The city of Cambridge and the Wellcome Campus hosted the Final General Assembly of the EU-funded project BiCIKL (acronym for Biodiversity Community Integrated Knowledge Library): a 36-month endeavour that saw 14 member institutions and 15 research infrastructures representing diverse actors from the biodiversity data realm come together to improve bi-directional links between different platforms, standards, formats and scientific fields. Consortium members who could not attend the meeting in Cambridge joined the meeting remotely.
After a welcome cocktail reception on Monday evening at Hilton Cambridge City Centre, on Tuesday, the consortium made an early start with a recap of BiCIKL’s key milestones and outputs from the last three years. All Work Package leaders had their own timeslot to discuss the results of their collaborations.
They all agreed that the Biodiversity Knowledge Hub – the one-stop portal for understanding the complex – yet increasingly interconnected landscape of biodiversity research infrastructures – is likely the flagship outcome of BiCIKL.
Prof. Lyubomir Penev, project coordinator of BiCIKL and founder/CEO of Pensoft Publishers at the BiCIKL’s third and final General Assembly in Cambridge, United Kingdom.
In the afternoon, the participants focused on the services developed under BiCIKL. Amongst the many services resulting from the project some were not originally planned. Rather those were the ‘natural’ products of the dialogue and collaboration that flourished within the consortium throughout the project. “A symptom of passion,” said Prof. Lyubomir Penev, project coordinator of BiCIKL and founder/CEO of Pensoft Publishers.
An excellent example of one such service is what the partners call the “Biodiversity PMC”, which brings together biodiversity literature from thousands of scholarly journals and over 500,000 taxonomic treatments, in addition to the biomedical content available from NIH’s PubMed Central, into the SIB Literature Services (SIBiLS) database. What’s more, users at SIBiLS – be it human or AI – can now use advanced text- and data-mining tools, including AI-powered factoid question-answering capacities, to query all this full-text indexed content and seek out, for example, species traits and biotic interactions. Read more about the “Biodiversity PMC” in its recent official announcement.
Far from being the only one, the “Biodiversity PMC” is in good company: from the blockchain-based technology of LifeBlock to the curation of the DNA sequences by PlutoF, the BiCIKL project consortium takes pride in having developed twelve services dedicated to FAIR and linked ready-to-use biodiversity data.
On Wednesday, the consortium focused on BiCIKL’s activities from the Transnational and Virtual Access Pillar, which included both presentations by each open call leader and VA leader, as well as open discussions and a recap of what the teams have learnt from these experiences.
A panel discussion took place on Thursday as part of an open event, where BiCIKL partners and ELIXIR Biodiversity and Plant Communities came together to discuss the Future of Biodiversity and Genomics data integration at the EMBL Wellcome Genome Campus.
Thursday was dedicated to an open event where BiCIKL partners and ELIXIR Biodiversity and Plant Communities came together to discuss the Future of Biodiversity and Genomics data integration at the EMBL Wellcome Genome Campus. You can find the agenda on BiCIKL’s website.
After 36 months of action, the BiCIKL project will officially end in April 2024, but does it mean that all will be done and dusted come May 2024? Certainly not, point out the partners.
To ensure that the Biodiversity Knowledge Hub will not only continue to exist but will not cease to grow in both use and participation, the one-stop portal will remain under the maintenance of LifeWatch ERIC.
In conclusion, we could say that an appropriate payoff for the project is “Stick together!” as put by BiCIKL’s Joint Research Activity Leader Dr. Quentin Groom.
Final words at the third and last General Assembly of the BiCIKL project.
You can find highlights from the BiCIKL General Assembly meeting on X via the #BiCIKL_H2020 hashtag (in association with #Cambridge and #finalGA)
All research outputs, including the approved grant proposal, policy briefs, guidelines papers and research articles associated with the project, remain openly accessible from the BiCIKL project outcomes collection in RIO Journal: https://doi.org/10.3897/rio.coll.105.
Leading scholarly publisher Pensoft has announced a strategic collaboration with R Discovery, the AI-powered research discovery platform by Cactus Communications, a renowned science communications and technology company. This partnership aims to revolutionize the accessibility and discoverability of research articles published by Pensoft, making them more readily available on R Discovery to its over three million researchers across the globe.
R Discovery, acclaimed for its advanced algorithms and an extensive database boasting over 120 million scholarly articles, empowers researchers with intelligent search capabilities and personalized recommendations. Through its innovative Reading Feed feature, R Discovery delivers tailored suggestions in a format reminiscent of social media, identifying articles based on individual research interests. This not only saves time but also keeps researchers updated with the latest and most relevant studies in their field.
Open Science is much more than cost-free access to research output.
Lyubomir Penev
One of R Discovery’s standout features is its ability to provide paper summaries, audio readings, and language translation, enabling users to quickly assess a paper’s relevance and enhance their research reading experience significantly.
With over 2.5 million app downloads and upwards of 80 million journal articles featured, the R Discovery database is one of the largest scholarly content repositories.
“At Pensoft, we do realise that Open Science is much more than cost-free access to research outputs. It is also about easier discoverability and reusability, or, in other words, how likely it is for the reader to come across a particular scientific publication and, as a result, cite and build on those findings in his/her own studies. By feeding the content of our journals into R Discovery, we’re further facilitating the discoverability of the research done and shared by the authors who trust us with their work,” said ARPHA’s and Pensoft’s founder and CEO Prof. Lyubomir Penev.
Abhishek Goel, Co-Founder and CEO of Cactus Communications, commented on the collaboration, “We are delighted to work with Pensoft and offer researchers easy access to the publisher’s high-quality research articles on R Discovery. This is a milestone in our quest to support academia in advancing open science that can help researchers improve the world.”
So far, R Discovery has successfully established partnership with over 20 publishers, enhancing the platform’s extensive repository of scholarly content. By joining forces with R Discovery, Pensoft solidifies its dedication to making scholarly publications from its open-access, peer-reviewed journal portfolio easily discoverable and accessible.
Novel nanopublication workflows and templates for associations between organisms, taxa and their environment are the latest outcome of the collaboration between Knowledge Pixels and Pensoft.
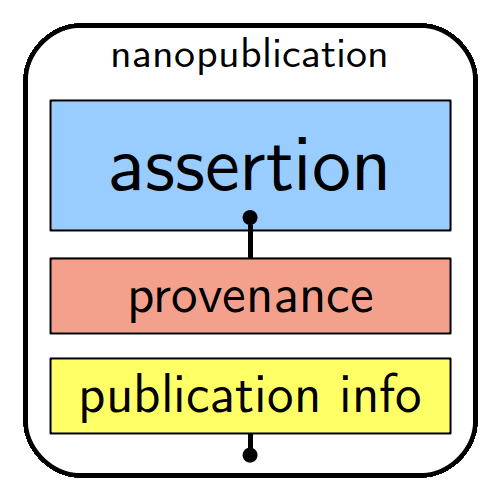
Nanopublications complement human-created narratives of scientific knowledge with elementary, machine-actionable, simple and straightforward scientific statements that prompt sharing, finding, accessibility, citability and interoperability.
By making it easier to trace individual findings back to their origin and/or follow-up updates, nanopublications also help to better understand the provenance of scientific data.
With the nanopublication format and workflow, authors make sure that key scientific statements – the ones underpinning their research work – are efficiently communicated in both human-readable and machine-actionable mannerin line with FAIR principles. Thus, their contributions to science are better prepared for a reality driven by AI technology.
The machine-actionability of nanopublications is a standard due to each assertion comprising a subject, an object and a predicate (type of relation between the subject and the object), complemented by provenance, authorship and publication information. A unique feature here is that each of the elements is linked to an online resource, such as a controlled vocabulary, ontology or standards.
Now, what’s new?
As a result of the partnership between high-tech startup Knowledge Pixels and open-access scholarly publisher and technology provider Pensoft, authors in Biodiversity Data Journal (BDJ) can make use of three types of nanopublications:
Nanopublications associated with a manuscript submitted to BDJ. This workflow lets authors add a Nanopublications section within their manuscript while preparing their submission in the ARPHA Writing Tool (AWT). Basically, authors ‘highlight’ and ‘export’ key points from their papers as nanopublications to further ensure the FAIRness of the most important findings from their publications.
Standalone nanopublication related to any scientific publication, regardless of its author or source. This can be done via the Nanopublications page accessible from the BDJ website. The main advantage of standalone nanopublication is that straightforward scientific statements become available and FAIR early on, and remain ready to be added to a future scholarly paper.
Nanopublications as annotations to existing scientific publications. This feature is available from several journals published on the ARPHA Platform, including BDJ. By attaching an annotation to the entire paper (via the Nanopublication tab) or a text selection (by first adding an inline comment, then exporting it as a nanopublication), a reader can evaluate and record an opinion about any article using a simple template based on the Citation Typing Ontology (CiTO).
Nanopublications for biodiversity data?
At Biodiversity Data Journal (BDJ), authors can now incorporate nanopublications within their manuscripts to future-proofthe most important assertions on biological taxa and organisms or statements about associations of taxa or organisms and their environments.
On top of being shared and archived by means of a traditional research publication in an open-access peer-reviewed journal, scientific statements using the nanopublication format will also remain ‘at the fingertips’ of automated tools that may be the next to come looking for this information, while mining the Web.
Using the nanopublication workflows and templates available at BDJ, biodiversity researchers can share assertions, such as:
So far, the available biodiversity nanopublication templates cover a range of associations, including those between taxa and individual organisms, as well as between those and their environments and nucleotide sequences.
Nanopublication template customised for biodiversity research publications available from Nanodash.
As a result, those easy-to-digest ‘pixels of knowledge’ can capture and disseminate information about single observations, as well as higher taxonomic ranks.
The novel domain-specific publication format was launched as part of thecollaboration betweenKnowledge Pixels – an innovative startup tech company aiming to revolutionise scientific publishing and knowledge sharing and the open-access scholarly publisherPensoft.
Basically, a nanopublication – unlike a research article – is a tiny snippet of a precise and structured scientific finding (e.g. medication X treats disease Y), which exists as a reusable and cite-able pieces of a growing knowledge graph stored on a decentralised server network in a format that it is readable for humans, but also “understandable” and actionable for computers and their algorithms.
These semantic statements expressed in community-agreed terms, openly available through links to controlled vocabularies, ontologies and standards, are not only freely accessible to everyone in both human-readable and machine-actionable formats, but also easy-to-digest for computer algorithms and AI-powered assistants.
In short, nanopublications allow us to browse and aggregate such findings as part of a complex scientific knowledge graph. Therefore, nanopublications bring us one step closer to the next revolution in scientific publishing, which started with the emergence and increasing adoption of knowledge graphs.
“As pioneers in the semantic open access scientific publishing field for over a decade now, we at Pensoft are deeply engaged with making research work actually available at anyone’s fingertips. What once started as breaking down paywalls to research articles and adding the right hyperlinks in the right places, is time to be built upon,”
By letting computer algorithms access published research findings in a structured format, nanopublications allow for the knowledge snippets that they are intended to communicate to be fully understandable and actionable. With nanopublications, each of those fragmentsof scientific information is interconnected and traceable back to its author(s) and scientific evidence.
A nanopublication is a tiny snippet of a precise and structured scientific finding (e.g. medication X treats disease Y), which exists within a growing knowledge graph stored on a decentralised server network in a format that it is readable for humans, but also “understandable” and actionable for computers and their algorithms. Illustration by Knowledge Pixels.
By building on shared knowledge representation models, these data become Interoperable (as in the Iin FAIR), so that they can be delivered to the right user, at the right time, in the right place , ready to be reused (as per the R in FAIR) in new contexts.
Another issue nanopublications are designed to address is research scrutiny. Today, scientific publications are produced at an unprecedented rate that is unlikely to cease in the years to come, as scholarship embraces the dissemination of early research outputs, including preprints, accepted manuscripts and non-conventional papers.
A network of interlinked nanopublications could also provide a valuable forum for scientists to test, compare, complement and build on each other’s results and approaches to a common scientific problem, while retaining the record of their cooperation each step along the way.
***
We encourage you to try the nanopublications workflow yourself when submitting your next biodiversity paper to Biodiversity Data Journal.
Community feedback on this pilot project and suggestions for additional biodiversity-related nanopublication templates are very welcome!
On the journal website: https://bdj.pensoft.net/, you can find more about the unique features and workflows provided by the Biodiversity Data Journal (BDJ), including innovative research paper formats (e.g. Data Paper, OMICS Data Paper, Software Description, R Package, Species Conservation Profiles, Alien Species Profile), expert-provided data audit for each data paper submission, automated data export and more.
Don’t forget to also sign up for the BDJ newsletter via the Email alert form on the journal’s homepage and follow it on Twitter and Facebook.
Earlier this year, Knowledge Pixels and Pensoft presented several routes for readers and researchers to contribute to research outputs – either produced by themselves or by others – through nanopublications generated through and visualised in Pensoft’s cross-disciplinary Research Ideas and Outcomes (RIO) journal, which uses the same nanopublication workflows.
For an eighth year in a row, all conference abstracts will be submitted to TDWG via the Association’s own journal: Biodiversity Information Science and Standards (BISS Journal), published by Pensoft and powered by the end-to-end publishing platform ARPHA. Using the ‘mini-paper’ format, participants are not only openly and efficiently sharing their work with the world, but they also get to enjoy many features typically exclusive to ‘standard’ research papers, including DOI registration on Crossref, semantic enrichment and structural elements (e.g., tables, figures), all of which are stored as easily exported data.
Apart from an abstract submission portal, BISS Journal also serves as a permanent, openly accessible scholarly source for all contributions concerning the creation, maintenance, and promotion of open community-driven data standards to enable sharing and use of biodiversity data for all.
As in previous years, the abstracts will be published ahead of the event itself to provide the community with a sneak preview of the conference. The 2023 collection of abstracts, will allow readers to explore the abstracts by session (e.g., symposia, posters, contributed presentations, keynotes). Sometime after the conference, check out the media tab on most abstracts for slides presented and a link to session video when it is posted on TDWG’s YouTube channel.
***
Visit the TDWG 2023 conference website for more information about the scientific program, registration, abstract submission and more. Ahead, during and after the conference, join the conversation on Twitter and Mastodon via #tdwg2023.
All journals published by Pensoft – each using the publisher’s self-developed ARPHA Platform – provide extensive and transparent information about their costs and services in line with the Plan S principles.
In support of transparency and openness in scholarly publishing and academia, the scientific publisher and technology provider Pensoft joined the Journal Comparison Service (JCS) initiative by cOAlition S, an alliance of national funders and charitable bodies working to increase the volume of free-to-read research.
As a result, all journals published by Pensoft – each using the publisher’s self-developed ARPHA Platform – provide extensive and transparent information about their costs and services in line with the Plan S principles.
The JCS was launched to aid libraries and library consortia – the ones negotiating and participating in Open Access agreements with publishers – by providing them with everything they need to know in order to determine whether the prices charged by a certain journal are fair and corresponding to the quality of the service.
According to cOAlition S, an increasing number of libraries and library consortia from Europe, Africa, North America, and Australia have registered with the JCS over the past year since the launch of the portal in September 2021.
While access to the JCS is only open to librarians, individual researchers may also make use of the data provided by the participating publishers and their journals.
This is possible through an integration with the Journal Checker Tool, where researchers can simply enter the name of the journal of interest, their funder and affiliation (if applicable) to check whether the scholarly outlet complies with the Open Access policy of the author’s funder. A full list of all academic titles that provide data to the JCS is also publicly available. By being on the list means a journal and its publisher do not only support cOAlition S, but they also demonstrate that they stand for openness and transparency in scholarly publishing.
“We are delighted that Pensoft, along with a number of other publishers, have shared their price and service data through the Journal Comparison Service. Not only are such publishers demonstrating their commitment to open business models and cultures but are also helping to build understanding and trust within the research community.”
said Robert Kiley, Head of Strategy at cOAlition S.
***
About cOAlition S:
On 4 September 2018, a group of national research funding organisations, with the support of the European Commission and the European Research Council (ERC), announced the launch of cOAlition S, an initiative to make full and immediate Open Access to research publications a reality. It is built around Plan S, which consists of one target and 10 principles. Read more on the cOAlition S website.
About Plan S:
Plan S is an initiative for Open Access publishing that was launched in September 2018. The plan is supported by cOAlition S, an international consortium of research funding and performing organisations. Plan S requires that, from 2021, scientific publications that result from research funded by public grants must be published in compliant Open Access journals or platforms. Read more on the cOAlition S website.
The FAIR Data Place – the key and final product of the partnership – is meant to provide scientists with all types of biodiversity data “at their fingertips”
The Horizon 2020 – funded project BiCIKL has reached its halfway stage and the partners gathered in Plovdiv (Bulgaria) from the 22nd to the 25th of October for the Second General Assembly, organised by Pensoft.
The BiCIKL project will launch a new European community of key research infrastructures, researchers, citizen scientists and other stakeholders in the biodiversity and life sciences based on open science practices through access to data, tools and services.
BiCIKL’s goal is to create a centralised place to connect all key biodiversity data by interlinking 15 research infrastructures and their databases. The 3-year European Commission-supported initiative kicked off in 2021 and involves 14 key natural history institutions from 10 European countries.
BiCIKL is keeping pace as expected with 16 out of the 48 final deliverables already submitted, another 9 currently in progress/under review and due in a few days. Meanwhile, 21 out of the 48 milestones have been successfully achieved.
Prof. Lyubomir Penev (BiCIKL’s project coordinator Prof. Lyubomir Penev and CEO and founder of Pensoft) opens the 2nd General Assembly of BiCIKL in Plovdiv, Bulgaria.
The hybrid format of the meeting enabled a wider range of participants, which resulted in robust discussions on the next steps of the project, such as the implementation of additional technical features of the FAIR Data Place (FAIR being an abbreviation for Findable, Accessible, Interoperable and Reusable).
This FAIR Data Place online platform – the key and final product of the partnership and the BiCIKL initiative – is meant to provide scientists with all types of biodiversity data “at their fingertips”.
This data includes biodiversity information, such as detailed images, DNA, physiology and past studies concerning a specific species and its ‘relatives’, to name a few. Currently, the issue is that all those types of biodiversity data have so far been scattered across various databases, which in turn have been missing meaningful and efficient interconnectedness.
Additionally, the FAIR Data Place, developed within the BiCIKL project, is to give researchers access to plenty of training modules to guide them through the different services.
Halfway through the duration of BiCIKL, the project is at a turning point, where crucial discussions between the partners are playing a central role in the refinement of the FAIR Data Place design. Most importantly, they are tasked with ensuring that their technologies work efficiently with each other, in order to seamlessly exchange, update and share the biodiversity data every one of them is collecting and taking care of.
By Year 3 of the BiCIKL project, the partners agree, when those infrastructures and databases become efficiently interconnected to each other, scientists studying the Earth’s biodiversity across the world will be in a much better position to build on existing research and improve the way and the pace at which nature is being explored and understood. At the end of the day, knowledge is the stepping stone for the preservation of biodiversity and humankind itself.
The Biodiversity Knowledge Hub is no longer existing on paper only! We are opening the 2nd day of the #BiCIKL_H2020 General Assembly looking at the prototype of the BKH created by the @LifeWatchERIC team. It's so exciting to see projects taking shape! 🤩 #Plovdivpic.twitter.com/RidzwBpxZx
“Needless to say, it’s an honour and a pleasure to be the coordinator of such an amazing team spanning as many as 14 partnering natural history and biodiversity research institutions from across Europe, but also involving many global long-year collaborators and their infrastructures, such as Wikidata, GBIF, TDWG, Catalogue of Life to name a few,”
said BiCIKL’s project coordinator Prof. Lyubomir Penev, CEO and founder of Pensoft.
“I see our meeting in Plovdiv as a practical demonstration of our eagerness and commitment to tackle the long-standing and technically complex challenge of breaking down the silos in the biodiversity data domain. It is time to start building freeways between all biodiversity data, across (digital) space, time and data types. After the last three days that we spent together in inspirational and productive discussions, I am as confident as ever that we are close to providing scientists with much more straightforward routes to not only generate more biodiversity data, but also build on the already existing knowledge to form new hypotheses and information ready to use by decision- and policy-makers. One cannot stress enough how important the role of biodiversity data is in preserving life on Earth. These data are indeed the groundwork for all that we know about the natural world”
Prof. Lyubomir Penev added.
Christos Arvanitidis (CEO of LifeWatch ERIC) at the 2nd General Assembly of the BiCIKL project.
“The point is: do we want an integrated structure or do we prefer federated structures? What are the pros and cons of the two options? It’s essential to keep the community united and allied because we can’t afford any information loss and the stakeholders should feel at home with the Project and the Biodiversity Knowledge Hub.”
Joe Miller, Executive Secretary and Director at GBIF, commented:
“We are a brand new community, and we are in the middle of the growth process. We would like to already have answers, but it’s good to have this kind of robust discussion to build on a good basis. We must find the best solution to have linkages between infrastructures and be able to maintain them in the future because the Biodiversity Knowledge Hub is the location to gather the community around best practices, data and guidelines on how to use the BiCIKL services… In order to engage even more partners to fill the eventual gaps in our knowledge.”
Joana Pauperio (biodiversity curator at EMBL-EBI) atthe 2nd General Assembly of the BiCIKL project.
“BiCIKL is leading data infrastructure communities through some exciting and important developments”
said Dr Guy Cochrane, Team Leader for Data Coordination and Archiving and Head of the European Nucleotide Archive at EMBL’s European Bioinformatics Institute (EMBL-EBI).
“In an era of biodiversity change and loss, leveraging scientific data fully will allow the world to catalogue what we have now, to track and understand how things are changing and to build the tools that we will use to conserve or remediate. The challenge is that the data come from many streams – molecular biology, taxonomy, natural history collections, biodiversity observation – that need to be connected and intersected to allow scientists and others to ask real questions about the data. In its first year, BiCIKL has made some key advances to rise to this challenge,”
“As a partner, we, at the Biodiversity Information Standards – TDWG, are very enthusiastic that our standards are implemented in BiCIKL and serve to link biodiversity data. We know that joining forces and working together is crucial to building efficient infrastructures and sharing knowledge.”
The project will go on with the first Round Table of experts in December and the publications of the projects who participated in the Open Call and will be founded at the beginning of the next year.
***
Learn more about BiCIKL on the project’s website at: bicikl-project.eu
For the 37th time, experts from across the world to share and discuss the latest developments surrounding biodiversity data and how they are being gathered, used, shared and integrated across time, space and disciplines.
Between 17th and 21st October, about 400 scientists and experts took part in a hybrid meeting dedicated to the development, use and maintenance of biodiversity data, technologies, and standards across the world.
For the 37th time, the global scientific and educational association Biodiversity Information Standards (TDWG) brought together experts from all over the globe to share and discuss the latest developments surrounding biodiversity data and how they are being gathered, used, shared and integrated across time, space and disciplines.
This was the first time the event happened in a hybrid format. It was attended by 160 people on-site, while another 235 people joined online.
The TDWG 2022 conference saw plenty of networking and engaging discussions with as many as 160 on-site attendees and another 235 people, who joined the event remotely.
“It’s wonderful to be in the Balkans and Bulgaria for our Biodiversity Information and Standards (TDWG) 2022 conference! Everyone’s been so welcoming and thoughtfully engaged in conversations about biodiversity information and how we can all collaborate, contribute and benefit,”
“Our TDWG mission is to create, maintain and promote the use of open, community-driven standards to enable sharing and use of biodiversity data for all,”
she added.
Prof Lyubomir Penev (Pensoft) and Deborah Paul (TDWG) at TDWG 2022.
“We are proud to have been selected to be the hosts of this year’s TDWG annual conference and are definitely happy to have joined and observed so many active experts network and share their know-how and future plans with each other, so that they can collaborate and make further progress in the way scientists and informaticians work with biodiversity information,”
said Pensoft’s founder and CEO Prof. Lyubomir Penev.
“As a publisher of multiple globally renowned scientific journals and books in the field of biodiversity and ecology, at Pensoft we assume it to be our responsibility to be amongst the first to implement those standards and good practices, and serve as an example in the scholarly publishing world. Let me remind you that it is the scientific publications that present the most reliable knowledge the world and science has, due to the scrutiny and rigour in the review process they undergo before seeing the light of day,”
he added.
***
In a nutshell, the main task and dedication of the TDWG association is to develop and maintain standards and data-sharing protocols that support the infrastructures (e.g., The Global Biodiversity Information Facility – GBIF), which aggregate and facilitate use of these data, in order to inform and expand humanity’s knowledge about life on Earth.
It is the goal of everyone at TDWG to let scientists interested in the world’s biodiversity to do their work efficiently and in a manner that can be understood, shared and reused.
It is the goal of everyone volunteering their time and expertise to TDWG to enable the scientists interested in the world’s biodiversity to do their work efficiently and in a manner that can be understood, shared and reused by others. After all, biodiversity data underlie everything we know about the natural world.
If there are optimised and universal standards in the way researchers store and disseminate biodiversity data, all those biodiversity scientists will be able to find, access and use the knowledge in their own work much more easily. As a result, they will be much better positioned to contribute new knowledge that will later be used in nature and ecosystem conservation by key decision-makers.
On Monday, the event opened with welcoming speeches by Deborah Paul and Prof. Lyubomir Penev in their roles of the Chair of TDWG and the main host of this year’s conference, respectively.
The opening ceremony continued with a keynote speech by Prof. Pavel Stoev, Director of the Natural History Museum of Sofia and co-host of TDWG 2022.
Prof. Pavel Stoev (Natural History Museum of Sofia) with a presentation about the known and unknown biodiversity of Bulgaria during the opening plenary session of TDWG 2022.
He walked the participants through the fascinating biodiversity of Bulgaria, but also the worrying trends in the country associated with declining taxonomic expertise.
He finished his talk with a beam of hope by sharing about the recently established national unit of DiSSCo, whose aim – even if a tad too optimistic – is to digitise one million natural history items in four years, of which 250,000 with photographs. So far, one year into the project, the Bulgarian team has managed to digitise more than 32,000 specimens and provide images to 10,000 specimens.
The plenary session concluded with a keynote presentation by renowned ichthyologist and biodiversity data manager Dr. Richard L. Pyle, who is also a manager of ZooBank – the key international database for newly described species.
Keynote presentation by Dr Richard L. Pyle (Bishop Museum, USA) at the opening plenary session of TDWG 2022.
In his talk, he highlighted the gaps in the ways taxonomy is being used, thereby impeding biodiversity research and cutting off a lot of opportunities for timely scientific progress.
“There are simple things we can do to change how we use taxonomy as a tool that would dramatically improve our ability to conduct science and understand biodiversity. There is enormous value and utility within existing databases around the world to understand biodiversity, how threatened it is, what impacts human activity has (especially climate change), and how to optimise the protection and preservation of biodiversity,”
he said in an interview for a joint interview by the Bulgarian News Agency and Pensoft.
“But we do not have easy access to much of this information because the different databases are not well integrated. Taxonomy offers us the best opportunity to connect this information together, to answer important questions about biodiversity that we have never been able to answer before. The reason meetings like this are so important is that they bring people together to discuss ways of using modern informatics to greatly increase the power of the data we already have, and prioritise how we fill the gaps in data that exist. Taxonomy, and especially taxonomic data integration, is a very important part of the solution.”
Pyle also commented on the work in progress at ZooBank ten years into the platform’s existence and its role in the next (fifth) edition of the International Code of Zoological Nomenclature, which is currently being developed by the International Commission of Zoological Nomenclature (ICZN).
“We already know that ZooBank will play a more important role in the next edition of the Code than it has for these past ten years, so this is exactly the right time to be planning new services for ZooBank. Improvements at ZooBank will include things like better user-interfaces on the web to make it easier and faster to use ZooBank, better data services to make it easier for publishers to add content to ZooBank as part of their publication workflow, additional information about nomenclature and taxonomy that will both support the next edition of the Code, and also help taxonomists get their jobs done more efficiently and effectively. Conferences like the TDWG one are critical for helping to define what the next version of ZooBank will look like, and what it will do.”
***
During the week, the conference participants had the opportunity to enjoy a total of 140 presentations; as well as multiple social activities, including a field trip to Rila Monastery and a traditional Bulgarian dinner.
TDWG 2022 conference participants document their species observations on their way to Rila Monastery.
While going about the conference venue and field trip localities, the attendees were also actively uploading their species observations made during their stay in Bulgaria on iNaturalist in a TDWG2022-dedicated BioBlitz. The challenge concluded with a total of 635 observations and 228 successfully identified species.
Amongst the social activities going on during TDWG 2022 was a BioBlitz, where the conference participants could uploade their observations made in Bulgaria on iNaturalist and help each other successfully identify the specimens.
“Biodiversity provides the support systems for all life on Earth. Yet the natural world is in peril, and we face biodiversity and climate emergencies. The consequences of these include accelerating extinction, increased risk from zoonotic disease, degradation of natural capital, loss of sustainable livelihoods in many of the poorest yet most biodiverse countries of the world, challenges with food security, water scarcity and natural disasters, and the associated challenges of mass migration and social conflicts.
Solutions to these problems can be found in the data associated with natural science collections. DiSSCo is a partnership of the institutions that digitise their collections to harness their potential. By bringing them together in a distributed, interoperable research infrastructure, we are making them physically and digitally open, accessible, and usable for all forms of research and innovation.
At present rates, digitising all of the UK collection – which holds more than 130 million specimens collected from across the globe and is being taken care of by over 90 institutions – is likely to take many decades, but new technologies like machine learning and computer vision are dramatically reducing the time it will take, and we are presently exploring how robotics can be applied to accelerate our work.”
In his turn, Dr Donat Agosti, CEO and Managing director at Plazi – a not-for-profit organisation supporting and promoting the development of persistent and openly accessible digital taxonomic literature – said:
“All the data about biodiversity is in our libraries, that include over 500 million pages, and everyday new publications are being added. No person can read all this, but machines allow us to mine this huge, very rich source of data. We do not know how many species we know, because we cannot analyse with all the scientists in this library, nor can we follow new publications. Thus, we do not have the best possible information to explore and protect our biological environment.”
Dr Donat Agosti demonstrating the importance of publishing biodiversity data in a structured and semantically enhanced format in one of his presentations at TDWG 2022.
***
At the closing plenary session, Gail Kampmeier – TDWG Executive member and one of the first zoologists to join TDWG in 1996 – joined via Zoom to walk the conference attendees through the 37-year history of the association, originally named the Taxonomic Databases Working Group, but later transformed to Biodiversity Information Standards, as it expanded its activities to the whole range of biodiversity data.
“While this presentation is about TDWG’s history as an organisation, its focus will be on the heart of TDWG: its people. We would like to show how the organisation has evolved in terms of gender balance, inclusivity actions, and our engagement to promote and enhance diversity at all levels. But more importantly, where do we—as a community—want to go in the future?”,
Then, in the final talk of the session, Deborah Paul took to the stage to present the progress and key achievements by the association from 2022.
🤩Year in review by @idbdeb at #TDWG2022: many wonderful achievements & even more in the works!🙌 E.g.✅Memorandum of Understanding with Genomic Standards Consortium ✅new Mineralogy Task Group ✅new vision & mission statement ✅collaboration with @GBIF on the new data model.. 1/ pic.twitter.com/RZx8hlePOm
Deborah Paul reminds that – apart from the conference abstracts – the TDWG journal: Biodiversity Information Science and Standards (BISS) also welcomes full-lenght articles that demonstrate the development or application of new methods and approaches in biodiversity informatics.
Launched in 2017 on the Pensoft’s publishing platform ARPHA, the journal provides the quite unique and innovative opportunity to have both abstracts and full-length research papers published in a modern, technologically-advanced scholarly journal. In her speech, Deborah Paul reminded that BISS journal welcomes research articles that demonstrate the development or application of new methods and approaches in biodiversity informatics in the form of case studies.
Amongst the achievements of TDWG and its community, a special place was reserved for the Horizon 2020-funded BiCIKL project (abbreviation for Biodiversity Community Integrated Knowledge Library), involving many of the association’s members.
Having started in 2021, the 3-year project, coordinated by Pensoft, brings together 14 partnering institutions from 10 countries, and 15 biodiversity under the common goal to create a centralised place to connect all key biodiversity data by interlinking a total of 15 research infrastructures and their databases.
Deborah Paul also reported on the progress of the Horizon 2020-funded project BiCIKL, which involves many of the TDWG members. BiCIKL’s goal is to create a centralised place to connect all key biodiversity data by interlinking 15 key research infrastructures and their databases.
In fact, following the week-long TDWG 2022 conference in Sofia, a good many of the participants set off straight for another Bulgarian city and another event hosted by Pensoft. The Second General Assembly of BiCIKL took place between 22nd and 24th October in Plovdiv.
***
You can also explore highlights and live tweets from TDWG 2022 on Twitter via #TDWG2022.
The Pensoft team at TDWG 2022 were happy to become the hosts of the 37th TDWG conference.
By the time authors – who have acknowledged third-party financial support in their research papers submitted to a journal using the Pensoft-developed publishing platform: ARPHA – open their inboxes to the congratulatory message that their work has just been published and made available to the wide world, a similar notification will have also reached their research funder.
This automated workflow is already in effect at all journals (co-)published by Pensoft and those published under their own imprint on the ARPHA Platform, as a result of the new partnership with the OA Switchboard: a community-driven initiative with the mission to serve as a central information exchange hub between stakeholders about open access publications, while making things simpler for everyone involved.
All the submitting author needs to do to ensure that their research funder receives a notification about the publication is to select the supporting agency or the scientific project (e.g. a project supported by Horizon Europe) in the manuscript submission form, using a handy drop-down menu. In either case, the message will be sent to the funding body as soon as the paper is published in the respective journal.
“At Pensoft, we are delighted to announce our integration with the OA Switchboard, as this workflow is yet another excellent practice in scholarly publishing that supports transparency in research. Needless to say, funding and financing are cornerstones in scientific work and scholarship, so it is equally important to ensure funding bodies are provided with full, prompt and convenient reports about their own input.”
comments Prof Lyubomir Penev, CEO and founder of Pensoft and ARPHA.
“Research funders are one of the three key stakeholder groups in OA Switchboard and are represented in our founding partners. They seek support in demonstrating the extent and impact of their research funding and delivering on their commitment to OA. It is great to see Pensoft has started their integration with OA Switchboard with a focus on this specific group, fulfilling an important need,”
adds Yvonne Campfens, Executive Director of the OA Switchboard.
***
About the OA Switchboard:
A global not-for-profit and independent intermediary established in 2020, the OA Switchboard provides a central hub for research funders, institutions and publishers to exchange OA-related publication-level information. Connecting parties and systems, and streamlining communication and the neutral exchange of metadata, the OA Switchboard provides direct, indirect and community benefits: simplicity and transparency, collaboration and interoperability, and efficiency and cost-effectiveness.
About Pensoft:
Pensoft is an independent academic publishing company, well known worldwide for its novel cutting-edge publishing tools, workflows and methods for text and data publishing of journals, books and conference materials.
All journals (co-)published by Pensoft are hosted on Pensoft’s full-featured ARPHA Publishing Platform and published in a way that ensures their content is as FAIR as possible, meaning that it is effortlessly readable, discoverable, harvestable, citable and reusable by both humans and machines.
From 17th to 21st October 2022, the Biodiversity Information Standards (TDWG) conference – to be held in Sofia – will run under the theme “Stronger Together: Standards for linking biodiversity data”.
Between 17th and 21st October 2022, the Biodiversity Information Standards (TDWG) conference – to be held in Sofia, Bulgaria – will run under the theme “Stronger Together: Standards for linking biodiversity data”.
In addition to opening and closing plenaries, the conference will feature 14 symposia and a mix of other formats that include lightning talks, a workshop, and panel discussion, and contributed oral presentations and virtual posters.
For a seventh year in a row, all abstracts submitted to the annual conference are made publicly available in the dedicated TDWG journal: Biodiversity Information Science and Standards (BISS Journal).
Thus, the abstracts – published ahead of the event itself – are not only permanently and freely available in a ‘mini-paper’ format, but will also provide conference participants with a sneak peek into what’s coming at the much anticipated conference.
TDWG 2021, the virtual conference of Biodiversity Information Standards (TDWG) being held 18–22 October, issued a call for abstracts representing presentations in fifteen symposia, as well as posters (including infographics), and contributed oral presentations appropriate to the conference theme Connecting the world of biodiversity data: uniting people, processes, and tools. Registration is now open, with the deadline for abstract submission set to 2 August 2021.
Joint blog post by #TDWG2021 Program Committee and Pensoft Editorial Team
TDWG 2021, the virtual conference of Biodiversity Information Standards (TDWG) being held 18–22 October, issued a call for abstracts representing presentations in fifteen symposia, as well as posters (including infographics), and contributed oral presentations appropriate to the conference theme Connecting the world of biodiversity data: uniting people, processes, and tools.Registration is now open, with the deadline for abstract submission set to 2 August 2021.
Detailed instructions have also been made available to guide authors through the process. Abstract publication costs are included in the conference registration. All presenters must be fully registered before their abstracts can be published.
Why are these not your typical conference abstracts?
In short, each published abstract is a mini-paper designed to entice conference participants to attend your presentation, but, even more importantly, to let you provide something more enduring, a snapshot of your research progress the size of a written elevator pitch.
Using Pensoft’s ARPHA writing tool, you can enhance your abstract, so that it includes figures, keywords, references, and supplementary materials. Slides, posters, and video links can also be added to the abstract’s media tab after the conference, to build a well-rounded understanding of your work. TDWG’s open access Pensoft journal, Biodiversity Information Science and Standards (BISS), will even provide metrics about views, downloads, citations, or even online mentions of your abstract.
Benefits of publishing your TDWG conference abstract:
Review provided by at least two editors for each abstract.
Readers can comment or ask questions within the Comment tab in the publication. Authors may also use the Comment tab for updates or errata.
Automatic linking of your abstract to your author record via ORCID and/or Web of Science (Publons) ResearcherID.
To prompt discoverability, all articles, including abstracts, are automatically harvested upon publication by a range of indexers, from AGRIS to ZDB.
Technical editors are cited as part of the article metadata.
Abstracts are associated with the conference session in which they were presented.
Easy to create buzz around your presentation by sharing your abstract on Twitter, Facebook, Mendeley, Reddit, or via email with a single click thanks to share buttons.
While BISSis currently known as (just) a place to publish conference proceedings, this is a misconception. Authors are encouraged to publish full articles of methods, standards, guidelines, case studies, software descriptions, forum papers, editorials, correspondence, data or software reviews. BISS provides a discount on the article processing charges (APCs) for TDWG members.
***
Join the conversation around this year’s Biodiversity Information Standards (TDWG) conference on Twitter via #TDWG2021.