
Bulgaria officially joins the Global Biodiversity Information Facility (GBIF). This major event for Bulgarian science was initiated by a memorandum signed by the Minister of Environment and Water: Manol Genov.
GBIF is an international network and data infrastructure funded by governments around the world that provides international open access to a modern and comprehensive database of all species of living organisms on the planet.
Joining GBIF is an important step for initiatives such as the Bulgarian Barcode of Life (BgBOL), as it will facilitate the integration of genetic data on species diversity into the global scientific community and support the creation of a more accurate and accessible bioinformatic database. This will increase the scientific visibility and relevance of Bulgarian efforts in molecular taxonomy and conservation.

“First of all, I’d like to congratulate all fellow scientists working in the domain of biology and ecology in Bulgaria with this wonderful achievement,” says Prof. Dr. Lyubomir Penev, founder and CEO of the scientific publisher and technology provider Pensoft, as well as a key participant in the talks and preparations for Bulgaria’s joining GBIF. He is also Chair of BgBOL.
“Becoming a full member of GBIF has been a long-anticipated milestone we have discussed and worked on for several years. Coming not long after we initiated the Bulgarian Barcode of Life, the Bulgarian membership in GBIF gives us yet another uncontested evidence that the nation is on the right path to preserving our uniquely rich fauna and flora,” he adds.
Pensoft is looking forward to sharing our know-how with Bulgarian institutions and scientists in order to streamline the visibility and overall efficiency of biodiversity data collected from Bulgaria.
Prof. Lyubomir Penev
“As close partners of GBIF for over 15 years now, Pensoft is looking forward to sharing our know-how with Bulgarian institutions and scientists, so that they can fully utilise the GBIF infrastructure and tools, in order to streamline the visibility and overall efficiency of biodiversity data collected from Bulgaria.”
GBIF is managed by a Secretariat based in Copenhagen and brings together countries and organisations that collaborate through national and institutional coordinators (also called participant nodes). The mechanism provides common standards, good practices and open access tools for institutions around the world to share information on the location and recording of species and specimens. According to GBIF, a total of 107 countries and organisations currently participate in the network, a significant number of which are European.

By joining GBIF, biodiversity data generated in Bulgaria can be streamlined through the network’s infrastructure so that the country does not need to build and maintain its own separate infrastructure, which also saves significant financial resources.
As a full voting member, Bulgaria will ensure that biodiversity data in the country will be shared and accessible through the platform, and will contribute to global knowledge on biodiversity, respectively to the solutions that will promote its conservation and sustainable use.

Improvements in data management by Bulgaria will also contribute to better reporting and fulfilment of obligations to the Convention on Biological Diversity (CBD) as well as to the Intergovernmental Platform on Biodiversity and Ecosystem Services (IPBES). As a member of GBIF, Bulgaria will be able to apply for funding for flagship activities in Bulgarian institutions and neighbouring Balkan countries. This will enable the country to expand its leadership role in the Balkans in biodiversity research and data accumulation.
The partnership between GBIF and Pensoft dates back to 2009 when the global network and the publisher signed their first Memorandum of Understanding intended to solidify their cooperation as leaders in the technological advancement relevant to biodiversity knowledge. Over the next few years, Pensoft integrated its whole biodiversity journal portfolio with the GBIF infrastructure to enable multiple automated workflows, including export of all species occurrence data published in scientific articles straight to the GBIF platform. Most recently, over 20 biodiversity journals powered by Pensoft’s scholarly publishing platform ARPHA launched their own hosted portals on GBIF to make it easier to access and use biodiversity data associated with published research, aligning with principles of Findable, Accessible, Interoperable, and Reusable (FAIR) data.





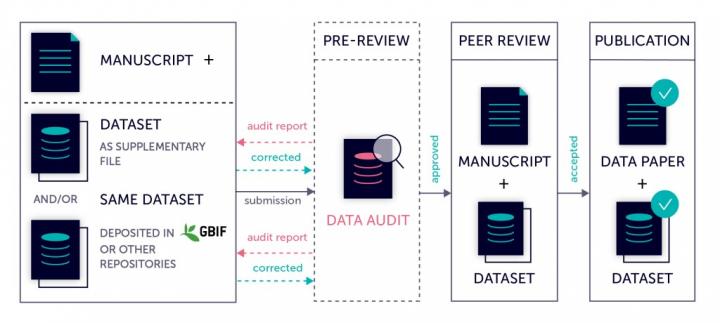








 Another worrying result concerned type specimens – the reference specimens upon which scientific names are based. On a number of occasions, the aggregators were found to have replaced the name of a type specimen with a name tied to an entirely different type specimen.
Another worrying result concerned type specimens – the reference specimens upon which scientific names are based. On a number of occasions, the aggregators were found to have replaced the name of a type specimen with a name tied to an entirely different type specimen.





