From 1973 to 2020, Australian zoologist Dr Robert Mesibov kept careful records of the “where” and “when” of his plant and invertebrate collecting trips. Now, he has made those valuable biodiversity data freely and easily accessible via the Zenodo open-data repository, so that future researchers can rely on this “authority file” when using museum specimens collected from those events in their own studies. The new dataset is described in the open-access, peer-reviewed Biodiversity Data Journal.
While checking museum records, Dr Robert Mesibov found there were occasional errors in the dates and places for specimens he had collected many years before. He was not surprised.
“It’s easy to make mistakes when entering data on a computer from paper specimen labels”, said Mesibov. “I also found specimen records that said I was the collector, but I know I wasn’t!”
One solution to this problem was what librarians and others have long called an “authority file”.
“It’s an authoritative reference, in this case with the correct details of where I collected and when”, he explained.
“I kept records of almost all my collecting trips from 1973 until I retired from field work in 2020. The earliest records were on paper, but I began storing the key details in digital form in the 1990s.”
The 48-year record has now been made publicly available via the Zenodo open-data repository after conversion to the Darwin Core data format, which is widely used for sharing biodiversity information. With this “authority file”, described in detail in the open-access, peer-reviewed Biodiversity Data Journal, future researchers will be able to rely on sound, interoperable and easy to access data, when using those museum specimens in their own studies, instead of repeating and further spreading unintentional errors.
“There are 3829 collecting events in the authority file”, said Mesibov, “from six Australian states and territories. For each collecting event there are geospatial and date details, plus notes on the collection.”
Mesibov hopes the authority file will be used by museums to correct errors in their catalogues.
“It should also save museums a fair bit of work in future”, he explained. “No need to transcribe details on specimen labels into digital form in a database, because the details are already in digital form in the authority file.”
Mesibov points out that in the 19th and 20th centuries, lists of collecting events were often included in the reports of major scientific expeditions.
“Those lists were authority files, but in the pre-digital days it was probably just as easy to copy collection data from specimen labels.”
“In the 21st century there’s a big push to digitise museum specimen collections”, he said. “Museum databases often have lookup tables with scientific names and the names of collectors. These lookup tables save data entry time and help to avoid errors in digitising.”
“Authority files for collecting events are the next logical step,” said Mesibov. “They can be used as lookup tables for all the important details of individual collections: where, when, by whom and how.”
###
Research paper:
Mesibov RE (2021) An Australian collector’s authority file, 1973–2020. Biodiversity Data Journal 9: e70463. https://doi.org/10.3897/BDJ.9.e70463
Australia’s unique and highly endemic flora and fauna are threatened by rapid losses in biodiversity and ecosystem health, caused by human influence and environmental challenges. To monitor and respond to these trends, scientists and policy-makers need reliable data.
Biodiversity researchers and managers often don’t have the necessary information, or access to it, to tackle some of the greatest environmental challenges facing society, such as biodiversity loss or climate change. Data can be a powerful tool for the development of science and decision-making, which is where the Atlas of Living Australia (ALA) comes in.
ALA – Australia’s national biodiversity database – uses cutting-edge digital tools which enable people to share, access and analyse data about local plants, animals and fungi. It brings together millions of sightings as well as environmental data like rainfall and temperature in one place to be searched and analysed. All data are made publicly available – ALA was established in line with open-access principles and uses an open-source code base.
— Atlas of Living Aust (@atlaslivingaust) April 21, 2021
Established in 2010 under the Australian Government’s National Collaborative Research Infrastructure Strategy (NCRIS) to support the research sector with trusted biodiversity data, it now delivers data and related services to more than 80,000 users every year, helping scientists, policy makers, environmental planners, industry, and the general public to work more efficiently. It also supports the international community as the Australian node of the Global Biodiversity Information Facility and the code base for the successful international Living Atlases community.
With thousands of records being added daily, the ALA currently contains nearly 95 million occurrence records of over 111,000 species, the earliest of them being from the late 1600s. Among them, 1.7 million are observation records harvested by computer algorithms, and the trend is that their share will keep growing.
An ALA staff member. Photo by CSIRO
Recognising the potential of citizen science for contributing valuable information to Australia’s biodiversity, the ALA became a member of the iNaturalist Network in 2019 and established an Australian iNaturalist node to encourage people to submit their species observations. Projects like DigiVol and BioCollect were also born from ALA’s interest in empowering citizen science.
The ALA BioCollect platform supports biodiversity-related projects by capturing both descriptive metadata and raw primary field data. BioCollect has a strong citizen science emphasis, with 524 citizen science projects that are open to involvement by anyone. The platform also provides information on projects related to ecoscience and natural resource management activities.
Hosted by the Australian Museum, DigiVol is a volunteer portal where over 6,000 public volunteers have transcribed over 800,000 specimen labels and 124,000 pages of field notes. Harnessing the power and passion of volunteers, the tool makes more information available to science by digitising specimens, images, field notes and archives from collections all over the world.
Built on a decade of partnerships with biodiversity data partners, government departments, community and citizen science organisations, the ALA provides a robust suite of services, including a range of data systems and software applications that support both the research sector and decision makers. Well regarded both domestically and internationally, it has built a national community that is working to improve the availability and accessibility of biodiversity data.
Original source:
Belbin L, Wallis E, Hobern D, Zerger A (2021) The Atlas of Living Australia: History, current state and future directions. Biodiversity Data Journal 9: e65023. https://doi.org/10.3897/BDJ.9.e65023
Between now and 15 September 2021, the article processing fee (normally €550) will be waived for the first 36 papers, provided that the publications are accepted and meet the following criteria that the data paper describes a dataset:
The manuscript must be prepared in English and is submitted in accordance with BDJ’s instructions to authors by 15 September 2021. Late submissions will not be eligible for APC waivers.
Sponsorship is limited to the first 36 accepted submissions meeting these criteria on a first-come, first-served basis. The call for submissions can therefore close prior to the stated deadline of 15 September 2021. Authors may contribute to more than one manuscript, but artificial division of the logically uniform data and data stories, or “salami publishing”, is not allowed.
BDJ will publish a special issue including the selected papers by the end of 2021. The journal is indexed by Web of Science (Impact Factor 1.331), Scopus (CiteScore: 2.1) and listed in РИНЦ / eLibrary.ru.
For non-native speakers, please ensure that your English is checked either by native speakers or by professional English-language editors prior to submission. You may credit these individuals as a “Contributor” through the AWT interface. Contributors are not listed as co-authors but can help you improve your manuscripts.
In addition to the BDJ instruction to authors, it is required that datasets referenced from the data paper a) cite the dataset’s DOI, b) appear in the paper’s list of references, and c) has “Russia 2021” in Project Data: Title and “N-Eurasia-Russia2021“ in Project Data: Identifier in the dataset’s metadata.
Questions may be directed either to Dmitry Schigel, GBIF scientific officer, or Yasen Mutafchiev, managing editor of Biodiversity Data Journal.
The 2021 extension of the collection of data papers will be edited by Vladimir Blagoderov, Pedro Cardoso, Ivan Chadin, Nina Filippova, Alexander Sennikov, Alexey Seregin, and Dmitry Schigel.
Datasets with more than 5,000 records that are new to GBIF.org
Datasets should contain at a minimum 5,000 new records that are new to GBIF.org. While the focus is on additional records for the region, records already published in GBIF may meet the criteria of ‘new’ if they are substantially improved, particularly through the addition of georeferenced locations.” Artificial reduction of records from otherwise uniform datasets to the necessary minimum (“salami publishing”) is discouraged and may result in rejection of the manuscript. New submissions describing updates of datasets, already presented in earlier published data papers will not be sponsored.
Justification for publishing datasets with fewer records (e.g. sampling-event datasets, sequence-based data, checklists with endemics etc.) will be considered on a case-by-case basis.
Datasets with high-quality data and metadata
Authors should start by publishing a dataset comprised of data and metadata that meets GBIF’s stated data quality requirement. This effort will involve work on an installation of the GBIF Integrated Publishing Toolkit.
Only when the dataset is prepared should authors then turn to working on the manuscript text. The extended metadata you enter in the IPT while describing your dataset can be converted into manuscript with a single-click of a button in the ARPHA Writing Tool (see also Creation and Publication of Data Papers from Ecological Metadata Language (EML) Metadata. Authors can then complete, edit and submit manuscripts to BDJ for review.
Datasets with geographic coverage in Russia
In correspondence with the funding priorities of this programme, at least 80% of the records in a dataset should have coordinates that fall within the priority area of Russia. However, authors of the paper may be affiliated with institutions anywhere in the world.
***
Check out the Biota of Russia dynamic data paper collection so far.
Follow Biodiversity Data Journal on Twitter and Facebook to keep yourself posted about the new research published.
New dynamic article collection at Biodiversity Data Journal is already accumulating the project’s findings
About 1.4 million species of animals are currently known, but it is generally accepted that this figure grossly underestimates the actual number of species in existence, which likely ranges between five and thirty million species, or even 100 million.
Meanwhile, a far less well-known fact is that even in countries with a long history of taxonomic research, such as Germany, which is currently known to be inhabited by about 48,000 animal species, there are thousands of insect species still awaiting discovery. In particular, the orders Diptera (flies) and Hymenoptera (especially the parasitoid wasps) are insect groups suspected to contain a strikingly large number of undescribed species. With almost 10,000 known species each, these two insect orders account for approximately two-thirds of Germany’s insect fauna, underlining the importance of these insects in many ways.
The conclusion that there are not only a few, but so many unknown species in Germany is a result of the earlier German Barcode of Life projects: GBOL I and GBOL II, both supported by the German Federal Ministry of Education and Research (Bundesministerium für Bildung und Forschung, BMBF) and the Bavarian Ministry of Science under the project Barcoding Fauna Bavarica.
In its previous phases, GBOL aimed to identify all German species reliably, quickly and inexpensively using DNA barcodes. Since the first project was launched twelve years ago, more than 25,000 German animal species have been barcoded. Among them, the comparatively well-known groups, such as butterflies, moths, beetles, grasshoppers, spiders, bees and wasps, showed an almost complete coverage of the species inventory.
In 2020, another BMBF-funded DNA barcoding project, titled GBOL III: Dark Taxa, was launched, in order to focus on the lesser-known groups of Diptera and parasitoid Hymenoptera, which are often referred to as “dark taxa”. The new project commenced at three major German natural history institutions: the Zoological Research Museum Alexander Koenig (Bonn), the Bavarian State Collection of Zoology (SNSB, Munich) and the State Museum of Natural History Stuttgart, in collaboration with the University of Würzburg and the Entomological Society Krefeld. Together, the project partners are to join efforts and skills to address a range of questions related to the taxonomy of the “dark taxa” in Germany.
As part of the initiative, the project partners are invited to submit their results and outcomes in the dedicated GBOL III: Dark Taxa article collection in the peer-reviewed, open-access Biodiversity Data Journal. There, the contributions will be published dynamically, as soon as approved and ready for publication. The articles will include taxonomic revisions, checklists, data papers, contributions to methods and protocols, employed in DNA barcoding studies with a focus on the target taxa of the project.
“The collection of articles published in the Biodiversity Data Journal is an excellent approach to achieving the consortium’s goals and project partners are encouraged to take advantage of the journal’s streamlined publication workflows to publish and disseminate data and results that were generated during the project,”
says the collection’s editor Dr Stefan Schmidt of the Bavarian State Collection of Zoology.
***
Find and follow the dynamic article collection GBOL III: Dark Taxa in Biodiversity Data Journal.
By Mariya Dimitrova, Georgi Zhelezov, Teodor Georgiev and Lyubomir Penev
The use of written language to record new knowledge is one of the advancements of civilisation that has helped us achieve progress. However, in the era of Big Data, the amount of published writing greatly exceeds the physical ability of humans to read and understand all written information.
More than ever, we need computers to help us process and manage written knowledge. Unlike humans, computers are “naturally fluent” in many languages, such as the formats of the Semantic Web. These standards were developed by the World Wide Web Consortium (W3C) to enable computers to understand data published on the Internet. As a result, computers can index web content and gather data and metadata about web resources.
To help manage knowledge in different domains, humans have started to develop ontologies: shared conceptualisations of real-world objects, phenomena and abstract concepts, expressed in machine-readable formats. Such ontologies can provide computers with the necessary basic knowledge, or axioms, to help them understand the definitions and relations between resources on the Web. Ontologies outline data concepts, each with its own unique identifier, definition and human-legible label.
Matching data to its underlying ontological model is called ontology population and involves data handling and parsing that gives it additional context and semantics (meaning). Over the past couple of years, Pensoft has been working on an ontology population tool, the Pensoft Annotator, which matches free text to ontological terms.
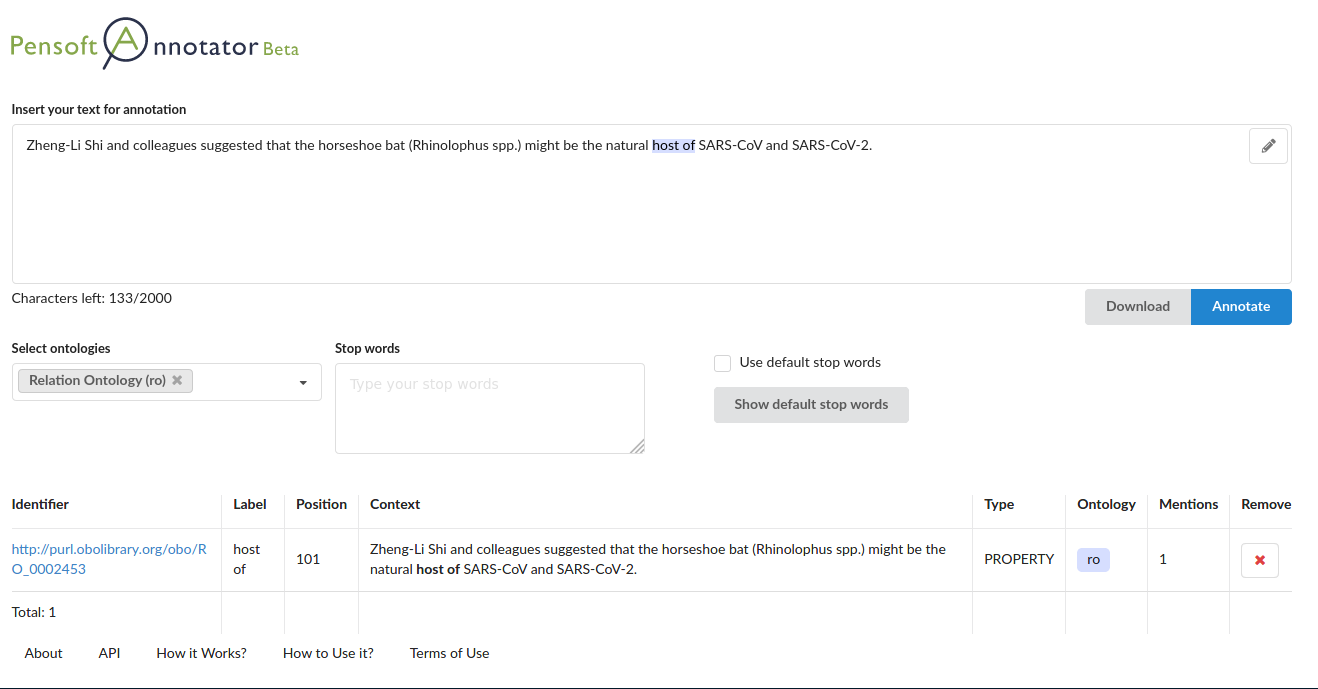
The Pensoft Annotator is a web application, which allows annotation of text input by the user, with any of the available ontologies. Currently, they are the Environment Ontology (ENVO) and the Relation Ontology (RO), but we plan to upload many more. The Annotator can be run with multiple ontologies, and will return a table of matched ontological term identifiers, their labels, as well as the ontology from which they originate (Fig. 1). The results can also be downloaded as a Tab-Separated Value (TSV) file and certain records can be removed from the table of results, if desired. In addition, the Pensoft Annotator allows to exclude certain words (“stopwords”) from the free text matching algorithm. There is a list of default stopwords, common for the English language, such as prepositions and pronouns, but anyone can add new stopwords.
Figure 1. Interface of the Pensoft Annotator application
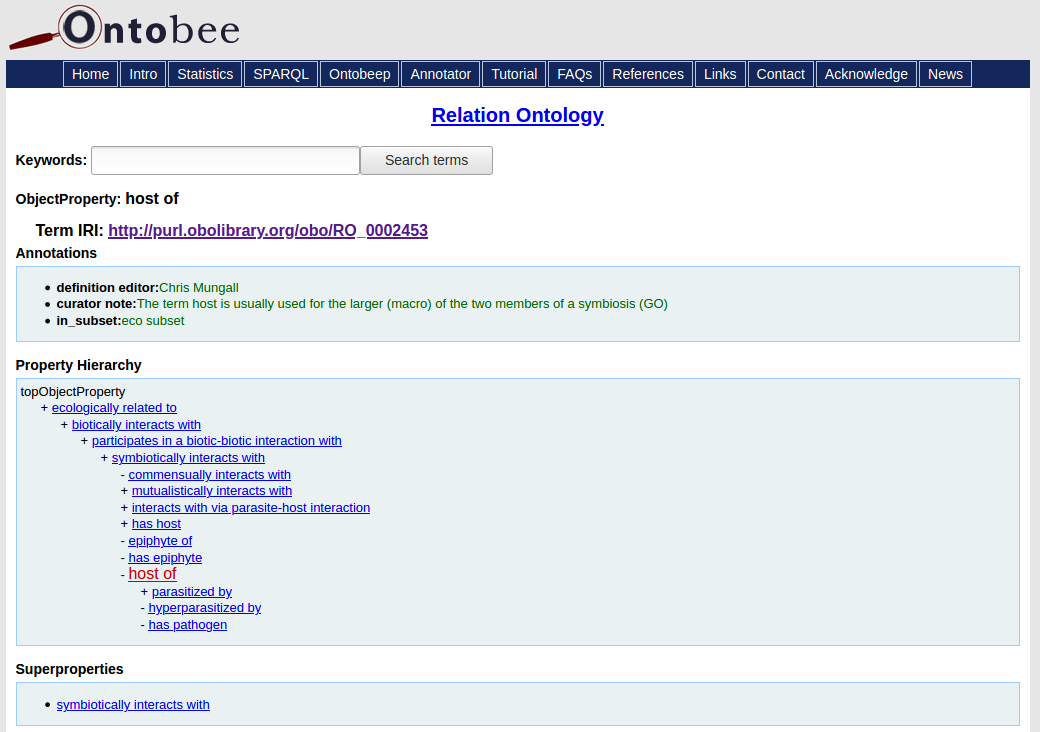
In Figure 1, we have annotated a sentence with the Pensoft Annotator, which yields a single matched term, labeled ‘host of’, from the Relation Ontology (RO). The ontology term identifier is linked to a webpage in Ontobee, which points to additional metadata about the ontology term (Fig. 2).
Figure 2. Web page about ontology term
Such annotation requests can be run to perform text analyses for topic modelling to discover texts which contain host-pathogen interactions. Topic modelling is used to build algorithms for content recommendation (recommender systems) which can be implemented in online news platforms, streaming services, shopping websites and others.
At Pensoft, we use the Pensoft Annotator to enrich biodiversity publications with semantics. We are currently annotating taxonomic treatments with a custom-made ontology based on the Relation Ontology (RO) to discover treatments potentially describing species interactions. You can read more about using the Annotator to detect biotic interactions in this abstract.
The Pensoft Annotator can also be used programmatically through an API, allowing you to integrate the Annotator into your own script. For more information about using the Pensoft Annotator, please check out the documentation.
Proofreading the text of scientific papers isn’t hard, although it can be tedious. Are all the words spelled correctly? Is all the punctuation correct and in the right place? Is the writing clear and concise, with correct grammar? Are all the cited references listed in the References section, and vice-versa? Are the figure and table citations correct?
Proofreading of text is usually done first by the reviewers, and then finished by the editors and copy editors employed by scientific publishers. A similar kind of proofreading is also done with the small tables of data found in scientific papers, mainly by reviewers familiar with the management and analysis of the data concerned.
But what about proofreading the big volumes of data that are common in biodiversity informatics? Tables with tens or hundreds of thousands of rows and dozens of columns? Who does the proofreading?
Sadly, the answer is usually “No one”. Proofreading large amounts of data isn’t easy and requires special skills and digital tools. The people who compile biodiversity data often lack the skills, the software or the time to properly check what they’ve compiled.
The result is that a great deal of the data made available through biodiversity projects like GBIF is — to be charitable — “messy”. Biodiversity data often needs a lot of patient cleaning by end-users before it’s ready for analysis. To assist end-users, GBIF and other aggregators attach “flags” to each record in the database where an automated check has found a problem. These checks find the most obvious problems amongst the many possible data compilation errors. End-users often have much more work to do after the flags have been dealt with.
In 2017, Pensoft employed a data specialist to proofread the online datasets that are referenced in manuscripts submitted to Pensoft’s journals as data papers. The results of the data-checking are sent to the data paper’s authors, who then edit the datasets. This process has substantially improved many datasets (including those already made available through GBIF) and made them more suitable for digital re-use. At blog publication time, more than 200 datasets have been checked in this way.
Note that a Pensoft data audit does not check the accuracy of the data, for example, whether the authority for a species name is correct, or whether the latitude/longitude for a collecting locality agrees with the verbal description of that locality. For a more or less complete list of what does get checked, see the Data checklist at the bottom of this blog post. These checks are aimed at ensuring that datasets are correctly organised, consistently formatted and easy to move from one digital application to another. The next reader of a digital dataset is likely to be a computer program, not a human. It is essential that the data are structured and formatted, so that they are easily processed by that program and by other programs in the pipeline between the data compiler and the next human user of the data.
Pensoft’s data-checking workflow was previously offered only to authors of data paper manuscripts. It is now available to data compilers generally, with three levels of service:
Basic: the compiler gets a detailed report on what needs fixing
Standard: minor problems are fixed in the dataset and reported
Premium: all detected problems are fixed in collaboration with the data compiler and a report is provided
Because datasets vary so much in size and content, it is not possible to set a price in advance for basic, standard and premium data-checking. To get a quote for a dataset, send an email with a small sample of the data topublishing@pensoft.net.
—
Data checklist
Minor problems:
dataset not UTF-8 encoded
blank or broken records
characters other than letters, numbers, punctuation and plain whitespace
more than one version (the simplest or most correct one) for each character
unnecessary whitespace
Windows carriage returns (retained if required)
encoding errors (e.g. “Dum?ril” instead of “Duméril”)
missing data with a variety of representations (blank, “-“, “NA”, “?” etc)
Major problems:
unintended shifts of data items between fields
incorrect or inconsistent formatting of data items (e.g. dates)
different representations of the same data item (pseudo-duplication)
for Darwin Core datasets, incorrect use of Darwin Core fields
data items that are invalid or inappropriate for a field
data items that should be split between fields
data items referring to unexplained entities (e.g. “habitat is type A”)
truncated data items
disagreements between fields within a record
missing, but expected, data items
incorrectly associated data items (e.g. two country codes for the same country)
duplicate records, or partial duplicate records where not needed
For details of the methods used, see the author’s online resources:
by Mariya Dimitrova, Jorrit Poelen, Georgi Zhelezov, Teodor Georgiev, Lyubomir Penev
Fig. 1. Pensoft-GloBI workflow for indexing biotic interactions from scholarly literature
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species, etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 2 in Fig. 1).. We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as json to a GitHub repository, from where they could be accessed by GloBI.
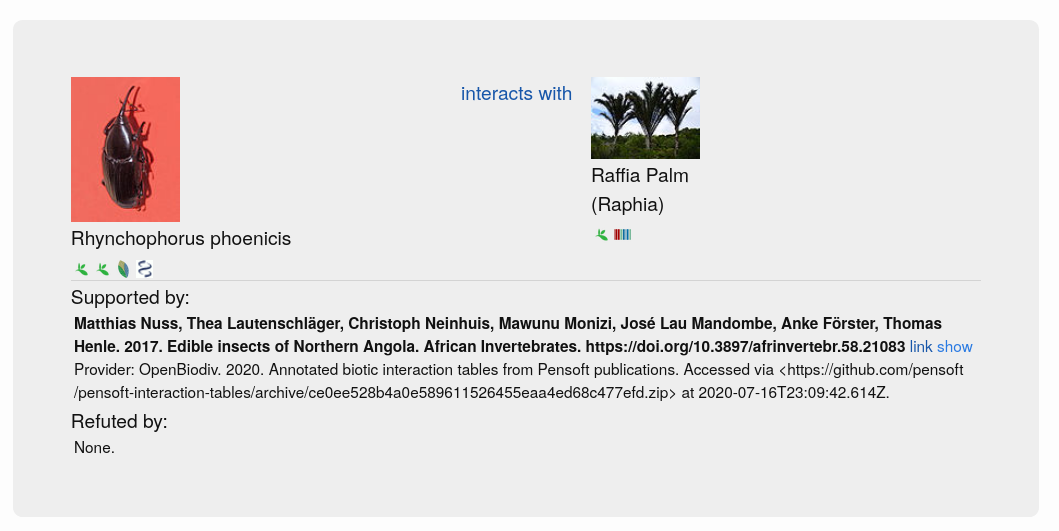
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ (Fig. 2) because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
Fig. 2. Example of a biotic interaction indexed by GloBI.
Examples of species interactions provided by OpenBiodiv and indexed by GloBI are available on GloBI’s website.
In the future we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6,993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 1 in Fig. 1). We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as JSON to a GitHub repository, from where they could be accessed by GloBI.
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
In the future, we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
References
Jorrit H. Poelen, James D. Simons and Chris J. Mungall. (2014). Global Biotic Interactions: An open infrastructure to share and analyze species-interaction datasets. Ecological Informatics. https://doi.org/10.1016/j.ecoinf.2014.08.005.
Additional Information
The work has been partially supported by the International Training Network (ITN) IGNITE funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 764840.
In recognition of the love and devotion that Terry expressed for the study of the World’s biodiversity, ZooKeys invites contributions to this memorial issue, covering all subjects falling within the area of systematic zoology. Titled “Systematic Zoology and Biodiversity Science: A tribute to Terry Erwin (1940-2020)”.
In tribute to our beloved friend and founding Editor-in-Chief, Dr Terry
Erwin, who passed away on 11th May 2020, we are planning a special
memorial volume to be published on 11 May 2021, the date Terry left us. Terry
will be remembered by all who knew him for his radiant spirit, charming
enthusiasm for carabid beetles and never-ceasing exploration of the world of
biodiversity!
In recognition of the love and devotion that Terry expressed for study of the World’s biodiversity, ZooKeys invites contributions to this memorial issue, titled “Systematic Zoology and Biodiversity Science: A tribute to Terry Erwin (1940-2020)”, to all subjects falling within the area of systematic zoology. Of special interest are papers recognising Terry’s dedication to collection based research, massive biodiversity surveys and origin of biodiversity hot spot areas. The Special will be edited by John Spence, Achille Casale, Thorsten Assmann, James Liebherr and Lyubomir Penev.
Article processing charges (APCs) will be waived for: (1) Contributions
to systematic biology and diversity of carabid beetles, (2) Contributions from
Terry’s students and (3) Contributions from his colleagues from the Smithsonian
Institution. The APC for articles which do not fall in the above categories
will be discounted at 30%.
The submission deadline is 31st December 2020.
Contributors are also invited to send memories and photos which shall be
published in a special addendum to the volume.
The memorial volume will also include a joint project of Plazi, Pensoft and the Biodiversity Literature Repository aimed at extracting of taxonomic data from Terry Erwin’s publications and making it easily accessible to the scientific community.
A colony of what is apparently a new species of the genus Hipposideros found in an abandoned gold mine in Western Kenya Photo by B. D. Patterson / Field Museum
Newly published findings about the phylogenetics and systematics of some previously known, but also other yet to be identified species of Old World Leaf-nosed bats, provide the first contribution to a recently launched collection of research articles, whose task is to help scientists from across disciplines to better understand potential hosts and vectors of zoonotic diseases, such as the Coronavirus. Bats and pangolins are among the animals already identified to be particularly potent vehicles of life-threatening viruses, including the infamous SARS-CoV-2.
The article, publicly available in the peer-reviewed scholarly journal ZooKeys, also pilots a new generation of Linked Open Data (LOD) publishing practices, invented and implemented to facilitate ongoing scientific collaborations in times of urgency like those we experience today with the COVID-19 pandemic currently ravaging across over 230 countries around the globe.
In their study, an international team of scientists, led by Dr Bruce Patterson, Field Museum‘s MacArthur curator of mammals, point to the existence of numerous, yet to be described species of leaf-nosed bats inhabiting the biodiversity hotspots of East Africa and Southeast Asia. In order to expedite future discoveries about the identity, biology and ecology of those bats, they provide key insights into the genetics and relations within their higher groupings, as well as further information about their geographic distribution.
“Leaf-nosed bats carry coronaviruses–not the strain that’s affecting humans right now, but this is certainly not the last time a virus will be transmitted from a wild mammal to humans. If we have better knowledge of what these bats are, we’ll be better prepared if that happens,”
says Dr Terrence Demos, a post-doctoral researcher in Patterson’s lab and a principal author of the paper.
One of the possibly three new to science bat species, previously referred to as Hipposideros caffer or Sundevall’s leaf-nosed bat Photo by B. D. Patterson / Field Museum
“With COVID-19, we have a virus that’s running amok in the human population. It originated in a horseshoe bat in China. There are 25 or 30 species of horseshoe bats in China, and no one can determine which one was involved. We owe it to ourselves to learn more about them and their relatives,”
comments Patterson.
In order to ensure that scientists from across disciplines, including biologists, but also virologists and epidemiologists, in addition to health and policy officials and decision-makers have the scientific data and evidence at hand, Patterson and his team supplemented their research publication with a particularly valuable appendix table. There, in a conveniently organized table format, everyone can access fundamental raw genetic data about each studied specimen, as well as its precise identification, origin and the natural history collection it is preserved. However, what makes those data particularly useful for researchers looking to make ground-breaking and potentially life-saving discoveries is that all that information is linked to other types of data stored at various databases and repositories contributed by scientists from anywhere in the world.
Furthermore, in this case, those linked and publicly available data or Linked Open Data (LOD) are published in specific code languages, so that they are “understandable” for computers. Thus, when a researcher seeks to access data associated with a particular specimen he/she finds in the table, he/she can immediately access additional data stored at external data repositories by means of a single algorithm. Alternatively, another researcher might want to retrieve all pathogens extracted from tissues from specimens of a specific animal species or from particular populations inhabiting a certain geographical range and so on.
###
The data publication and dissemination approach piloted in this new study was elaborated by the science publisher and technology provider Pensoft and the digitisation company Plazi for the purposes of a special collection of research papers reporting on novel findings concerning the biology of bats and pangolins in the scholarly journal ZooKeys. By targeting the two most likely ‘culprits’ at the roots of the Coronavirus outbreak in 2020: bats and pangolins, the article collection aligns with the agenda of the COVID-19 Joint Task Force, a recent call for contributions made by the Consortium of European Taxonomic Facilities (CETAF), the Distributed System for Scientific Collections (DiSSCo) and the Integrated Digitized Biocollections (iDigBio).
###
Original source:
Patterson BD, Webala PW, Lavery TH, Agwanda BR, Goodman SM, Kerbis Peterhans JC, Demos TC (2020) Evolutionary relationships and population genetics of the Afrotropical leaf-nosed bats (Chiroptera, Hipposideridae). ZooKeys 929: 117-161. https://doi.org/10.3897/zookeys.929.50240
Pensoft’s flagship journal ZooKeys invites free-to-publish research on key biological traits of SARS-like viruses potential hosts and vectors; Plazi harvests and brings together all relevant data from legacy literature to a reliable FAIR-data repository
To bridge the huge knowledge gaps in the understanding of how and which animal species successfully transmit life-threatening diseases to humans, thereby paving the way for global health emergencies, scholarly publisher Pensoft and literature digitisation provider Plazi join efforts, expertise and high-tech infrastructure.
By using the advanced text- and data-mining tools and semantic publishing workflows they have developed, the long-standing partners are to rapidly publish easy-to-access and reusable biodiversity research findings and data, related to hosts or vectors of the SARS-CoV-2 or other coronaviruses, in order to provide the stepping stones needed to manage and prevent similar crises in the future.
Already, there’s plenty of evidence pointing to certain animals, including pangolins, bats, snakes and civets, to be the hosts of viruses like SARS-CoV-2 (coronaviruses), hence, potential triggers of global health crises, such as the currently ravaging Coronavirus pandemic. However, scientific research on what biological and behavioural specifics of those species make them particularly successful vectors of zoonotic diseases is surprisingly scarce. Even worse, the little that science ‘knows’ today is often locked behind paywalls and copyright laws, or simply ‘trapped’ in formats inaccessible to text- and data-mining performed by search algorithms.
This is why Pensoft’s flagship zoological open-access, peer-reviewed scientific journal ZooKeysrecently announced its upcoming, special issue, titled “Biology of pangolins and bats”, to invite research papers on relevant biological traits and behavioural features of bats and pangolins, which are or could be making them efficient vectors of zoonotic diseases. Another open-science innovation champion in the Pensoft’s portfolio, Research Ideas and Outcomes (RIO Journal) launched another free-to-publish collection of early and/or brief outcomes of research devoted to SARS-like viruses.
Due to the expedited peer review and publication processes at ZooKeys, the articles will rapidly be made public and accessible to scientists, decision-makers and other experts, who could then build on the findings and eventually come up with effective measures for the prevention and mitigation of future zoonotic epidemics. To further facilitate the availability of such critical research, ZooKeys is waiving the publication charges for accepted papers.
Meanwhile, the literature digitisation provider Plazi is deploying its text- and data-mining expertise and tools, to locate and acquire publications related to hosts of coronaviruses – such as those expected in the upcoming “Biology of pangolins and bats” special issue in ZooKeys – and deposit them in a newly formed Coronavirus-Host Community, a repository hosted on the Zenodo platform. There, all publications will be granted persistent open access and enhanced with taxonomy-specific data derived from their sources. Contributions to Plazi can be made at various levels: from sending suggestions of articles to be added to the Zotero bibliographic public libraries on virus-hosts associations and hosts’ taxonomy, to helping the conversion of those articles into findable, accessible, interoperable and reusable (FAIR) knowledge.
Pensoft’s and Plazi’s collaboration once again aligns with the efforts of the biodiversity community, after the natural science collections consortium DiSSCo (Distributed System of Scientific Collections) and the Consortium of European Taxonomic Facilities (CETAF), recently announced the COVID-19 Task Force with the aim to create a network of taxonomists, collection curators and other experts from around the globe.