The first national symposium on DNA barcoding took place on 5 December 2025 at the Headquarters of the Bulgarian Academy of Sciences, where it was attended by renowned Bulgarian scientists in the field, in addition to early-career researchers and PhD students representing different institutions.
The event saw a day-long series of lectures and a poster session, during which the participants had the opportunity to get acquainted with the work of their colleagues in various fields of biology.
Amongst the topics were the development of the Bulgarian molecular laboratory in Antarctica; the study of the invertebrate fauna currently underrepresented in DNA reference libraries; the return of the beaver to Bulgaria; and research on phytopathogenic fungi on agricultural crops.
During the coffee breaks sponsored by the National Museum of Natural History, the delegates had the chance to network and exchange experience between institutions and fields of expertise.
Teodor Georgiev, CTO at Pensoft held a presentation about the 2.0 version of the ARPHA Writing Tool. In its greatly improved version, it will feature many new, refined and elaborated workflows that help and simplify data publishing, discoverability, reusability and overall FAIRness.
🗨️Imagine if ALL these links were provided as hyperlinks within a #scholarly publication!
The event was opened and closed by Prof. Dr. Lyubomir Penev, who was elected as the Chair of the Governing Board at the Bulgarian Barcode of Life last year. He is also the founder and CEO of Pensoft.
In his closing speech, Penev expressed his hopes for the development of BgBOL and confirmed the plans of the consortium to turn the symposium into an annual tradition. Congratulations were extended to BgBOL’s newest member: the Institute of Oceanology “Fridtjof Nansen” at BAS.
He also announced the launch of a new special collection in the Biodiversity Data Journal, which will welcome scientific papers related to the Bulgarian and Balkan biota and using DNA barcoding methods. The authors of the first five papers to be submitted and accepted at the collection will take advantage of free publication.
Finally, he thanked the hosts of the Bulgarian Academy of Sciences Headquarters: Stefania Kamenova and Assoc. Prof. Dr. Georgi Bonchev, who are also Vice-Chair and Chair of the Executive Board at BgBOL, respectively. A special thanks went also to Prof. Pavel Stoev, Director of the National Museum of Natural History.
The beetle species Grebennikovius basilewskyi. Numbers next to arrows indicate patterns of phenotype statements explained in the section “Phenoscript: main patterns of phenotype statements”. Arrow numbers from T1 to T5 illustrate individual body parts. See more in the research study.
One of the most beautiful aspects of Nature is the endless variety of shapes, colours and behaviours exhibited by organisms. These traits help organisms survive and find mates, like how a male peacock’s colourful tail attracts females or his wings allow him to fly away from danger. Understanding traits is crucial for biologists, who study them to learn how organisms evolve and adapt to different environments.
To do this, scientists first need to describe these traits in words, like saying a peacock’s tail is “vibrant, iridescent, and ornate”. This approach works for small studies, but when looking at hundreds or even millions of different animals or plants, it’s impossible for the human brain to keep track of everything.
Computers could help, but not even the latest AI technology is able to grasp human language to the extent needed by biologists. This hampers research significantly because, although scientists can handle large volumes of DNA data, linking this information to physical traits is still very difficult.
To solve this problem, researchers from the Finnish Museum of Natural History, Giulio Montanaro and Sergei Tarasov, along with collaborators, have created a special language called Phenoscript. This language is designed to describe traits in a way that both humans and computers can understand. Describing traits with Phenoscript is like programming a computer code for how an organism looks.
Phenoscript uses something called semantic technology, which helps computers understand the meaning behind words, much like how modern search engines know the difference between the fruit “apple” and the tech company “Apple” based on the context of your search.
“This language is still being tested, but it shows a lot of promise. As more scientists start using Phenoscript, it will revolutionise biology by making vast amounts of trait data available for large-scale studies, boosting the emerging field of phenomics,”
explains Montanaro.
In their research article, newly published in the open-access, peer-reviewed Biodiversity Data Journal, the researchers make use of the new language for the first time, as they create semantic phenotypes for four species of dung beetles from the genus Grebennikovius. Then, to demonstrate the power of the semantic approach, they apply simple semantic queries to the generated phenotypic descriptions.
Finally, the team takes a look yet further ahead into modernising the way scientists work with species information. Their next aim is to integrate semantic species descriptions with the concept of nanopublications, “which encapsulates discrete pieces of information into a comprehensive knowledge graph”. As a result, data that has become part of this graph can be queried directly, thereby ensuring that it remains Findable, Accessible, Interoperable and Reusable (FAIR) through a variety of semantic resources.
***
Research paper:
Montanaro G, Balhoff JP, Girón JC, Söderholm M, Tarasov S (2024) Computable species descriptions and nanopublications: applying ontology-based technologies to dung beetles (Coleoptera, Scarabaeinae). Biodiversity Data Journal 12: e121562. https://doi.org/10.3897/BDJ.12.e121562
What expert recommendations did the BiCIKL consortium give to policy makers and research funders to ensure that biodiversity data is FAIR, linked, open and, indeed, future-proof? Find out in the blog post summarising key lessons learnt from the Horizon 2020 project.
Today, 16 September 2023, we are celebrating our tenth anniversary: an important milestone that has prompted us to reflect on the incredible journey thatBiodiversity Data Journal (BDJ) has been through.
From the very beginning, our mission was clear: to revolutionise the way biodiversity data is shared, accessed, and harnessed. This journey has been one of innovation, collaboration, and a relentless commitment to making biodiversity data FAIR – Findable, Accessible, Interoperable, and Reusable.
Over the past 10 years, BDJ, under the auspices of our esteemed publisher Pensoft, has emerged as a trailblazing force in biodiversity science. Our open-access platform has empowered researchers from around the world to publish comprehensive papers that seamlessly blend text with morphological descriptions, occurrences, data tables, and more. This holistic approach has enriched the depth of research articles and contributed to the creation of an interconnected web of biodiversity information.
In addition, by utilising ARPHA Writing Tool and ARPHA Platform as our entirely online manuscript authoring and submission interface, we have simplified the integration of structured data and narrative, reinforcing our commitment to simplifying the research process.
One of our most significant achievements is democratising access to biodiversity data. By dismantling access barriers, we have catalysed the emergence of novel research directions, equipping scientists with the tools to combat critical global challenges such as biodiversity loss, habitat degradation, and climate fluctuations.
We firmly believe that data should be openly accessible to all, fostering collaboration and accelerating scientific discovery. By upholding the FAIR principles, we ensure that the datasets accompanying our articles are not only discoverable and accessible, but also easy to integrate and reusable across diverse fields.
As we reflect on the past decade, we are invigorated by the boundless prospects on the horizon. We will continue working on to steer the global research community towards a future where biodiversity data is open, accessible, and harnessed to tackle global challenges.
Ten years of biodiversity research
To celebrate our anniversary, we have curated some of our most interesting and memorable BDJ studies from the past decade.
Recently, news outlets were quick to cover a new species of ‘snug’ published in our journal.
“Life Beneath the Ice”, a short musical film about light and life beneath the Antarctic sea-ice by Dr. Emiliano Cimoli
We extend our heartfelt gratitude to our authors, reviewers, readers, and the entire biodiversity science community for being integral parts of this transformative journey. Together, we have redefined scientific communication, and we will continue to push the boundaries of knowledge.
Novel nanopublication workflows and templates for associations between organisms, taxa and their environment are the latest outcome of the collaboration between Knowledge Pixels and Pensoft.
Nanopublications complement human-created narratives of scientific knowledge with elementary, machine-actionable, simple and straightforward scientific statements that prompt sharing, finding, accessibility, citability and interoperability.
By making it easier to trace individual findings back to their origin and/or follow-up updates, nanopublications also help to better understand the provenance of scientific data.
With the nanopublication format and workflow, authors make sure that key scientific statements – the ones underpinning their research work – are efficiently communicated in both human-readable and machine-actionable mannerin line with FAIR principles. Thus, their contributions to science are better prepared for a reality driven by AI technology.
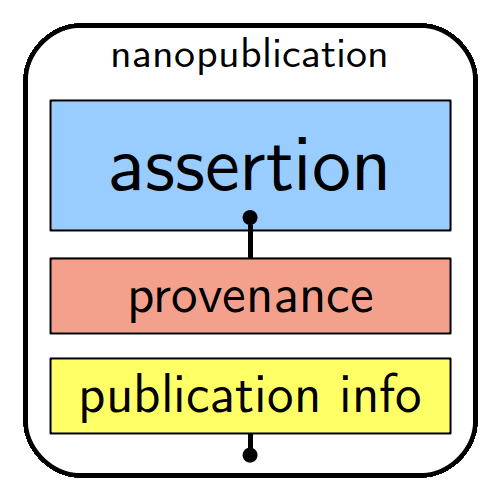
The machine-actionability of nanopublications is a standard due to each assertion comprising a subject, an object and a predicate (type of relation between the subject and the object), complemented by provenance, authorship and publication information. A unique feature here is that each of the elements is linked to an online resource, such as a controlled vocabulary, ontology or standards.
Now, what’s new?
As a result of the partnership between high-tech startup Knowledge Pixels and open-access scholarly publisher and technology provider Pensoft, authors in Biodiversity Data Journal (BDJ) can make use of three types of nanopublications:
Nanopublications associated with a manuscript submitted to BDJ. This workflow lets authors add a Nanopublications section within their manuscript while preparing their submission in the ARPHA Writing Tool (AWT). Basically, authors ‘highlight’ and ‘export’ key points from their papers as nanopublications to further ensure the FAIRness of the most important findings from their publications.
Standalone nanopublication related to any scientific publication, regardless of its author or source. This can be done via the Nanopublications page accessible from the BDJ website. The main advantage of standalone nanopublication is that straightforward scientific statements become available and FAIR early on, and remain ready to be added to a future scholarly paper.
Nanopublications as annotations to existing scientific publications. This feature is available from several journals published on the ARPHA Platform, including BDJ. By attaching an annotation to the entire paper (via the Nanopublication tab) or a text selection (by first adding an inline comment, then exporting it as a nanopublication), a reader can evaluate and record an opinion about any article using a simple template based on the Citation Typing Ontology (CiTO).
Nanopublications for biodiversity data?
At Biodiversity Data Journal (BDJ), authors can now incorporate nanopublications within their manuscripts to future-proofthe most important assertions on biological taxa and organisms or statements about associations of taxa or organisms and their environments.
On top of being shared and archived by means of a traditional research publication in an open-access peer-reviewed journal, scientific statements using the nanopublication format will also remain ‘at the fingertips’ of automated tools that may be the next to come looking for this information, while mining the Web.
Using the nanopublication workflows and templates available at BDJ, biodiversity researchers can share assertions, such as:
So far, the available biodiversity nanopublication templates cover a range of associations, including those between taxa and individual organisms, as well as between those and their environments and nucleotide sequences.
Nanopublication template customised for biodiversity research publications available from Nanodash.
As a result, those easy-to-digest ‘pixels of knowledge’ can capture and disseminate information about single observations, as well as higher taxonomic ranks.
The novel domain-specific publication format was launched as part of thecollaboration betweenKnowledge Pixels – an innovative startup tech company aiming to revolutionise scientific publishing and knowledge sharing and the open-access scholarly publisherPensoft.
Basically, a nanopublication – unlike a research article – is a tiny snippet of a precise and structured scientific finding (e.g. medication X treats disease Y), which exists as a reusable and cite-able pieces of a growing knowledge graph stored on a decentralised server network in a format that it is readable for humans, but also “understandable” and actionable for computers and their algorithms.
These semantic statements expressed in community-agreed terms, openly available through links to controlled vocabularies, ontologies and standards, are not only freely accessible to everyone in both human-readable and machine-actionable formats, but also easy-to-digest for computer algorithms and AI-powered assistants.
In short, nanopublications allow us to browse and aggregate such findings as part of a complex scientific knowledge graph. Therefore, nanopublications bring us one step closer to the next revolution in scientific publishing, which started with the emergence and increasing adoption of knowledge graphs.
“As pioneers in the semantic open access scientific publishing field for over a decade now, we at Pensoft are deeply engaged with making research work actually available at anyone’s fingertips. What once started as breaking down paywalls to research articles and adding the right hyperlinks in the right places, is time to be built upon,”
By letting computer algorithms access published research findings in a structured format, nanopublications allow for the knowledge snippets that they are intended to communicate to be fully understandable and actionable. With nanopublications, each of those fragmentsof scientific information is interconnected and traceable back to its author(s) and scientific evidence.
A nanopublication is a tiny snippet of a precise and structured scientific finding (e.g. medication X treats disease Y), which exists within a growing knowledge graph stored on a decentralised server network in a format that it is readable for humans, but also “understandable” and actionable for computers and their algorithms. Illustration by Knowledge Pixels.
By building on shared knowledge representation models, these data become Interoperable (as in the Iin FAIR), so that they can be delivered to the right user, at the right time, in the right place , ready to be reused (as per the R in FAIR) in new contexts.
Another issue nanopublications are designed to address is research scrutiny. Today, scientific publications are produced at an unprecedented rate that is unlikely to cease in the years to come, as scholarship embraces the dissemination of early research outputs, including preprints, accepted manuscripts and non-conventional papers.
A network of interlinked nanopublications could also provide a valuable forum for scientists to test, compare, complement and build on each other’s results and approaches to a common scientific problem, while retaining the record of their cooperation each step along the way.
***
We encourage you to try the nanopublications workflow yourself when submitting your next biodiversity paper to Biodiversity Data Journal.
Community feedback on this pilot project and suggestions for additional biodiversity-related nanopublication templates are very welcome!
On the journal website: https://bdj.pensoft.net/, you can find more about the unique features and workflows provided by the Biodiversity Data Journal (BDJ), including innovative research paper formats (e.g. Data Paper, OMICS Data Paper, Software Description, R Package, Species Conservation Profiles, Alien Species Profile), expert-provided data audit for each data paper submission, automated data export and more.
Don’t forget to also sign up for the BDJ newsletter via the Email alert form on the journal’s homepage and follow it on Twitter and Facebook.
Earlier this year, Knowledge Pixels and Pensoft presented several routes for readers and researchers to contribute to research outputs – either produced by themselves or by others – through nanopublications generated through and visualised in Pensoft’s cross-disciplinary Research Ideas and Outcomes (RIO) journal, which uses the same nanopublication workflows.
In collaboration with the Finnish Biodiversity Information Facility (FinBIF) and Pensoft Publishers, GBIF has announced a new call for authors to submit and publish data papers on Russia in a special collection of Biodiversity Data Journal (BDJ). The call extends and expands upon a successful effort in 2020 to mobilize data from European Russia.
Until 30 June 2022, Pensoft will waive the article processing fee (normally €650) for the first 50 accepted data paper manuscripts that meet the following criteria for describing a dataset:
Authors must prepare the manuscript in English and submit it in accordance with BDJ’s instructions to authors by 30 June 2022. Late submissions will not be eligible for APC waivers.
Sponsorship is limited to the first 50 accepted submissions meeting these criteria on a first-come, first-served basis. The call for submissions can therefore close prior to the deadline of 30 June 2022. Authors may contribute to more than one manuscript, but artificial division of the logically uniform data and data stories, or “salami publishing”, is not allowed.
BDJ will publish a special issue including the selected papers by the end of 2021. The journal is indexed by Web of Science (Impact Factor 1.225), Scopus (CiteScore: 2.0) and listed in РИНЦ / eLibrary.ru.
For non-native speakers, please ensure that your English is checked either by native speakers or by professional English-language editors prior to submission. You may credit these individuals as a “Contributor” through the AWT interface. Contributors are not listed as co-authors but can help you improve your manuscripts. BDJ will introduce stricter language checks for the 2022 call; poorly written submissions will be rejected prior to the peer-review process.
In addition to the BDJ instruction to authors, data papers must referenced the dataset by a) citing the dataset’s DOI b) appearing in the paper’s list of references c) including “Northern Eurasia 2022” in the Project Data: Title and “N-Eurasia-2022“ in Project Data: Identifier in the dataset’s metadata.
Authors should explore the GBIF.org section on data papers and Strategies and guidelines for scholarly publishing of biodiversity data. Manuscripts and datasets will go through a standard peer-review process. When submitting a manuscript to BDJ, authors are requested to assign their manuscript to the Topical Collection: Biota of Northern Eurasia at step 3 of the submission process. To initiate the manuscript submission, remember to press the Submit to the journal button.
Questions may be directed either to Dmitry Schigel, GBIF scientific officer, or Yasen Mutafchiev, managing editor of Biodiversity Data Journal.
This project is a continuation of successful calls for data papers from European Russia in 2020 and 2021. The funded papers are available in the Biota of Russia special collection and the datasets are shown on the project page.
Definition of terms
Datasets with more than 7,000 presence records new to GBIF.org
Datasets should contain at a minimum 7,000 presence records new to GBIF.org. While the focus is on additional records for the region, records already published in GBIF may meet the criteria of ‘new’ if they are substantially improved, particularly through the addition of georeferenced locations.” Artificial reduction of records from otherwise uniform datasets to the necessary minimum (“salami publishing”) is discouraged and may result in rejection of the manuscript. New submissions describing updates of datasets, already presented in earlier published data papers will not be sponsored.
Justification for publishing datasets with fewer records (e.g. sampling-event datasets, sequence-based data, checklists with endemics etc.) will be considered on a case-by-case basis.
Datasets with high-quality data and metadata
Authors should start by publishing a dataset comprised of data and metadata that meets GBIF’s stated data quality requirement. This effort will involve work on an installation of the GBIF Integrated Publishing Toolkit. BDJ will conduct its standard data audit and technical review. All datasets must pass the data audit prior to a manuscript being forwarded for peer review.
Only when the dataset is prepared should authors then turn to working on the manuscript text. The extended metadata you enter in the IPT while describing your dataset can be converted into manuscript with a single-click of a button in the ARPHA Writing Tool (see also Creation and Publication of Data Papers from Ecological Metadata Language (EML) Metadata. Authors can then complete, edit and submit manuscripts to BDJ for review.
Datasets with geographic coverage in Northern Eurasia
In correspondence with the funding priorities of this programme, at least 80% of the records in a dataset should have coordinates that fall within the priority areas of Russia, Ukraine, Belarus, Kazakhstan, Kyrgyzstan, Uzbekistan, Tajikistan, Turkmenistan, Moldova, Georgia, Armenia and Azerbaijan. However, authors of the paper may be affiliated with institutions anywhere in the world.
***
Follow Biodiversity Data Journal on Twitter and Facebook to keep yourself posted about the new research published.
Between now and 15 September 2021, the article processing fee (normally €550) will be waived for the first 36 papers, provided that the publications are accepted and meet the following criteria that the data paper describes a dataset:
The manuscript must be prepared in English and is submitted in accordance with BDJ’s instructions to authors by 15 September 2021. Late submissions will not be eligible for APC waivers.
Sponsorship is limited to the first 36 accepted submissions meeting these criteria on a first-come, first-served basis. The call for submissions can therefore close prior to the stated deadline of 15 September 2021. Authors may contribute to more than one manuscript, but artificial division of the logically uniform data and data stories, or “salami publishing”, is not allowed.
BDJ will publish a special issue including the selected papers by the end of 2021. The journal is indexed by Web of Science (Impact Factor 1.331), Scopus (CiteScore: 2.1) and listed in РИНЦ / eLibrary.ru.
For non-native speakers, please ensure that your English is checked either by native speakers or by professional English-language editors prior to submission. You may credit these individuals as a “Contributor” through the AWT interface. Contributors are not listed as co-authors but can help you improve your manuscripts.
In addition to the BDJ instruction to authors, it is required that datasets referenced from the data paper a) cite the dataset’s DOI, b) appear in the paper’s list of references, and c) has “Russia 2021” in Project Data: Title and “N-Eurasia-Russia2021“ in Project Data: Identifier in the dataset’s metadata.
Questions may be directed either to Dmitry Schigel, GBIF scientific officer, or Yasen Mutafchiev, managing editor of Biodiversity Data Journal.
The 2021 extension of the collection of data papers will be edited by Vladimir Blagoderov, Pedro Cardoso, Ivan Chadin, Nina Filippova, Alexander Sennikov, Alexey Seregin, and Dmitry Schigel.
Datasets with more than 5,000 records that are new to GBIF.org
Datasets should contain at a minimum 5,000 new records that are new to GBIF.org. While the focus is on additional records for the region, records already published in GBIF may meet the criteria of ‘new’ if they are substantially improved, particularly through the addition of georeferenced locations.” Artificial reduction of records from otherwise uniform datasets to the necessary minimum (“salami publishing”) is discouraged and may result in rejection of the manuscript. New submissions describing updates of datasets, already presented in earlier published data papers will not be sponsored.
Justification for publishing datasets with fewer records (e.g. sampling-event datasets, sequence-based data, checklists with endemics etc.) will be considered on a case-by-case basis.
Datasets with high-quality data and metadata
Authors should start by publishing a dataset comprised of data and metadata that meets GBIF’s stated data quality requirement. This effort will involve work on an installation of the GBIF Integrated Publishing Toolkit.
Only when the dataset is prepared should authors then turn to working on the manuscript text. The extended metadata you enter in the IPT while describing your dataset can be converted into manuscript with a single-click of a button in the ARPHA Writing Tool (see also Creation and Publication of Data Papers from Ecological Metadata Language (EML) Metadata. Authors can then complete, edit and submit manuscripts to BDJ for review.
Datasets with geographic coverage in Russia
In correspondence with the funding priorities of this programme, at least 80% of the records in a dataset should have coordinates that fall within the priority area of Russia. However, authors of the paper may be affiliated with institutions anywhere in the world.
***
Check out the Biota of Russia dynamic data paper collection so far.
Follow Biodiversity Data Journal on Twitter and Facebook to keep yourself posted about the new research published.
New dynamic article collection at Biodiversity Data Journal is already accumulating the project’s findings
About 1.4 million species of animals are currently known, but it is generally accepted that this figure grossly underestimates the actual number of species in existence, which likely ranges between five and thirty million species, or even 100 million.
Meanwhile, a far less well-known fact is that even in countries with a long history of taxonomic research, such as Germany, which is currently known to be inhabited by about 48,000 animal species, there are thousands of insect species still awaiting discovery. In particular, the orders Diptera (flies) and Hymenoptera (especially the parasitoid wasps) are insect groups suspected to contain a strikingly large number of undescribed species. With almost 10,000 known species each, these two insect orders account for approximately two-thirds of Germany’s insect fauna, underlining the importance of these insects in many ways.
The conclusion that there are not only a few, but so many unknown species in Germany is a result of the earlier German Barcode of Life projects: GBOL I and GBOL II, both supported by the German Federal Ministry of Education and Research (Bundesministerium für Bildung und Forschung, BMBF) and the Bavarian Ministry of Science under the project Barcoding Fauna Bavarica.
In its previous phases, GBOL aimed to identify all German species reliably, quickly and inexpensively using DNA barcodes. Since the first project was launched twelve years ago, more than 25,000 German animal species have been barcoded. Among them, the comparatively well-known groups, such as butterflies, moths, beetles, grasshoppers, spiders, bees and wasps, showed an almost complete coverage of the species inventory.
In 2020, another BMBF-funded DNA barcoding project, titled GBOL III: Dark Taxa, was launched, in order to focus on the lesser-known groups of Diptera and parasitoid Hymenoptera, which are often referred to as “dark taxa”. The new project commenced at three major German natural history institutions: the Zoological Research Museum Alexander Koenig (Bonn), the Bavarian State Collection of Zoology (SNSB, Munich) and the State Museum of Natural History Stuttgart, in collaboration with the University of Würzburg and the Entomological Society Krefeld. Together, the project partners are to join efforts and skills to address a range of questions related to the taxonomy of the “dark taxa” in Germany.
As part of the initiative, the project partners are invited to submit their results and outcomes in the dedicated GBOL III: Dark Taxa article collection in the peer-reviewed, open-access Biodiversity Data Journal. There, the contributions will be published dynamically, as soon as approved and ready for publication. The articles will include taxonomic revisions, checklists, data papers, contributions to methods and protocols, employed in DNA barcoding studies with a focus on the target taxa of the project.
“The collection of articles published in the Biodiversity Data Journal is an excellent approach to achieving the consortium’s goals and project partners are encouraged to take advantage of the journal’s streamlined publication workflows to publish and disseminate data and results that were generated during the project,”
says the collection’s editor Dr Stefan Schmidt of the Bavarian State Collection of Zoology.
***
Find and follow the dynamic article collection GBOL III: Dark Taxa in Biodiversity Data Journal.
Pensoft creates a specialised data paper article type for the omics community within Biodiversity Data Journal to reflect the specific nature of omics data. The scholarly publisher and technology provider established a manuscript template to help standardise the description of such datasets and their most important features.
By Mariya Dimitrova, Raïssa Meyer, Pier Luigi Buttigieg, Lyubomir Penev
Data papers are scientific papers which describe a dataset rather than present and discuss research results. The concept was introduced to the biodiversity community by Chavan and Penev in 2011 as the result of a joint project of GBIF and Pensoft.
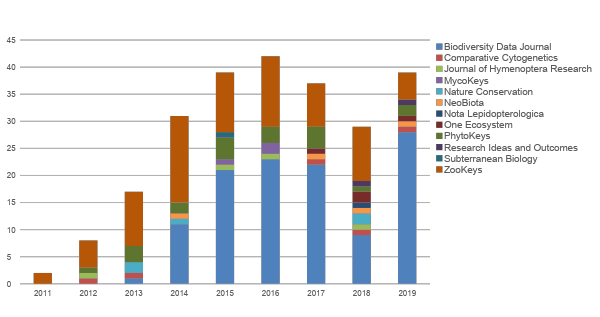
Since then, Pensoft has implemented the data paper in several of its journals (Fig. 1). The recognition gained through data papers is an important incentive for researchers and data managers to author better quality metadata and to make it Findable, Accessible, Interoperable and Re-usable (FAIR). High quality and FAIRness of (meta)data are promoted through providing peer review, data audit, permanent scientific record and citation credit as for any other scholarly publication. One can read more on the different types of data papers and how they help to achieve these goals in the Strategies and guidelines for scholarly publishing of biodiversity data (https://doi.org/10.3897/rio.3.e12431).
Fig. 1 Number of data papers published in Pensoft’s journals since 2011.
The data paper concept was initially based on the standard metadata descriptions, using the Ecological Metadata Language (EML). Apart from distinguishing a specialised place for dataset descriptions by creating a data paper article type, Pensoft has developed multiple workflows for streamlined import of metadata from various repositories and their conversion into data paper a manuscripts in Pensoft’s ARPHA Writing Tool (AWT). You can read more about the EML workflow in this blog post.
Similarly, we decided to create a specialised data paper article type for the omics community within Pensoft’s Biodiversity Data Journal to reflect the specific nature of omics data. We established a manuscript template to help standardise the description of such datasets and their most important features. This initiative was supported in part by the IGNITE project.
How can authors publish omics data papers?
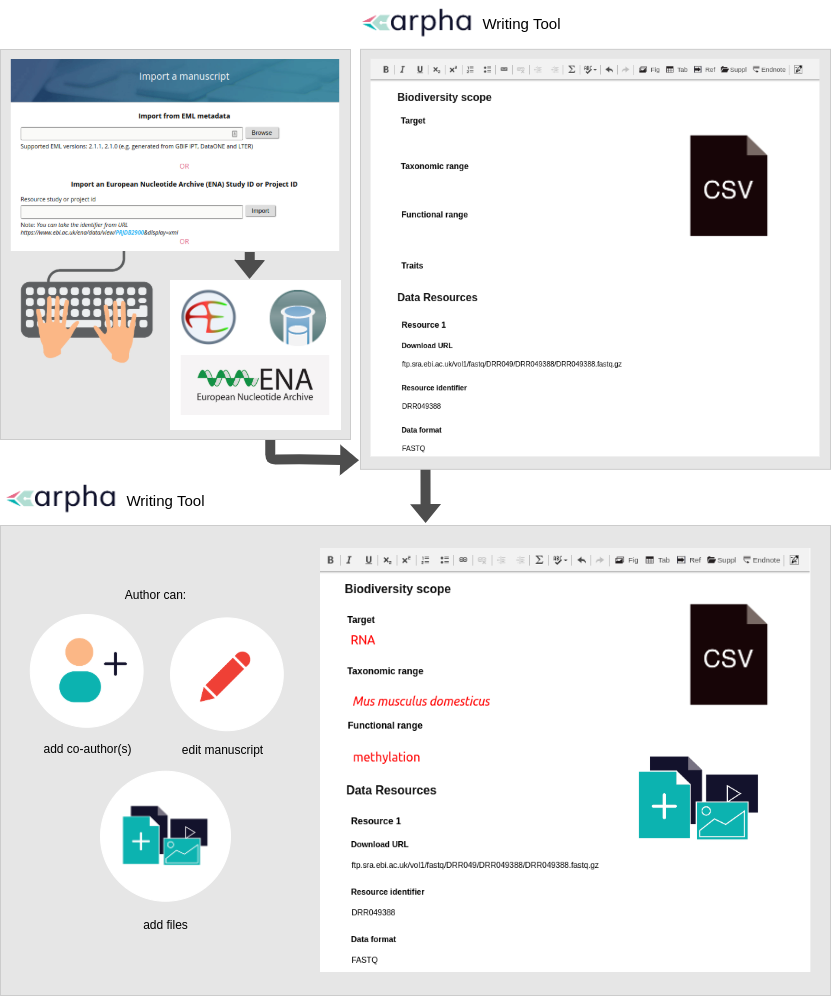
There are two ways to do publish omics data papers – (1) to write a data paper manuscript following the respective template in the ARPHA Writing Tool (AWT) or (2) to convert metadata describing a project or study deposited in EMBL-EBI’s European Nucleotide Archive (ENA) into a manuscript within the AWT.
The first method is straightforward but the second one deserves more attention. We focused on metadata published in ENA, which is part of the International Nucleotide Sequence Database Collaboration (INSDC) and synchronises its records with these of the other two members (DDBJ and NCBI). ENA is linked to the ArrayExpress and BioSamples databases, which describe sequencing experiments and samples, and follow the community-accepted metadata standards MINSEQE and MIxS. To auto populate a manuscript with a click of a button, authors can provide the accession number of the relevant ENA Study of Project and our workflow will automatically retrieve all metadata from ENA, as well as any available ArrayExpress or BioSamples records linked to it (Fig. 2). After that, authors can edit any of the article sections in the manuscript by filling in the relevant template fields or creating new sections, adding text, figures, citations and so on.
An important component of the OMICS data paper manuscript is a supplementary table containing MIxS-compliant metadata imported from BioSamples. When available, BioSamples metadata is automatically converted to a long table format and attached to the manuscript. The authors are not permitted to edit or delete it inside the ARPHA Writing Tool. Instead, if desired, they should correct the associated records in the sourced BioSamples database. We have implemented a feature allowing the automatic re-import of corrected BioSamples records inside the supplementary table. In this way, we ensure data integrity and provide a reliable and trusted source for accessing these metadata.
Fig. 2 Automated generation of omics data paper manuscripts through import and conversion of metadata associated with the Project ID or Study ID at ENA
Here is a step-by-step guide for conversion of ENA metadata into a data paper manuscript:
The author has published a dataset to any of the INSDC databases. They copy its ENA Study or Project accession number.
The author goes to the Biodiversity Data Journal (BDJ) webpage, clicks the “Start a manuscript” buttоn and selects OMICS Data Paper template in the ARPHA Writing Tool (AWT). Alternatively, the author can also start from the AWT website, click “Create a manuscript”, and select “OMICS Data Paper” as the article type, the Biodiversity Data Journal will be automatically marked by the system. The author clicks the “Import a manuscript” button at the bottom of the webpage.
The author pastes the ENA Study or Project accession number inside the relevant text box (“Import an European Nucleotide Archive (ENA) Study ID or Project ID”) and clicks “Import”.
The Project or Study metadata is converted into an OMICS data paper manuscript along with the metadata from ArrayExpress and BioSamples if available. The author can start making changes to the manuscript, invite co-authors and then submit it for technical evaluation, peer review and publication.
Our innovative workflow makes authoring omics data papers much easier and saves authors time and efforts when inserting metadata into the manuscript. It takes advantage of existing links between data repositories to unify biodiversity and omics knowledge into a single narrative. This workflow demonstrates the importance of standardisation and interoperability to integrate data and metadata from different scientific fields.
We have established a special collection for OMICS data papers in the Biodiversity Data Journal. Authors are invited to describe their omics datasets by using the novel streamlined workflow for creating a manuscript at a click of a button from metadata deposited in ENA or by following the template to create their manuscript via the non-automated route.
To stimulate omics data paper publishing, the first 10 papers will be published free of charge. Upon submission of an omics data paper manuscript, do not forget to assign it to the collection Next-generation publishing of omics data.
Following recent API integration with ReviewerCredits, Pensoft – the scholarly publisher and technology provider – has launched a pilot phase with one of its peer-reviewed, open-access journal: Biodiversity Data Journal (BDJ). Reviewers, who create an account on ReviewerCredits, will automatically record their peer review contributions, which will be certified via the platform and receive rewards and recognition within the scholarly community and fellow scientists.
Following recent API integration with ReviewerCredits, Pensoft – the scholarly publisher and technology provider – has launched a pilot phase with one of its peer-reviewed, open-access journal: Biodiversity Data Journal(BDJ). Reviewers, who create an account on ReviewerCredits,will automatically record their peer review contributions, which will be certified via the platform and receive rewards and recognition within the scholarly community and fellow scientists.
Apart from a seamless system to showcase their peer review activity, reviewers will also be assigned virtual credits, which can be redeemed for benefits provided by selected partners, including discounted APCs.
The registration on ReviewerCredits is free. While a reviewer can register any of his/her peer reviews on the platform, reviews for journals partnering with ReviewerCredits earn additional redeemable credits.
Once a reviewer signs in BDJ using their own reviewer account, a pop-up window will recommend that an account on ReviewerCredits is created by using an ORCID ID or an email address. Once the registration is complete, each completed peer review contributionwill automatically appear as certified on ReviewerCredits, as soon as the editor submits a final decision on the reviewed manuscript. In line with peer-review confidentiality, the entry displayed on ReviewerCredits will not contain the content of the review, nor the particular paper it is associated with.
“We are happy to partner with ReviewerCredits to further recognise, encourage and reward the contribution of reviewers in BDJ. No one should forget that, at the end of the day, it is up to reviewers to ensure that only good and quality science makes its way in the world. Unfortunately, though, their role in scholarship has traditionally been overlooked and we all need to put in effort to change the status quo,”
comments Prof. Lyubomir Penev, founder and CEO of Pensoft.
“We are excited by the collaboration with Pensoft on this project and to acknowledge BDJ among our prestigious partner journals. Pensoft has proved an extremely competent partner, well aware of the importance for journals to state the value of their peer review process. We work together to strengthen the collaboration between journals and reviewers and we are looking forward to a growing collaboration with Pensoft publications,”
Prof. Giacomo Bellani, co-founder and president of ReviewerCredits, underlines the value and enthusiasm for this new partnership.
About ReviewerCredits:
ReviewerCredits is a startup company, accredited to the University of Milan Bicocca, launched in 2017 by enthusiastic active researchers and scientists. ReviewerCredits is an independent platform dedicated to scientists, Journals and Publishers addressing the peer review process.
Through their new collaboration, the partners encourage publication of dynamic additional research outcomes to support reusability and reproducibility in science
In a new partnership between open-access Biodiversity Data Journal (BDJ) and workflow software development platform Profeza, authors submitting their research to the scholarly journal will be invited to prepare a Reuse Recipe Document via CREDIT Suite to encourage reusability and reproducibility in science. Once published, their articles will feature a special widget linking to additional research output, such as raw, experimental repetitions, null or negative results, protocols and datasets.
A Reuse Recipe Document is a collection of additional research outputs, which could serve as a guidelines to another researcher trying to reproduce or build on the previously published work. In contrast to a research article, it is a dynamic ‘evolving’ research item, which can be later updated and also tracked back in time, thanks to a revision history feature.
Both the Recipe Document and the Reproducible Links, which connect subsequent outputs to the original publication, are assigned with their own DOIs, so that reuse instances can be easily captured, recognised, tracked and rewarded with increased citability.
With these events appearing on both the original author’s and any reuser’s ORCID, the former can easily gain further credibility for his/her work because of his/her work’s enhanced reproducibility, while the latter increases his/her own by showcasing how he/she has put what he/she has cited into use.
Furthermore, the transparency and interconnectivity between the separate works allow for promoting intra- and inter-disciplinary collaboration between researchers.
“At BDJ, we strongly encourage our authors to use CREDIT Suite to submit any additional research outputs that could help fellow scientists speed up progress in biodiversity knowledge through reproducibility and reusability,” says Prof. Lyubomir Penev, founder of the journal and its scholarly publisher – Pensoft. “Our new partnership with Profeza is in itself a sign that collaboration and integrity in academia is the way to good open science practices.”
“Our partnership with Pensoft is a great step towards gathering crucial feedback and insight concerning reproducibility and continuity in research. This is now possible with Reuse Recipe Documents, which allow for authors and reusers to engage and team up with each other,” says Sheevendra, Co-Founder of Profeza.