Today, Pensoft celebrates one of its most distinguished editors and the world’s leading authority on thrips: Dr. Laurence Mound on the occasion of his 90th birthday.
Born in Willesden, London, on 22 April 1934, Dr. Mound is considered a world authority in the field. Having received his PhD from the University of London, he has been studying the biology and systematics of the order Thysanoptera for more than six decades. His academic recognitions include honorary membership at both the Royal and the Australian Entomological societies.
To date, Dr. Laurence Mound is the most prolific thrips researcher in history and has made monumental contributions to the field as the author of 500 publications, including landmark papers that have since shaped our understanding of the taxonomy and evolution of thrips. He has also published a number of books on thrip identification and control.
Having worked with admirable devotion and persistence to advance the knowledge of thrips on a global scale, Dr. Mound has described over 700 species and 100 genera. His studies have helped with species identifications in important pest groups, which in turn has had a pivotal role in the management of pests and the prevention of the establishment of new pest species.
One of the first-ever entomologists to join the ZooKeys editorial team, Mound has been the journal’s go-to editor for the order Thysanoptera for more than a decade. He oversaw the publication of 18 research papers at ZooKeys. He has also authored 11 articles in the journal, including especially valuable identification keys of different taxa from across the globe. He has also been one of the journal’s active reviewers.
“As a founder of ZooKeys, I’d like to specially congratulate Laurence on his 90th anniversary and personally thank him for his admirable involvement in our beloved journal. I cannot stress it enough how central dedicated and passionate scientists like him are to have a journal establish itself as a top-quality community-led resource of knowledge. As a fellow entomologist, I’d like to wish him health and good fortune for many years to come; and may the devotion and fascination you have invested in the field extend to each and every aspect of your life!”
says Prof. Dr. Lyubomir Penev, founder/CEO of Pensoft and founding editor of ZooKeys.
“As Editor-in-Chief of ZooKeys, I wish you a ‘Happy 90th birthday!’ and thank you for your dedication and support of the journal since its very early days,”
“It was Laurence Mound who suggested my name to replace him as subject editor for Thysanoptera at ZooKeys five years ago. Since then, Laurence has actively continued to be a major contributor of both papers and reviews to the journal. It is an honour to share his friendship and to be able to continually receive his support, encouragement and guidance over the years. I would like to express my gratitude and wish an excellent birthday to this researcher who inspires all of us who study Thysanoptera and entomology in general,”
“We are truly honoured to have been working with Laurence all these years! His passion and dedication have left a permanent mark on the field of entomology. We toast to the future success and happiness of a dear friend, editor, and author. May his work continue to inspire many more generations of entomologists and conservationists,”
Occurrences of myxomycetes in Ukraine from the present study.
Myxomycetes, or slime molds, despite their unassuming name, are fascinating organisms that play a crucial role in forest ecosystems. They live as single-cell amoebae in soil or all sorts of plant debris, where they feed on microscopic bacteria, algae, and fungi. However, when it is time to reproduce and disseminate, these tiny amoebae fuse with each other and form slimy, mobile structures – plasmodia. Plasmodia slowly but actively crawl on the substrate, and eventually transform into fungi-like fruiting bodies filled with spores. Both plasmodia and fruiting bodies are visible with the naked eye and can be easily found e.g. on decaying wood or on the forest floor.
Plasmodium (left) and fruiting bodies (right) of the same species of a slime mold, with a difference of one day.
Myxomycetes are unusual in their life cycle and very eye-catching – if only one knows where to look for them. No wonder that they have attracted the attention of naturalists for centuries. On the territory of Ukraine, observations of myxomycetes first appeared in the first half of 19th century and have been occurring sporadically in the mycological literature ever since.
‘Wasp nest’ slime mold – a common and widespread species of myxomycetes in Ukraine.
However, much valuable information about the myxomycetes of Ukraine before our study was in a “grey zone”. This includes undigitized historical books and articles published in languages such as Polish, French, or German. Furthermore, there is a significant body of proceedings of local conferences, articles in local journals, and reports produced by the employees of protected areas. Yet, many of these publications existed only in print and were written in the Cyrillic alphabet, so they remained difficult to discover, to access, or to work with.
An example of an “invisible” literature source, a page from Maria Zelle “Materials for the myxomycete flora of Ukraine”, 1925.
Within this study, published in Biodiversity Data Journal, we aimed to summarize all published research on myxomycetes of Ukraine, which spans over 150 years, and make the data, as well as the literature behind the data, open and easy to use. For this, we collected and mined 91 publications on this topic, spanning the years 1842 to 2023. As the result, we extracted over 5000 occurrences of myxomycetes that belong to 331 species. The produced datasets we published on GBIF, and the major part of the literature sources on the platform Zenodo.org in open access.
Datasets produced by this study available on GBIF.
Leaders of the BioData project with future Ukrainian mentors.
With this initiative, we aimed to open to the wider audience and digitally preserve some part of the biodiversity data heritage of Ukraine that is currently under threat of destruction.
This study was substantially driven by the BioDATA project, which helped a lot in developing biodiversity data management skills in our team.
Research article:
Yatsiuk I, Leshchenko Y, Viunnyk V, Leontyev DV (2024) The comprehensive checklist of myxomycetes of Ukraine, based on extended occurrence and reference datasets. Biodiversity Data Journal 12: e120891. https://doi.org/10.3897/BDJ.12.e120891
Leiden – also known as the ‘City of Keys’ and the ‘City of Discoveries’ – was aptly chosen to host the third Empowering Biodiversity Research (EBR III) conference. The two-day conference – this time focusing on the utilisation of biodiversity data as a vehicle for biodiversity research to reach to Policy – was held in a no less fitting locality: the Naturalis Biodiversity Center.
On 25th and 26th March 2024, the delegates got the chance to learn more about the latest discoveries, trends and innovations from scientists, as well as various stakeholders, including representatives of policy-making bodies, research institutions and infrastructures. The conference also ran a poster session and a Biodiversity Informatics market, where scientists, research teams, project consortia, and providers of biodiversity research-related services and tools could showcase their work and meet like-minded professionals.
BiCIKL stops at the Naturalis Biodiversity Center
The main outcome of the BiCIKL project: the Biodiversity Knowledge Hub, a one-stop knowledge portal to interlinked and machine-readable FAIR data.
The famous for its bicycle friendliness country also made a suitable stop for BiCIKL (an acronym for the Biodiversity Community Integrated Knowledge Library): a project funded under the European Commission’s Horizon 2020 programme that aimed at triggering a culture change in the way users access, (re)use, publish and share biodiversity data. To do this, the BiCIKL consortium set off on a 3-year journey to build on the existing biodiversity data infrastructures, workflows, standards and the linkages between them.
Many of the people who have been involved in the project over the last three years could be seen all around the beautiful venue. Above all, Naturalis is itself one of the partnering institutions at BiCIKL. Then, on Tuesday, on behalf of the BiCIKL consortium and the project’s coordinator: the scientific publisher and technology innovator: Pensoft, Iva Boyadzhieva presented the work done within the project one month ahead of its official conclusion at the end of April.
As she talked about the way the BiCIKL consortium took to traverse obstacles to wider use and adoption of FAIR and linked biodiversity data, she focused on BiCIKL’s main outcome: the Biodiversity Knowledge Hub (BKH).
Key results from the BiCIKL project three years into its existence presented by Pensoft’s Iva Boyadzhieva at the EBR III conference.
Intended to act as a knowledge broker for users who wish to navigate and access sources of open and FAIR biodiversity data, guidelines, tools and services, in practicality, the BKH is a one-stop portal for understanding the complex but increasingly interconnected landscape of biodiversity research infrastructures in Europe and beyond. It collates information, guidelines, recommendations and best practices in usage of FAIR and linked biodiversity data, as well as a continuously expanded catalogue of compliant relevant services and tools.
At the core of the BKH is the FAIR Data Place (FDP), where users can familiarise themselves with each of the participating biodiversity infrastructures and network organisations, and also learn about the specific services they provide. There, anyone can explore various biodiversity data tools and services by browsing by their main data type, e.g. specimens, sequences, taxon names, literature.
While the project might be coming to an end, she pointed out, the BKH is here to stay as a navigation system in a universe of interconnected biodiversity research infrastructures.
To do this, not only will the partners continue to maintain it, but it will also remain open to any research infrastructure that wishes to feature its own tools and services compliant with the linked and FAIR data requirements set by the BiCIKL consortium.
Indisputably, the ‘hot’ topics at the EBR III were the novel technologies for remote and non-invasive, yet efficient biomonitoring; the utilisation of data and other input sourced by citizen scientists; as well as leveraging different types and sources of biodiversity data, in order to better inform decision-makers, but also future-proof the scientific knowledge we have collected and generated to date.
Project’s coordinator Dr Quentin Groom presents the B-Cubed’s approach towards standardised access to biodiversity data for the use of policy-making at the EBR III conference.
Amongst the other Horizon Europe projects presented at the EBR III conference was B-Cubed (Biodiversity Building Blocks for policy). On Monday, the project’s coordinator Dr Quentin Groom (Meise Botanic Garden) familiarised the conference participants with the project, which aims to standardise access to biodiversity data, in order to empower policymakers to proactively address the impacts of biodiversity change.
You can find more about B-Cubed and Pensoft’s role in it in this blog post.
Dr France Gerard (UK Centre for Ecology & Hydrology) talks about the challenges in using raw data – including those provided by drones – to derive habitat condition metrics.
MAMBO: another Horizon Europe project where Pensoft has been contributing with expertise in science communication, dissemination and exploitation, was also an active participant at the event. An acronym for Modern Approaches to the Monitoring of BiOdiversity, MAMBO had its own session on Tuesday morning, where Dr Vincent Kalkman (Naturalis Biodiversity Center), Dr France Gerard (UK Centre for Ecology & Hydrology) and Prof. Toke Høye (Aarhus University) each took to the stage to demonstrate how modern technology developed within the project is to improve biodiversity and habitat monitoring. Learn more about MAMBO and Pensoft’s involvement in this blog post.
MAMBO’s project coordinator Prof. Toke T. Høye talked about smarter technologies for biodiversity monitoring, including camera traps able to count insects at a particular site.
On the event’s website you can access the MAMBO’s slides presentations by Kalkman, GerardandHøye, as presented at the EBR III conference.
***
The EBR III conference also saw a presentation – albeit remote – from Prof. Dr. Florian Leese (Dean at the University of Duisburg-Essen, Germany, and Editor-in-Chief at the Metabarcoding and Metagenomics journal), where he talked about the promise, but also the challenges for DNA-based methods to empower biodiversity monitoring.
Amongst the key tasks here, he pointed out, are the alignment of DNA-based methods with the Global Biodiversity Framework; central push and funding for standards and guidance; publication of data in portals that adhere to the best data practices and rules; and the mobilisation of existing resources such as the meteorological ones.
He also made a reference to the Forum Paper “Introducing guidelines for publishing DNA-derived occurrence data through biodiversity data platforms” by R. Henrik Nilsson et al., where the international team provided a brief rationale and an overview of guidelines targeting the principles and approaches of exposing DNA-derived occurrence data in the context of broader biodiversity data. In the study, published in the Metabarcoding and Metagenomics journal in 2022, they also introduced a living version of these guidelines, which continues to encourage feedback and interaction as new techniques and best practices emerge.
***
You can find the programme on the conference website and see highlights on the conference hashtag: #EBR2024.
Dikow, an esteemed entomologist specialising in Diptera and cybertaxonomy, is the new Editor-in-Chief of the leading scholarly journal in systematic zoology and biodiversity
Esteemed entomologist specialising in true flies (order Diptera) and cybertaxonomy, Dr Torsten Dikow was appointed as the new Editor-in-Chief of the leading open-access peer-reviewed journal in systematic zoology and biodiversity ZooKeys.
Today, Dikow is a Research Entomologist and Curator of Diptera and Aquatic Insects at the Smithsonian National Museum of Natural History (Washington, DC, USA), where his research interests encompass the diversity and evolutionary history of the superfamily Asiloidea – or asiloid flies – comprising curious insect groups, such as the assassin flies / robber flies and the mydas flies. Amongst an extensive list of research publications, Dikow’s studies on the diversity, biology, distribution and systematics of asiloid flies include the description of 60 species of assassin flies alone, and the redescription of even more through comprehensive taxonomic revisions.
During his years as a postdoc at the Field Museum (Illinois, USA), Dikow was earnestly involved in the broader activities of the Encyclopedia of Life through its Biodiversity Synthesis Center (BioSynC) and the Biodiversity Heritage Library (BHL). There, he would personally establish contacts with smaller natural history museums and scientific societies, and encourage them to grant digitisation permissions to the BHL for in-copyright scientific publications. Dikow is a champion of cybertaxonomic tools and making biodiversity data accessible from both natural history collections and publications. He has been named a Biodiversity Open Data Ambassador by the Global Biodiversity Information Facility (GBIF).
Dikow is no stranger to ZooKeys and other journals published by the open-access scientific publisher and technology provider Pensoft. For the past 10 years, he has been amongst the most active editors and a regular author and reviewer at ZooKeys, Biodiversity Data Journal and African Invertebrates.
“Publishing taxonomic revisions and species descriptions in an open-access, innovative journal to make data digitally accessible is one way we taxonomists can and need to add to the biodiversity knowledge base. ZooKeys has been a journal in support of this goal since day one. I am excited to lend my expertise and enthusiasm to further this goal and continue the development to publish foundational biodiversity research, species discoveries, and much more in the zoological field,”
ZooKeys is a peer-reviewed, open-access, rapidly disseminated journal launched to accelerate research and free information exchange in taxonomy, phylogeny, biogeography and evolution of animals. ZooKeys aims to apply the latest trends and methodologies in publishing and preservation of digital materials to meet the highest possible standards of the cybertaxonomy era.
ZooKeys publishes papers in systematic zoology containing taxonomic/faunistic data on any taxon of any geological age from any part of the world with no limit to manuscript size. To respond to the current trends in linking biodiversity information and synthesising the knowledge through technology advancements, ZooKeys also publishes papers across other taxon-based disciplines, such as ecology, molecular biology, genomics, evolutionary biology, palaeontology, behavioural science, bioinformatics, etc.
Imagine having access to all the two billion biological collections of the world from your desktop! Not only to browse, but to search with artificial intelligence. We recently published a paper where we envisage what might be possible, such as searching all specimen labels for a person’s signature, studying the patterns of butterflies’ wings, or reconstructing a historic expedition.
Numbers of digital images from biodiversity collections are increasing exponentially. Herbariums have led the way with tens of millions of images available, but images of pinned insects will soon overtake plants.
Numbers of accessible images of specimens are increasing exponentially. Plants lead the way, but insects are increasing at the fastest rate. This graph was created from snapshots of the Global Biodiversity Information Facility and is undoubtedly an underestimate of the actual number of specimens for which images exist. See how this was created in Groom et al. (2023).
At one time, if you wanted access to biological collections, you had to travel. Now we are used to visiting collections online, where we can view images of specimens and their details on our desktops. Nevertheless, biological collection images are still dispersed and this limits their effective use, not just for people, but also for computers. One of the promises of making specimens digital is being able to apply machine learning to these images. Yet the real benefits of machine access to specimens can only be realised through massive access to collection images and the ability to apply these techniques to hundreds of collections and millions of specimens.
Imagine examining collections globally for the variation and evolution of wing coloration in butterflies, or studying the size and shape of leaves in research that transverses habitats and gradients of latitude and altitude.
In our paper in Biodiversity Data Journal, we examined some of the numerous uses for machine learning in digital collections. These include an enormous potential to extract traits of organisms, from the size and shape of different organs, to their colours, patterns, and phenology. Imagine examining collections globally for the variation and evolution of wing coloration in butterflies, or studying the size and shape of leaves in research that transverses habitats and gradients of latitude and altitude. We would not only be able to study the intricacies of evolution, but also practical subjects, such as the mechanics of pollination in insects, adaptations to drought in plants, and adaptations to weediness in invasive species.
Machine access to these images will also provide an unparalleled view of the history of the biological sciences, the specimens used to describe species, the evidence for evolution, the people involved and institutions that contributed. Such transparency may reveal some amazing stories of scientific exploration, but will undoubtedly also shed light on some of the less exemplary actions of colonialism. Yet if we are to redress the injustices of the past we need to have a balanced view of collections, and we should do this openly.
Specimen labels provide numerous clues to their history often in the form of stamps and emblems. ABR0000013433048 Meise Botanic Garden (CC-BY-SA 4.0). B USCH0030719, A.C. Moore Herbarium at the University of South Carolina (public domain). CE00809288, Royal Botanic Garden Edinburgh (public domain). D USCH0030719, University of South Carolina (public domain). EE00919066, Royal Botanic Garden Edinburgh (public domain). FBR0000017682725, Meise Botanic Garden (CC-BY-SA 4.0). GP00605317, Museum National d’Histoire Naturelle, Paris (CC-BY 4.0). H LISC036829, Instituto de Investigação Científica Tropical (CC-BY-NC 4.0). l PC0702930, Muséum National d’Histoire Naturelle, Paris (CC-By 4.0). J same specimen as (B). K PC0702930 Muséum National d’Histoire Naturelle, Paris (CC-BY 4.0). L101178648, Missouri Botanical Garden (CC-BY-SA 4.0).
With such unparalleled access to collections, we could travel vicariously to times and places that are hard to reach in any other way. Fieldwork is expensive and time-consuming, and can’t provide the historic perspective of collections, let alone the geographic extent. Furthermore, digital resources have the potential to democratise collections, allowing anyone the opportunity to study these collections irrespective of location.
Is such a vision of integrated digital collections possible? It certainly is! The technologies already exist, not just for machine learning, but also to create the infrastructure to provide access to millions of digital images and their metadata. Initiatives, such as DiSSCo in Europe and iDigBio in the USA are moving in this direction. Yet, we conclude that the main challenge to realising this vision of the future is a sociopolitical one. Can so many institutions and funders work together to pool their resources? Can collections in rich countries share the sovereignty of their collections with the countries where many of the specimens originated?
If you too share the dream, we encourage you to support or contribute to initiatives working in this direction, whether through funding, collaboration, or sharing knowledge. If the full potential of digital collections is to be realised, we need to think big and work together.
Research article:
Groom Q, Dillen M, Addink W, Ariño AHH, Bölling C, Bonnet P, Cecchi L, Ellwood ER, Figueira R, Gagnier P-Y, Grace OM, Güntsch A, Hardy H, Huybrechts P, Hyam R, Joly AAJ, Kommineni VK, Larridon I, Livermore L, Lopes RJ, Meeus S, Miller JA, Milleville K, Panda R, Pignal M, Poelen J, Ristevski B, Robertson T, Rufino AC, Santos J, Schermer M, Scott B, Seltmann KC, Teixeira H, Trekels M, Gaikwad J (2023) Envisaging a global infrastructure to exploit the potential of digitised collections. Biodiversity Data Journal 11: e109439. https://doi.org/10.3897/BDJ.11.e109439
The database is a groundbreaking and pioneering initiative set to revolutionise our understanding of the rich biodiversity of Mindanao, the second-largest island group in the Philippines.
The Philippine Archipelago, with more than 7,100 islands, has one of the highest levels of endemism globally and is a hotspot for biodiversity conservation. Mindanao, the second largest group of islands in the country, is a treasure trove of terrestrial species, boasting one of the highest densities of unique flora and fauna on the planet. However, despite its ecological significance, comprehensive biodiversity records and data for the region have remained inaccessible until now.
The Mindanao Open Biodiversity Information (MOBIOS+) database aims to bridge these critical data gaps by compiling biodiversity information from the 21st century. This monumental undertaking seeks to enhance our understanding of Mindanao’s biodiversity trends, while establishing a database that is openly accessible to researchers and conservationists worldwide.
MOBIOS+ is the first of its kind and, currently, the most comprehensive attempt to create a consolidated database for the biodiversity of Mindanao based on publicly available literature. With a vast collection of biodiversity data, this database will be an invaluable resource to advance regional biodiversity research and analysis.
“It will further facilitate the identification of species and areas that require immediate conservation prioritisation and action, addressing the urgent challenges posed by our rapidly changing planet,” the researchers behind the project write in their data paper, published in the open-access, peer-reviewed Biodiversity Data Journal.
Team members of the MOBIOS+ consortium curating the dataset.
The MOBIOS+ database, available through the Global Biodiversity Information Facility (GBIF) platform, currently comprises an impressive 12,813 georeferenced specimen occurrences representing 1,907 unique taxa. These span across ten animal classes inhabiting terrestrial and freshwater environments within the Mindanao faunal region. The project aims to continuously update the species database, complementing on-ground biodiversity efforts in Mindanao.
Diversity and distribution of species occurrence records across taxonomic groups included in the first version of the MOBIOS+ database. The diversity of species (percentage, %) according to class compared to the overall number of species recorded in the MOBIOS+ database (a); and the total number of species and the number of georeferenced occurrences per animal class (b).
Associate Professor Krizler Tanalgo of the Ecology and Conservation Research Laboratory at the University of Southern Mindanao, the project leader behind MOBIOS+, shared his thoughts on this initiative, saying:
“We aim to democratise biodiversity information, making it readily available to researchers, policymakers, and conservation biologists. By doing so, we hope to facilitate well-informed decisions to address pressing environmental challenges, with a particular focus on the often underrepresented Mindanao region, which tends to receive limited attention in terms of research and funding.”
Distribution of biodiversity records across taxonomic groups from published papers.
“The MOBIOS+ database is not only a testament to the dedication of the scientific community, but also a beacon of hope for the future of biodiversity conservation in Mindanao and beyond. It will support researchers and conservationists in identifying species and areas that require immediate prioritisation and action, safeguarding the unique and fragile ecosystems of this extraordinary region.”
The Biodiversity Community Integrated Knowledge Library (BiCIKL) project, funded by the European Union Horizon 2020 Research and Innovation Action under grant agreement No 101007492, has supported the publication of this work. The work is part of a special collection supported by the project and looking to demonstrate the advantages and novel approaches in accessing and (re-)using linked biodiversity data.
Research article: Tanalgo KC, Dela Cruz KC, Agduma AR, Respicio JMV, Abdullah SS, Alvaro-Ele RJ, Hilario-Husain BA, Manampan-Rubio M, Murray SA, Casim LF, Pantog AMM, Balase SMP, Abdulkasan RMA, Aguirre CAS, Banto NL, Broncate SMM, Dimacaling AD, Fabrero GVN, Lidasan AK, Lingcob AA, Millondaga AM, Panilla KFL, Sinadjan CQM, Unte ND (2023) The MOBIOS+: A FAIR (Findable, Accessible, Interoperable and Reusable) database for Mindanao’s terrestrial biodiversity. Biodiversity Data Journal 11: e110016. https://doi.org/10.3897/BDJ.11.e110016
***
You can find all contributions published in the “Linking FAIR biodiversity data through publications: The BiCIKL approach” article collection in the open-access, peer-reviewed Biodiversity Data Journal on: https://doi.org/10.3897/bdj.coll.209.
As the latest national node to join the International Barcode of Life Consortium (iBOL), its main task is to coordinate, support, and promote DNA barcoding research in Bulgaria.
On 27 September 2023, during a specialised symposium on DNA barcoding at the Bulgarian Academy of Sciences, the Bulgarian Barcode of Life (BgBOL), a Bulgarian DNA barcoding consortium, was founded.
Logo of the Bulgarian Barcode of Life (BgBOL), a Bulgarian DNA barcoding consortium and the latest national node to join the International Barcode of Life Consortium (iBOL).
By becoming the latest national node to join the International Barcode of Life Consortium (iBOL), the main task before BgBOL will be to coordinate, support, and promote DNA barcoding research in Bulgaria, with a primary focus on the study and preservation of the country’s biodiversity.
“The Bulgarian Barcode of Life opens up new horizons and opportunities to study and understand the biodiversity in Bulgaria,”
DNA barcoding is a method to identify individual organisms based on nucleotide sequences captured from short, predefined and standardised segments of DNA.
Dr Georgi Bonchev explains the DNA barcoding method at the specialised symposium held on 27 September 2023 at the Bulgarian Academy of Sciences. Photo by theBulgarian Academy of Sciences.
Prof. Lyubomir Penev joined the symposium with a talk on the publication, dissemination and management of DNA barcoding data. His presentation also touched on the relevant biodiversity data workflows and tools currently in development at Pensoft with the support of the Horizon 2020-funded project BiCIKL. Photo by the Bulgarian Academy of Sciences.
As part of the event, Pensoft’s founder and CEO Prof. Lyubomir Penev led a discussion on the publication, dissemination and management of DNA barcoding data. His presentation also touched on the relevant biodiversity data workflows and tools currently in development at Pensoft with the support of the Horizon 2020-funded project BiCIKL (abbreviation for Biodiversity Community Integrated Knowledge Library).
“I’d like to congratulate everyone involved in the establishment of the Bulgarian Barcode of Life! This is a huge step forward in advancing DNA barcoding research in Bulgaria and, ultimately, the preservation of the country’s amazing biodiversity,”
comments Prof. Lyubomir Penev.
***
About the International Barcode of Life:
The International Barcode of Life Consortium is a research alliance undertaking the largest global biodiversity science initiative: create a digital identification system for life that is accessible to everyone.
iBOL is working to establish an Earth observation system that will discover species, reveal their interactions, and establish biodiversity baselines. The consortium is tracking ecosystems across the planet and exploring symbiomes – the distinct fungal, plant, and animal species associated with host organisms. Our goal is to complete this research and establish baseline data for science and society’s benefit.
Today, 16 September 2023, we are celebrating our tenth anniversary: an important milestone that has prompted us to reflect on the incredible journey thatBiodiversity Data Journal (BDJ) has been through.
From the very beginning, our mission was clear: to revolutionise the way biodiversity data is shared, accessed, and harnessed. This journey has been one of innovation, collaboration, and a relentless commitment to making biodiversity data FAIR – Findable, Accessible, Interoperable, and Reusable.
Over the past 10 years, BDJ, under the auspices of our esteemed publisher Pensoft, has emerged as a trailblazing force in biodiversity science. Our open-access platform has empowered researchers from around the world to publish comprehensive papers that seamlessly blend text with morphological descriptions, occurrences, data tables, and more. This holistic approach has enriched the depth of research articles and contributed to the creation of an interconnected web of biodiversity information.
In addition, by utilising ARPHA Writing Tool and ARPHA Platform as our entirely online manuscript authoring and submission interface, we have simplified the integration of structured data and narrative, reinforcing our commitment to simplifying the research process.
One of our most significant achievements is democratising access to biodiversity data. By dismantling access barriers, we have catalysed the emergence of novel research directions, equipping scientists with the tools to combat critical global challenges such as biodiversity loss, habitat degradation, and climate fluctuations.
We firmly believe that data should be openly accessible to all, fostering collaboration and accelerating scientific discovery. By upholding the FAIR principles, we ensure that the datasets accompanying our articles are not only discoverable and accessible, but also easy to integrate and reusable across diverse fields.
As we reflect on the past decade, we are invigorated by the boundless prospects on the horizon. We will continue working on to steer the global research community towards a future where biodiversity data is open, accessible, and harnessed to tackle global challenges.
Ten years of biodiversity research
To celebrate our anniversary, we have curated some of our most interesting and memorable BDJ studies from the past decade.
Recently, news outlets were quick to cover a new species of ‘snug’ published in our journal.
“Life Beneath the Ice”, a short musical film about light and life beneath the Antarctic sea-ice by Dr. Emiliano Cimoli
We extend our heartfelt gratitude to our authors, reviewers, readers, and the entire biodiversity science community for being integral parts of this transformative journey. Together, we have redefined scientific communication, and we will continue to push the boundaries of knowledge.
Novel nanopublication workflows and templates for associations between organisms, taxa and their environment are the latest outcome of the collaboration between Knowledge Pixels and Pensoft.
Nanopublications complement human-created narratives of scientific knowledge with elementary, machine-actionable, simple and straightforward scientific statements that prompt sharing, finding, accessibility, citability and interoperability.
By making it easier to trace individual findings back to their origin and/or follow-up updates, nanopublications also help to better understand the provenance of scientific data.
With the nanopublication format and workflow, authors make sure that key scientific statements – the ones underpinning their research work – are efficiently communicated in both human-readable and machine-actionable mannerin line with FAIR principles. Thus, their contributions to science are better prepared for a reality driven by AI technology.
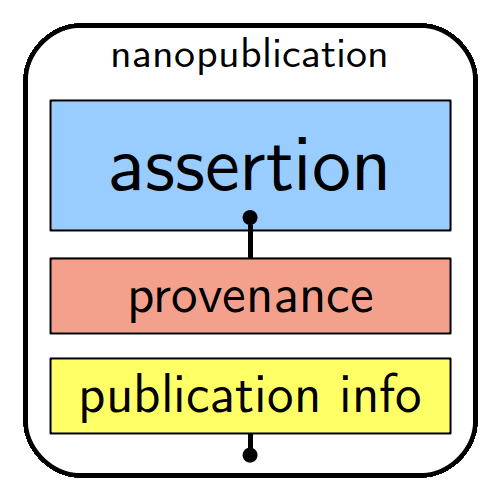
The machine-actionability of nanopublications is a standard due to each assertion comprising a subject, an object and a predicate (type of relation between the subject and the object), complemented by provenance, authorship and publication information. A unique feature here is that each of the elements is linked to an online resource, such as a controlled vocabulary, ontology or standards.
Now, what’s new?
As a result of the partnership between high-tech startup Knowledge Pixels and open-access scholarly publisher and technology provider Pensoft, authors in Biodiversity Data Journal (BDJ) can make use of three types of nanopublications:
Nanopublications associated with a manuscript submitted to BDJ. This workflow lets authors add a Nanopublications section within their manuscript while preparing their submission in the ARPHA Writing Tool (AWT). Basically, authors ‘highlight’ and ‘export’ key points from their papers as nanopublications to further ensure the FAIRness of the most important findings from their publications.
Standalone nanopublication related to any scientific publication, regardless of its author or source. This can be done via the Nanopublications page accessible from the BDJ website. The main advantage of standalone nanopublication is that straightforward scientific statements become available and FAIR early on, and remain ready to be added to a future scholarly paper.
Nanopublications as annotations to existing scientific publications. This feature is available from several journals published on the ARPHA Platform, including BDJ. By attaching an annotation to the entire paper (via the Nanopublication tab) or a text selection (by first adding an inline comment, then exporting it as a nanopublication), a reader can evaluate and record an opinion about any article using a simple template based on the Citation Typing Ontology (CiTO).
Nanopublications for biodiversity data?
At Biodiversity Data Journal (BDJ), authors can now incorporate nanopublications within their manuscripts to future-proofthe most important assertions on biological taxa and organisms or statements about associations of taxa or organisms and their environments.
On top of being shared and archived by means of a traditional research publication in an open-access peer-reviewed journal, scientific statements using the nanopublication format will also remain ‘at the fingertips’ of automated tools that may be the next to come looking for this information, while mining the Web.
Using the nanopublication workflows and templates available at BDJ, biodiversity researchers can share assertions, such as:
So far, the available biodiversity nanopublication templates cover a range of associations, including those between taxa and individual organisms, as well as between those and their environments and nucleotide sequences.
Nanopublication template customised for biodiversity research publications available from Nanodash.
As a result, those easy-to-digest ‘pixels of knowledge’ can capture and disseminate information about single observations, as well as higher taxonomic ranks.
The novel domain-specific publication format was launched as part of thecollaboration betweenKnowledge Pixels – an innovative startup tech company aiming to revolutionise scientific publishing and knowledge sharing and the open-access scholarly publisherPensoft.
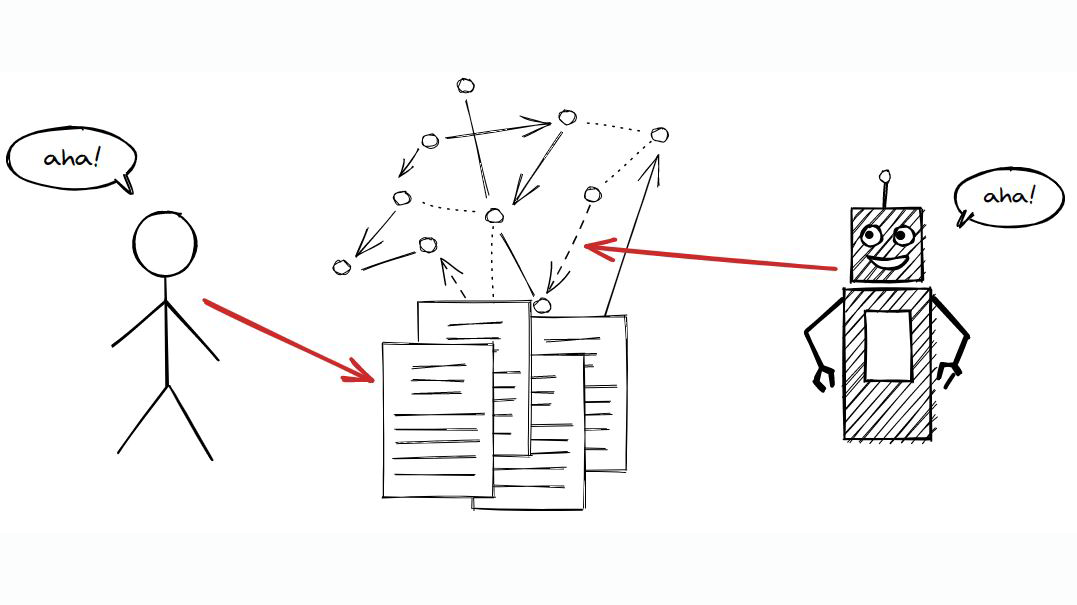
Basically, a nanopublication – unlike a research article – is a tiny snippet of a precise and structured scientific finding (e.g. medication X treats disease Y), which exists as a reusable and cite-able pieces of a growing knowledge graph stored on a decentralised server network in a format that it is readable for humans, but also “understandable” and actionable for computers and their algorithms.
These semantic statements expressed in community-agreed terms, openly available through links to controlled vocabularies, ontologies and standards, are not only freely accessible to everyone in both human-readable and machine-actionable formats, but also easy-to-digest for computer algorithms and AI-powered assistants.
In short, nanopublications allow us to browse and aggregate such findings as part of a complex scientific knowledge graph. Therefore, nanopublications bring us one step closer to the next revolution in scientific publishing, which started with the emergence and increasing adoption of knowledge graphs.
“As pioneers in the semantic open access scientific publishing field for over a decade now, we at Pensoft are deeply engaged with making research work actually available at anyone’s fingertips. What once started as breaking down paywalls to research articles and adding the right hyperlinks in the right places, is time to be built upon,”
By letting computer algorithms access published research findings in a structured format, nanopublications allow for the knowledge snippets that they are intended to communicate to be fully understandable and actionable. With nanopublications, each of those fragmentsof scientific information is interconnected and traceable back to its author(s) and scientific evidence.
A nanopublication is a tiny snippet of a precise and structured scientific finding (e.g. medication X treats disease Y), which exists within a growing knowledge graph stored on a decentralised server network in a format that it is readable for humans, but also “understandable” and actionable for computers and their algorithms. Illustration by Knowledge Pixels.
By building on shared knowledge representation models, these data become Interoperable (as in the Iin FAIR), so that they can be delivered to the right user, at the right time, in the right place , ready to be reused (as per the R in FAIR) in new contexts.
Another issue nanopublications are designed to address is research scrutiny. Today, scientific publications are produced at an unprecedented rate that is unlikely to cease in the years to come, as scholarship embraces the dissemination of early research outputs, including preprints, accepted manuscripts and non-conventional papers.
A network of interlinked nanopublications could also provide a valuable forum for scientists to test, compare, complement and build on each other’s results and approaches to a common scientific problem, while retaining the record of their cooperation each step along the way.
***
We encourage you to try the nanopublications workflow yourself when submitting your next biodiversity paper to Biodiversity Data Journal.
Community feedback on this pilot project and suggestions for additional biodiversity-related nanopublication templates are very welcome!
On the journal website: https://bdj.pensoft.net/, you can find more about the unique features and workflows provided by the Biodiversity Data Journal (BDJ), including innovative research paper formats (e.g. Data Paper, OMICS Data Paper, Software Description, R Package, Species Conservation Profiles, Alien Species Profile), expert-provided data audit for each data paper submission, automated data export and more.
Don’t forget to also sign up for the BDJ newsletter via the Email alert form on the journal’s homepage and follow it on Twitter and Facebook.
Earlier this year, Knowledge Pixels and Pensoft presented several routes for readers and researchers to contribute to research outputs – either produced by themselves or by others – through nanopublications generated through and visualised in Pensoft’s cross-disciplinary Research Ideas and Outcomes (RIO) journal, which uses the same nanopublication workflows.
BKH is a one-stop portal that allows users to access FAIR and interlinked biodiversity data and services in a few clicks. BKH was designed to support a new emerging community of users over time and across the entire biodiversity research cycle providing its services to anybody, anywhere and anytime.
The Knowledge Hub is the main product from our BiCIKL consortium, and we are delighted with the result!
BKH can easily be seen as the beginning of the major shift in the way we search interlinked biodiversity information.”
Biodiversity researchers, research infrastructures and publishers interested in fields ranging from taxonomy to ecology and bioinformatics can now freely use BKH as a compass to navigate the oceans of biodiversity data. BKH will do the linkages.
says Prof. Lyubomir Penev,BiCIKL’s Project coordinator and Founder of Pensoft Publishers.
The BKH is designed to serve a new emerging community of users over time and across the entire biodiversity research cycle.
We have invested our best energies and resources in the development of BKH and the Fair Data Place (FDP), which is the beating heart of the portal,”
BKH has been designed to support a new emerging community of users across the entire biodiversity research cycle.
Its purpose goes beyond the BiCIKL project itself: we are thrilled to say that BKH is meant to stay, aiming to reshape the way biodiversity knowledge is accessed and used.
The BKH outlines how users can navigate and access the linked data, tools and services of the infrastructures cooperating in BiCIKL.
By revealing how they harvest, liberate and reuse data, these increasingly integrated sources enable researchers in the natural sciences to move more seamlessly between specimens and material samples, genomic and metagenomic data, scientific literature, and taxonomic names and units.