicated in Rwanda’s NBSAP.
The collation of the data will follow the international standards and will be available online, so that they can be accessed and reused from around the world. In fact, CoEB aspires to become a Global Biodiversity Informatics Facility (GBIF) node, thereby strengthening its capacity for biodiversity data mobilisation.
Data use training for the African Biodiversity Challenges at the South African National Biodiversity Institute (SANBI), South Africa. Photo by Yvette Umurungi.
The mobilised data will be organised using GBIF standards, and the project will leverage the tools developed by GBIF to facilitate data publication. Additionally, it will also provide an opportunity for ARCOS to strengthen its collaboration with CoEB as part of its endeavor to establish a regional network for biodiversity data management in the Albertine Rift Region.
The project is expected to conclude with at least six datasets, which will be published through the ARCOS Biodiversity Information System. These are to include three datasets for the Kagera River Basin; one on freshwater macro-invertebrates from the Congo and Nile Basins; one for the Rwanda Development Board archive of research reports from protected areas; and one from thesis reports from master’s and bachelor’s students at the University of Rwanda.
The project will also produce and release the first “Rwandan State of Freshwater Biodiversity”, a document which will describe the status of biodiversity in freshwater ecosystems in Rwanda and present socio-economic conditions affecting human interactions with this biodiversity.
The page of Center of Excellence in Biodiversity and Natural Resource Management (CoEB) at University of Rwanda on the Global Biodiversity Information Facility portal. Image by Yvette Umurungi.
Umurungi Y, Kanyamibwa S, Gashakamba F, Kaplin B (2018) African Biodiversity Challenge: Integrating Freshwater Biodiversity Information to Guide Informed Decision-Making in Rwanda. Biodiversity Information Science and Standards 2: e26367. https://doi.org/10.3897/biss.2.26367
In an effort to improve the quality of biodiversity records, the Atlas of Living Australia (ALA) and the Global Biodiversity Information Facility (GBIF) use automated data processing to check individual data items. The records are provided to the ALA and GBIF by museums, herbaria and other biodiversity data sources.
However, an independent analysis of such records reports that ALA and GBIF data processing also leads to data loss and unjustified changes in scientific names.
The study was carried out by Dr Robert Mesibov, an Australian millipede specialist who also works as a data auditor. Dr Mesibov checked around 800,000 records retrieved from the Australian Museum, Museums Victoria and the New Zealand Arthropod Collection. His results are published in the open access journal ZooKeys, and also archived in a public data repository.
“I was mainly interested in changes made by the aggregators to the genus and species names in the records,” said Dr Mesibov.
“I found that names in up to 1 in 5 records were changed, often because the aggregator couldn’t find the name in the look-up table it used.”
Another worrying result concerned type specimens – the reference specimens upon which scientific names are based. On a number of occasions, the aggregators were found to have replaced the name of a type specimen with a name tied to an entirely different type specimen.
The biggest surprise, according to Dr Mesibov, was the major disagreement on names between aggregators.
“There was very little agreement,” he explained. “One aggregator would change a name and the other wouldn’t, or would change it in a different way.”
Furthermore, dates, names and locality information were sometimes lost from records, mainly due to programming errors in the software used by aggregators to check data items. In some data fields the loss reached 100%, with no original data items surviving the processing.
“The lesson from this audit is that biodiversity data aggregation isn’t harmless,” said Dr Mesibov. “It can lose and confuse perfectly good data.”
“Users of aggregated data should always download both original and processed data items, and should check for data loss or modification, and for replacement of names,” he concluded.






































 Another worrying result concerned type specimens – the reference specimens upon which scientific names are based. On a number of occasions, the aggregators were found to have replaced the name of a type specimen with a name tied to an entirely different type specimen.
Another worrying result concerned type specimens – the reference specimens upon which scientific names are based. On a number of occasions, the aggregators were found to have replaced the name of a type specimen with a name tied to an entirely different type specimen.