From 1973 to 2020, Australian zoologist Dr Robert Mesibov kept careful records of the “where” and “when” of his plant and invertebrate collecting trips. Now, he has made those valuable biodiversity data freely and easily accessible via the Zenodo open-data repository, so that future researchers can rely on this “authority file” when using museum specimens collected from those events in their own studies. The new dataset is described in the open-access, peer-reviewed Biodiversity Data Journal.
While checking museum records, Dr Robert Mesibov found there were occasional errors in the dates and places for specimens he had collected many years before. He was not surprised.
“It’s easy to make mistakes when entering data on a computer from paper specimen labels”, said Mesibov. “I also found specimen records that said I was the collector, but I know I wasn’t!”
One solution to this problem was what librarians and others have long called an “authority file”.
“It’s an authoritative reference, in this case with the correct details of where I collected and when”, he explained.
“I kept records of almost all my collecting trips from 1973 until I retired from field work in 2020. The earliest records were on paper, but I began storing the key details in digital form in the 1990s.”
The 48-year record has now been made publicly available via the Zenodo open-data repository after conversion to the Darwin Core data format, which is widely used for sharing biodiversity information. With this “authority file”, described in detail in the open-access, peer-reviewed Biodiversity Data Journal, future researchers will be able to rely on sound, interoperable and easy to access data, when using those museum specimens in their own studies, instead of repeating and further spreading unintentional errors.
“There are 3829 collecting events in the authority file”, said Mesibov, “from six Australian states and territories. For each collecting event there are geospatial and date details, plus notes on the collection.”
Mesibov hopes the authority file will be used by museums to correct errors in their catalogues.
“It should also save museums a fair bit of work in future”, he explained. “No need to transcribe details on specimen labels into digital form in a database, because the details are already in digital form in the authority file.”
Mesibov points out that in the 19th and 20th centuries, lists of collecting events were often included in the reports of major scientific expeditions.
“Those lists were authority files, but in the pre-digital days it was probably just as easy to copy collection data from specimen labels.”
“In the 21st century there’s a big push to digitise museum specimen collections”, he said. “Museum databases often have lookup tables with scientific names and the names of collectors. These lookup tables save data entry time and help to avoid errors in digitising.”
“Authority files for collecting events are the next logical step,” said Mesibov. “They can be used as lookup tables for all the important details of individual collections: where, when, by whom and how.”
###
Research paper:
Mesibov RE (2021) An Australian collector’s authority file, 1973–2020. Biodiversity Data Journal 9: e70463. https://doi.org/10.3897/BDJ.9.e70463
Between now and 15 September 2021, the article processing fee (normally €550) will be waived for the first 36 papers, provided that the publications are accepted and meet the following criteria that the data paper describes a dataset:
The manuscript must be prepared in English and is submitted in accordance with BDJ’s instructions to authors by 15 September 2021. Late submissions will not be eligible for APC waivers.
Sponsorship is limited to the first 36 accepted submissions meeting these criteria on a first-come, first-served basis. The call for submissions can therefore close prior to the stated deadline of 15 September 2021. Authors may contribute to more than one manuscript, but artificial division of the logically uniform data and data stories, or “salami publishing”, is not allowed.
BDJ will publish a special issue including the selected papers by the end of 2021. The journal is indexed by Web of Science (Impact Factor 1.331), Scopus (CiteScore: 2.1) and listed in РИНЦ / eLibrary.ru.
For non-native speakers, please ensure that your English is checked either by native speakers or by professional English-language editors prior to submission. You may credit these individuals as a “Contributor” through the AWT interface. Contributors are not listed as co-authors but can help you improve your manuscripts.
In addition to the BDJ instruction to authors, it is required that datasets referenced from the data paper a) cite the dataset’s DOI, b) appear in the paper’s list of references, and c) has “Russia 2021” in Project Data: Title and “N-Eurasia-Russia2021“ in Project Data: Identifier in the dataset’s metadata.
Questions may be directed either to Dmitry Schigel, GBIF scientific officer, or Yasen Mutafchiev, managing editor of Biodiversity Data Journal.
The 2021 extension of the collection of data papers will be edited by Vladimir Blagoderov, Pedro Cardoso, Ivan Chadin, Nina Filippova, Alexander Sennikov, Alexey Seregin, and Dmitry Schigel.
Datasets with more than 5,000 records that are new to GBIF.org
Datasets should contain at a minimum 5,000 new records that are new to GBIF.org. While the focus is on additional records for the region, records already published in GBIF may meet the criteria of ‘new’ if they are substantially improved, particularly through the addition of georeferenced locations.” Artificial reduction of records from otherwise uniform datasets to the necessary minimum (“salami publishing”) is discouraged and may result in rejection of the manuscript. New submissions describing updates of datasets, already presented in earlier published data papers will not be sponsored.
Justification for publishing datasets with fewer records (e.g. sampling-event datasets, sequence-based data, checklists with endemics etc.) will be considered on a case-by-case basis.
Datasets with high-quality data and metadata
Authors should start by publishing a dataset comprised of data and metadata that meets GBIF’s stated data quality requirement. This effort will involve work on an installation of the GBIF Integrated Publishing Toolkit.
Only when the dataset is prepared should authors then turn to working on the manuscript text. The extended metadata you enter in the IPT while describing your dataset can be converted into manuscript with a single-click of a button in the ARPHA Writing Tool (see also Creation and Publication of Data Papers from Ecological Metadata Language (EML) Metadata. Authors can then complete, edit and submit manuscripts to BDJ for review.
Datasets with geographic coverage in Russia
In correspondence with the funding priorities of this programme, at least 80% of the records in a dataset should have coordinates that fall within the priority area of Russia. However, authors of the paper may be affiliated with institutions anywhere in the world.
***
Check out the Biota of Russia dynamic data paper collection so far.
Follow Biodiversity Data Journal on Twitter and Facebook to keep yourself posted about the new research published.
by Mariya Dimitrova, Jorrit Poelen, Georgi Zhelezov, Teodor Georgiev, Lyubomir Penev
Fig. 1. Pensoft-GloBI workflow for indexing biotic interactions from scholarly literature
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species, etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 2 in Fig. 1).. We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as json to a GitHub repository, from where they could be accessed by GloBI.
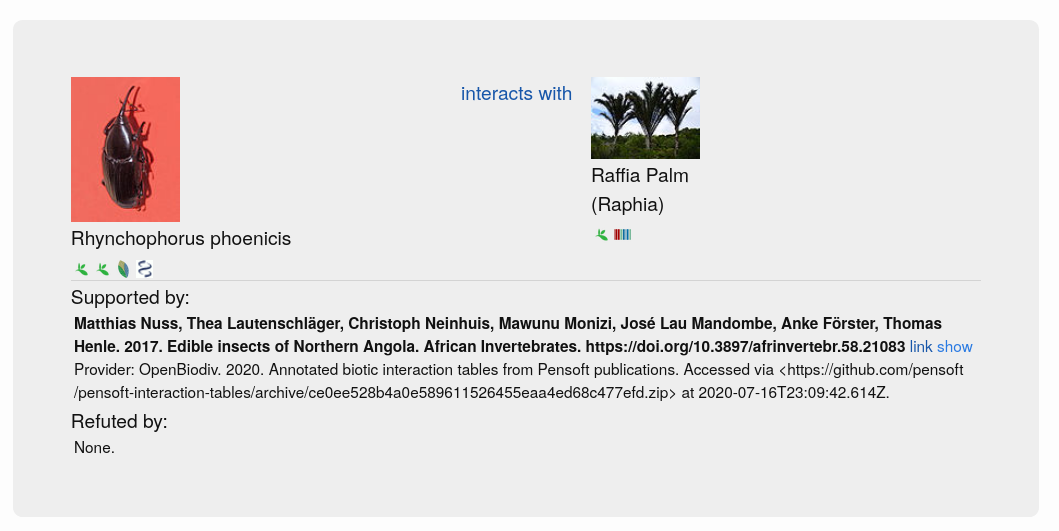
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ (Fig. 2) because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
Fig. 2. Example of a biotic interaction indexed by GloBI.
Examples of species interactions provided by OpenBiodiv and indexed by GloBI are available on GloBI’s website.
In the future we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6,993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 1 in Fig. 1). We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as JSON to a GitHub repository, from where they could be accessed by GloBI.
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
In the future, we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
References
Jorrit H. Poelen, James D. Simons and Chris J. Mungall. (2014). Global Biotic Interactions: An open infrastructure to share and analyze species-interaction datasets. Ecological Informatics. https://doi.org/10.1016/j.ecoinf.2014.08.005.
Additional Information
The work has been partially supported by the International Training Network (ITN) IGNITE funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 764840.
Looking at today’s ravaging COVID-19 (Coronavirus) pandemic, which, at the time of writing, has spread to over 220 countries; its continuously rising death toll and widespread fear, on the outside, it may feel like scientists and decision-makers are scratching their heads more than ever in the face of the unknown. In reality, however, we get to witness an unprecedented global community gradually waking up to the realisation of the only possible solution: collaboration.
On one hand, we have nationwide collective actions, including cancelled travel plans and mass gatherings; social distancing; and lockdowns, that have already proved successful at changing what the World Health Organisation (WHO) has determined as “the course of a rapidly escalating and deadly epidemic” in Hong Kong, Singapore and China. On the other hand, we have the world’s best scientists and laboratories all steering their expertise and resources towards the better understanding of the virus and, ultimately, developing a vaccine for mass production as quickly as possible.
While there is little doubt that the best specialists in the world will eventually invent an efficient vaccine – just like they did following the Western African Ebola virus epidemic (2013–2016) and on several other similar occasions in the years before – the question at hand is rather when this is going to happen and how many human lives it is going to cost?
Again, it all comes down to collective efforts. It only makes sense that if research teams and labs around the globe join their efforts and expertise, thereby avoiding duplicate work, their endeavours will bear fruit sooner rather than later. Similarly to employees from across the world, who have been demonstrating their ability to perform their day-to-day tasks and responsibilities from the safety of their homes just as efficiently as they would have done from their conventional offices, in today’s high-tech, online-friendly reality, no more should scientists be restricted by physical and geographical barriers either.
“Observations, prevention and impact of COVID-19”: Special Collection in RIO Journal
To inspire and facilitate collaboration across the world, the SPARC-recognised Open Science innovator Research Ideas and Outcomes(RIO Journal) decided to bring together scientific findings in an easy to discover, read, cite and build on collection of publications.
Furthermore, due to its revolutionary approach to publishing, where early and brief research outcomes (i.e. ideas, raw data, software descriptions, posters, presentations, case studies and many others) are all considered as precious scientific gems, hence deserving a formal publication in a renowned academic journal, RIO places a special focus on these contributions.
Accepted manuscripts that shall deal with research relevant to the COVID-19 pandemic across disciplines, including medicine, ethics, politics, economics etc. at a local, regional, national or international scale; and also meant to encourage crucial discussions, will be published free of charge in recognition of the emergency of the current situation. Especially encouraged are submissions focused on the long-term effects of COVID-19.
We invite early #research outcomes for the free-to-publish special collection "Observations, prevention and impact of #COVID19". ❗️It's high time we prove #OpenScience is what has the power to end the #Coronavirus pandemic sooner rather than later.
Furthermore, thanks to the technologically advanced infrastructure and services it provides, in addition to a long list of indexers and databases where publications are registered, the manuscripts submitted to RIO Journal are not only rapidly processed and published, but once they get online, they immediately become easy to discover, cite and built on by any researcher, anywhere in the world.
On top of that, Pensoft’s targeted and manually provided science communication services make sure that published research of social value reaches the wider audience, including key decision-makers and journalists, by means of press releases and social media promotion.
***
More info about RIO’s globally unique features, visit the journal’s website. Follow RIO Journal on Twitter and Facebook.
Between now and 31 August 2020, the article processing fee (normally €450) will be waived for the first 20 papers, provided that the publications are accepted and meet the following criteria that the data paper describes a dataset:
The manuscript must be prepared in English and is submitted in accordance with BDJ’s instructions to authors by 31 August 2020. Late submissions will not be eligible for APC waivers.
Sponsorship is limited to the first 20 accepted submissions meeting these criteria on a first-come, first-served basis. The call for submissions can therefore close prior to the stated deadline of 31 August. Authors may contribute to more than one manuscript, but artificial division of the logically uniform data and data stories, or “salami publishing”, is not allowed.
BDJ will publish a special issue including the selected papers by the end of 2020. The journal is indexed by Web of Science (Impact Factor 1.029), Scopus (CiteScore: 1.24) and listed in РИНЦ / eLibrary.ru
For non-native speakers, please ensure that your English is checked either by native speakers or by professional English-language editors prior to submission. You may credit these individuals as a “Contributor” through the AWT interface. Contributors are not listed as co-authors but can help you improve your manuscripts.
In addition to the BDJ instruction to authors, it is required that datasets referenced from the data paper a) cite the dataset’s DOI and b) appear in the paper’s list of references.
Questions may be directed either to Dmitry Schigel, GBIF scientific officer, or Yasen Mutafchiev, managing editor of Biodiversity Data Journal.
Definition of terms
Datasets with more than 5,000 records that are new to GBIF.org
Datasets should contain at a minimum 5,000 new records that are new to GBIF.org. While the focus is on additional records for the region, records already published in GBIF may meet the criteria of ‘new’ if they are substantially improved, particularly through the addition of georeferenced locations.
Justification for publishing datasets with fewer records (e.g. sampling-event datasets, sequence-based data, checklists with endemics etc.) will be considered on a case-by-case basis.
Datasets with high-quality data and metadata
Authors should start by publishing a dataset comprised of data and metadata that meets GBIF’s stated data quality requirement. This effort will involve work on an installation of the GBIF Integrated Publishing Toolkit.
Only when the dataset is prepared should authors then turn to working on the manuscript text. The extended metadata you enter in the IPT while describing your dataset can be converted into manuscript with a single-click of a button in the ARPHA Writing Tool (see also Creation and Publication of Data Papers from Ecological Metadata Language (EML) Metadata. Authors can then complete, edit and submit manuscripts to BDJ for review.
Datasets with geographic coverage in European Russia west of the Ural mountains
In correspondence with the funding priorities of this programme, at least 80% of the records in a dataset should have coordinates that fall within the priority area of European Russia west of the Ural mountains. However, authors of the paper may be affiliated with institutions anywhere in the world.
#####
Data audit at Pensoft’s biodiversity journals
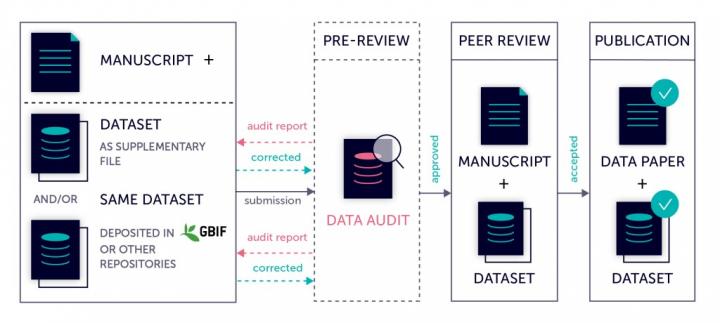
Data papers submitted to Biodiversity Data Journal, as well as all relevant biodiversity-themed journals in Pensoft’s portfolio, undergo a mandatory data auditing workflow before being passed down to a subject editor.
Data audit workflow provided for data papers submitted to Pensoft journals.
To avoid publication of openly accessible, yet unusable datasets, fated to result in irreproducible and inoperable biological diversity research at some point down the road, Pensoft takes care for auditing data described in data paper manuscripts upon their submission to applicable journals in the publisher’s portfolio, including Biodiversity Data Journal, ZooKeys, PhytoKeys, MycoKeys and many others.
Once the dataset is clean and the paper is published, biodiversity data, such as taxa, occurrence records, observations, specimens and related information, become FAIR (findable, accessible, interoperable and reusable), so that they can be merged, reformatted and incorporated into novel and visionary projects, regardless of whether they are accessed by a human researcher or a data-mining computation.
As part of the pre-review technical evaluation of a data paper submitted to a Pensoft journal, the associated datasets are subjected to data audit meant to identify any issues that could make the data inoperable. This check is conducted regardless of whether the dataset are provided as supplementary material within the data paper manuscript or linked from the Global Biodiversity Information Facility (GBIF) or another external repository. The features that undergo the audit can be found in a data quality checklist made available from the website of each journal alongside key recommendations for submitting authors.
Once the check is complete, the submitting author receives an audit report providing improvement recommendations, similarly to the commentaries he/she would receive following the peer review stage of the data paper. In case there are major issues with the dataset, the data paper can be rejected prior to assignment to a subject editor, but resubmitted after the necessary corrections are applied. At this step, authors who have already published their data via an external repository are also reminded to correct those accordingly.
“It all started back in 2010, when we joined forces with GBIF on a quite advanced idea in the domain of biodiversity: a data paper workflow as a means to recognise both the scientific value of rich metadata and the efforts of the the data collectors and curators. Together we figured that those data could be published most efficiently as citable academic papers,” says Pensoft’s founder and Managing director Prof. Lyubomir Penev.
“From there, with the kind help and support of Dr Robert Mesibov, the concept evolved into a data audit workflow, meant to ‘proofread’ the data in those data papers the way a copy editor would go through the text,” he adds.
“The data auditing we do is not a check on whether a scientific name is properly spelled, or a bibliographic reference is correct, or a locality has the correct latitude and longitude”, explains Dr Mesibov. “Instead, we aim to ensure that there are no broken or duplicated records, disagreements between fields, misuses of the Darwin Corerecommendations, or any of the many technical issues, such as character encoding errors, that can be an obstacle to data processing.”
At Pensoft, the publication of openly accessible, easy to access, find, re-use and archive data is seen as a crucial responsibility of researchers aiming to deliver high-quality and viable scientific output intended to stand the test of time and serve the public good.
The Lyell Project team: First row, seated from left to right: Martha Richter (Principal Curator in Charge of Vertebrates), Consuelo Sendino (with white coat, curator of bryozoans holding a Lyell fossil gastropod from Canaries), Noel Morris (Scientific Associate of Invertebrates), Claire Mellish (Senior Curator of arthropods), Sandra Chapman (curator of reptiles) and Emma Bernard (curator of fishes, holding the lectotype of Cephalaspis lyelli). Second row, standing on from left to right: Jill Darrell (curator of cnidarians), Zoe Hughes (curator of brachiopods) and Kevin Webb (science photographer). Photo by Nelly Perez-Larvor.
Curator of plants Peta Hayes (left) and curator of bryozoans Consuelo Sendino (right) looking at a Lyell fossil plant from Madeira in the collection area. Photo by Mark Lewis.
The records contain the data from the specimens’ labels (species name, geographical details, geological age and collection details), alongside high-resolution photographs, most of which were ‘stacked’ with the help of specialised software to re-create a 3D model.
Sir Charles Lyell’s fossil collection comprises a total of 1,735 specimens of fossil molluscs, filter-feeding moss animals and fish, as well as 51 more recent shells, including nine specimens originally collected by Charles Darwin from Tierra del Fuego or Galapagos, and later gifted to the geologist. The first specimen of the collection was deposited in distant 1846 by Charles Lyell himself, while the last one – in 1980 by one of his heirs.
With as much as 95% of the specimens having been found at the Macaronesian archipelagos of the Canaries and Madeira and dating to the Cenozoic era, the collection provides a key insight into the volcano formation and palaeontology of Macaronesia and the North Atlantic Ocean. By digitising the collection and making it easy to find and access for researchers from around the globe, the database is to serve as a stepping stone for studies in taxonomy, stratigraphy and volcanology at once.
Sites where the Earth Sciences’ Lyell Collection specimens originate.
“The display of this data virtually eliminates the need for specimen handling by researchers and will greatly speed up response time to collection enquiries,” explains Dr Sendino.
Furthermore, the pilot project and its workflow provide an invaluable example to future digitisation initiatives. In her data paper, Dr Sendino lists the limited resources she needed to complete the task in just over a year.
In terms of staff, the curator was joined by MSc student Teresa Máñez (University of Valencia, Spain) for six weeks while locating the specimens and collecting all the information about them; volunteer Jane Barnbrook, who re-boxed 1,500 specimens working one day per week for a year; NHM’s science photographer Kevin Webb and University of Lisbon’s researcher Carlos Góis-Marques, who imaged the specimens; and a research associate, who provided broad identification of the specimens, working one day per week for two months. Each of the curators for the collections, where the Lyell specimens were kept, helped Dr Sendino for less than a day. On the other hand, the additional costs comprised consumables such as plastazote, acid-free trays, archival pens, and archival paper for new labels.
“The success of this was due to advanced planning and resource tracking,” comments Dr Sendino.
“This is a good example of reduced cost for digitisation infrastructure creation maintaining a high public profile for digitisation,” she concludes.
###
Original source:
Sendino C (2019) The Lyell Collection at the Earth Sciences Department, Natural History Museum, London (UK). Biodiversity Data Journal 7: e33504. https://doi.org/10.3897/BDJ.7.e33504
###
About NHM Data Portal:
Committed to open access and open science, the Natural History Museum (London, UK) has launched the Data Portal to make its research and collections datasets available online. It allows anyone to explore, download and reuse the data for their own research.
The portal’s main dataset consists of specimens from the Museum’s collection database, with 4,224,171 records from the Museum’s Palaeontology, Mineralogy, Botany, Entomology and Zoology collections.
Plazi has received a grant of EUR 1.1 million from Arcadia – the charitable fund of Lisbet Rausing and Peter Baldwin – to liberate data, such as taxonomic treatments and images, trapped in scholarly biodiversity publications.
The project will expand the existing corpus of the Biodiversity Literature Repository (BLR), a joint venture of Plazi and Pensoft, hosted on Zenodo at CERN. The project aims to add hundreds of thousands of figures and taxonomic treatments extracted from publications, and further develop and hone the tools to search through the corpus.
The BLR is an open science community platform to make the data contained in scholarly publications findable, accessible, interoperable and reusable (FAIR). BLR is hosted on Zenodo, the open science repository at CERN, and maintained by the Switzerland-based Plazi association and the open access publisher Pensoft.
In its short existence, BLR has already grown to a considerate size: 35,000+ articles have been added, and extracted from 600+ journals. From these articles, more than 180,000 images have also been extracted and uploaded to BLR, and 225,000+ sub-article components, including biological names, taxonomic treatments or equivalent defined blocks of text have been deposited at Plazi’s TreatmentBank. Additionally, over a million bibliographic references have been extracted and added to Refbank.
The articles, images and all other sub-article elements are fully FAIR compliant and citable. In case an article is behind a paywall, a user can still access its underlying metadata, the link to the original article, and use the DOI assigned to it by BLR for persistent citation.
“Generally speaking, scientific illustrations and taxonomic treatments, such as species descriptions, are one of the best kept ‘secrets’ in science as they are neither indexed, nor are they citable or accessible. At best, they are implicitly referenced,” said Donat Agosti, president of Plazi. “Meanwhile, their value is undisputed, as shown by the huge effort to create them in standard, comparative ways. From day one, our project has been an eye-opener and a catalyst for the open science scene,” he concluded.
Though the target scientific domain is biodiversity, the Plazi workflow and tools are open source and can be applied to other domains – being a catalyst is one of the project’s goals.
While access to biodiversity images has already proven useful to scientists, but also inspirational to artists, for example, the people behind Plazi are certain that such a well-documented, machine-readable interface is sure to lead to many more innovative uses.
To promote BLR’s approach to make these important data accessible, Plazi seeks collaborations with the community and publishers, to remove hurdles in liberating the data contained in scholarly publications and make them FAIR.
The robust legal aspects of the project are a core basis of BLR’s operation. By extracting the non-copyrightable elements from the publications and making them findable, accessible and re-usable for free, the initiative drives the move beyond the PDF and HTML formats to structured data.
###
To participate in the project or for further questions, please contact Donat Agosti, President at Plazi at info@plazi.org
Additional information:
About Plazi:
Plazi is an association supporting and promoting the development of persistent and openly accessible digital taxonomic literature. To this end, Plazi maintains TreatmentBank, a digital taxonomic literature repository to enable archiving of taxonomic treatments; develops and maintains TaxPub, an extension of the National Library of Medicine / National Center for Biotechnology Informatics Journal Article Tag Suite for taxonomic treatments; is co-founder of the Biodiversity Literature Repository at Zenodo, participates in the development of new models for publishing taxonomic treatments in order to maximize interoperability with other relevant cyberinfrastructure components such as name servers and biodiversity resources; and advocates and educates about the vital importance of maintaining free and open access to scientific discourse and data. Plazi is a major contributor to the Global Biodiversity Information Facility.
About Arcadia Fund:
Arcadia is a charitable fund of Lisbet Rausing and Peter Baldwin. It supports charities and scholarly institutions that preserve cultural heritage and the environment. Arcadia also supports projects that promote open access and all of its awards are granted on the condition that any materials produced are made available for free online. Since 2002, Arcadia has awarded more than $500 million to projects around the world.
While not every taxonomic study is conducted with a nature conservation idea in mind, most ecological initiatives need to be backed by exhaustive taxonomic research. There simply isn’t a way to assess a species’ distributional range, migratory patterns or ecological trends without knowing what this species actually is and where it is coming from.
In order to facilitate taxonomic and other studies, and lay the foundations for effective biodiversity conservation in a time where habitat loss and species extinction are already part of our everyday life, the global organisation Catalogue of Life (CoL) works together with major programmes, including GBIF, Encyclopedia of Life and the IUCN Red List, to collate the names of all species on the planet set in the context of a taxonomic hierarchy and their distribution.
Recently, the scholarly publisher and technological provider Pensoft has implemented a new integration with CoL, so that it joins in the effort to encourage authors publishing global taxonomic review in any of the publisher’s journals to upload their taxonomic contributions to the database.
Whenever authors submit a manuscript containing a world revision or checklist of a taxon to a Pensoft journal, they are offered the possibility to upload their datasets in CoL-compliant format, so that they can contribute to CoL, gain more visibility and credit for their work, and support future research and conservation initiatives.
Once the authors upload the dataset, Pensoft will automatically notify CoL about the new contribution, so that the organisation can further process the knowledge and contact the authors, if necessary.
In addition, CoL will also consider for indexing global taxonomic checklists, which have already been published by Pensoft.
It is noteworthy to mention that unlike an automated search engine, CoL does not simply gather the uploaded data and store them. All databases in CoL are thoroughly reviewed by experts in the relevant field and comply with a set of explicit instructions.
“Needless to say that the Species 2000 / Catalogue of Life community is very happy with this collaboration,” says Dr. Peter Schalk, Executive Secretary.
“It is essential that all kinds of data and information sharing initiatives in the realm of taxonomy and biodiversity science get connected, in order to provide integrated quality services to the users in and outside of our community. The players in this field carry responsibility to forge partnerships and collaborations that create added value for science and society and are mutually reinforcing for the participants. Our collaboration is a fine example how this can be achieved,” he adds.
“With our extensive experience in biodiversity research, at Pensoft we have already taken various steps to encourage and support data sharing practices,” says Prof. Lyubomir Penev, Pensoft’s founder and CEO. To better serve this purpose, last year, we even published a set of guidelines and strategies for scholarly publishing of biodiversity data as recommended by our own experience. Furthermore, at our Biodiversity Data Journal, we have not only made the publication of open data mandatory, but we were also the first to implement integrated narrative and data publication within a single paper.”
“It only makes sense to collaborate with organisations, such as Catalogue of Life, to make sure that all these global indexers are up-to-date and serve the world’s good in preserving our wonderful biodiversity,” he concludes.
In order to encourage and facilitate high-quality data publication, the collaboration allows for researchers to easily store, analyse and manage their data via BEXIS 2, before sharing it with the scientific community in a creditable format.
The newly implemented workflow requires researchers to first download their data from the free open source BEXIS 2 software and, then, upload the data pack on Pensoft’s ARPHA Journal Publishing Platform where the data can be further elaborated to comply to the established Data Paper standards. Within the software, they can work freely on these data.
Having selected a journal and a data paper article template, a single click at an ‘Import a manuscript’ button transfers the data into a manuscript in ARPHA Authoring Tool. Within the collaborative writing tool, the data owner can invite co-authors and peers to help him/her finalise the paper.
Once submitted to a journal, the article undergoes a peer review and data auditing and, if accepted for publication, is published to take advantage of all perks available at any Pensoft journal, including easy discoverability and increased citability.
“I am delighted to have this new partnership between Pensoft and BEXIS 2 announced,” says Pensoft’s founder and CEO Prof. Lyubomir Penev.
“I believe that workflows like ours do inspire scientists to, firstly, refine their data to the best possible quality, and, secondly, make them available to the world, so that these data can benefit the society much faster and more efficiently through collaborative efforts and constructive feedback.”
“With scientists becoming more and more eager to publish research data in data journals like Pensoft’s BDJ, it is important to provide comprehensive and easy workflows for the transition of data from a data management platform like BEXIS 2 to the repository of the data journal without losing or re-entering any information. So we are absolutely delighted that a first version of such data publication workflow is now available to users of BEXIS 2.” says Prof. Birgitta König-Ries, Principle Investigator of BEXIS 2.
The collaboration between Pensoft and BEXIS 2 is set to strengthen in the next few months, when a new import workflow is expected to provide an alternative way to publish datasets.
BEXIS 2 is a free and open source software supporting researchers in managing their data throughout the entire data lifecycle from data collection, documentation, processing, analyzing, to sharing and publishing research data.
BEXIS 2 is a modular scalable platform suitable for working groups and collaborative project consortia with up to several hundred researchers. It has been designed to meet the requirements of researchers in the field of biodiversity, but it is generic enough to serve other communities as well.
BEXIS 2 is developed at Friedrich-Schiller-University Jena together with partners from Max-Planck Institute of Biogeochemistry Jena, Technical University Munich and GWDG Göttingen. The development is funded by the German Science Foundation (DFG).