The grand opening ceremony of the IUCN World Conservation Congress 2025.
Held from the 9th to 15th of September 2025, the event brought together over 10,000 participants from 189 countries under five central themes: Scaling Up Resilient Conservation Action; Reducing Climate Overshoot Risks; Delivering on Equity; Transitioning to Nature-Positive Economies and Societies; and Disruptive Innovation and Leadership for Conservation.
Represented by Prof Lyubomir Penev (Founder and CEO), Maria Kolesnikova (Marketing and Sales Manager), and Denitsa Peneva (Scientific Illustrator), Pensoft took part in the Congress with a dedicated booth, engaging attendees in conversation about how open science, innovative publishing, and collaborative research can drive conservation.
Denitsa Peneva (left) and Maria Kolesnikova (right) representing Pensoft at the event.
Pensoft’s exhibit placed a strong emphasis on restoration and ecological research, showcasing the publisher’s active role in international initiatives supporting biodiversity recovery and sustainable ecosystem management. Numerous illustrated materials were available for attendees to browse through and take home.
A key feature of the booth was Pensoft’s participation in Horizon 2020 projects such as REST-COAST, which aims to restore and safeguard coastal ecosystems through innovative, large-scale nature-based solutions. Alongside the company’s project involvement, visitors explored Pensoft’s diverse range of open-access journals, including Nature Conservation, One Ecosystem, Estuarine Management and Technologies, NeoBiota, and the newly launched Individual-based Ecology.
A selection of Pensoft’s materials at the congress.
Maja Vasilijevic opening the session, Bridging Science and Policy: European Action for Biodiversity and Climate Goals..
Keynote speaker Musonda Mumba at Advancing Large Scale Restoration Programmes Through Sharing Insights of EU Funded Nature Restoration Projects.
A platform for lasting impact
One of the most anticipated events on the calendar, the IUCN Congress was a fantastic event that looked to the future of collaborative global conservation. For Pensoft, participation in Abu Dhabi reaffirmed its mission to foster open, accessible, and data-driven knowledge to support efforts to protect and restore our planet’s ecosystems.
Letsema Adontsi, Minister of Environment and Forestry, Lesotho.
Visitors at the Pensoft booth.
Taxonomist Korsh Ararat.
Kostas Triantis, author of several articles in Frontiers of Biogeography.
Nature Conservation author Kristijn Swinnen.
Sana Taktak, part of REST-COAST project.
IMA Fungus author Jonathan Cazabonne..
Nature Conservation author Neil D’Cruze.
Elisa Furlan and Elena Alegri from REST-COAST.
Sofia Paredes Maury and Claudia Garcia Barrios from the Guatemalan Association of the Private Nature Reserves.
Maggie Kilian, botanist and Director of Engaging Heritage Consulting.
Guido Berguido, who recently had a new species named ater him in PhytoKeys.
Srijana Joshi Rijal and Bandana Shakya from GBIF Nepal, with Pensoft’s Maria Kolesnikova.
Julia Sigwart, Senckenberg Research Institute. with Prof Lyubomir Penev.
BDJ author Rachel Haderle.
NeoBiota author Ana Nunes.
Pensoft Founder and CEO Prof Lyubomir Penev.
Matthieu Lapinski and Mathilde Michaud from REST-COAST.
The conversations, collaborations, and commitments shared at IUCN 2025 will continue to shape the publisher’s approach to science communication and innovation going forward.
Relive highlights of the conference on Bluesky and LinkedIn using the hashtag #IUCNcongress.
The initiative aims to make it easier to access and use biodiversity data associated with published research, aligning with principles of Findable, Accessible, Interoperable, and Reusable (FAIR) data.
The data portals offer seamless integration of published articles and associated data elements with GBIF-mediated records. Now, researchers, educators, and conservation practitioners can discover and use the extensive species occurrence and other data associated with the papers published in each journal.
A video displaying an interactive map with occurrence data on the BDJ portal.
The collaboration between Pensoft and GBIF was recently piloted with the Biodiversity Data Journal (BDJ). Today, the BDJ hosted portal provides seamless access and exploration for nearly 300,000 occurrences of biological organisms from all over the world that have been extracted from the journal’s all-time publications. In addition, the portal provides direct access to more than 800 datasets published alongside papers in BDJ, as well as to almost 1,000 citations of the journal articles associated with those publications.
“The release of the BDJ portal and subsequent ones planned for other Pensoft journals should inspire other publishers to follow suit in advancing a more interconnected, open and accessible ecosystem for biodiversity research,” said Dr. Vince Smith, Editor-in-Chief of BDJ and head of digital, data and informatics at the Natural History Museum, London.
— GBIF @biodiversity.social/@gbif (@GBIF) March 10, 2025
“The programme will provide a scalable solution for more than thirty of the journals we publish thanks to our partnership with Plazi, and will foster greater connectivity between scientific research and the evidence that supports it,” said Prof. Lyubomir Penev, founder and chief executive officer of Pensoft.
On the new portals, users can search data, refining their queries based on various criteria such as taxonomic classification, and conservation status. They also have access to statistical information about the hosted data.
Together, the hosted portals provide data on almost 325,000 occurrence records, as well as over 1,000 datasets published across the journals.
In our opinion, it is of utmost importance to promptly address the existing issues in the publishing system, where healthy competition can thrive and contribute to a reality safe from potential mono-/oligopolies and corporate capture.
We firmly believe that only an industry that leaves room for variously-scaled pioneers and startups is capable of leading a long-awaited shift to a high-quality, transparent, open and equitable scholarly publishing landscape aligning with the principles of FAIRness.
Yet, we shall acknowledge that the industry has so far failed to eradicate the most fundamental flaw of the past. In the beginning, the main aim of the Open Access (OA) movement was removing the barrier to access to publicly funded scientific knowledge and scrapping costly subscription fees.
Recently, however, the industry’s biggest players merely replaced it with a barrier to publication by introducing costly Article Processing Charges (APCs) and “big deals” signed between top commercial publishers and academic institutions or national library consortia.
As a result, small and middle-sized open-access publishers, which have, ironically, been the ones to lead the change and transition to OA by default and oppose the large commercial publishers’ agenda, were effectively pushed out of the scene. Further, we are currently witnessing a situation where OA funds are mostly going to the ones who used to oppose OA.
So, we strongly supportmeasures that ensure an inclusive and FAIR competition, which could in turn prompt quality, sustainability and reasonable pricing in scholarly publishing. In our opinion, an environment like this would actually foster equality and equity amongst all publishers, either small, large,non-profit, commercial, institutionalor society-based.
One of the main points of the conclusions is a recommendation for a general use of the Diamond OA model, where no charges apply to either researchers or readers. While we fully support the Diamond OA model, we wish to stress on the fact that considerable concerns about the sustainability of existing Diamond OA models remain.
On the one hand, there are OA agreements (also known as read-and-publish, publish-and-read, transformative agreements etc.), typically signed between top publishers and top research institutions/consortia. This OA model is often mistakenly referred to as “Diamond OA”, since authors affiliated with those institutions are not concerned with providing the APC payment – either by paying themselves or applying for funding. Instead, the APCs are paid centrally. Most often, however, journals published by those publishers are still directly charging authors who are not members of the signed institutions with, in our opinion, excessive APCs. Even if those APCs are covered by a signed institution, these are still considerable funds that are being navigated away from actual research work.
On the other hand, there are independent researchers, in addition to smaller or underfunded institutions, typically – yet far from exclusively – located in the developing world, who are effectively being discriminated against.
In conclusion, this type of contracts are shutting away smaller actors from across academia just like they used to be under the subscription-based model. Hereby, we wish to express our full agreement with the Council of the European Union’s conclusion, that “it is essential to avoid situations where researchers are limited in their choice of publication channels due to financial capacities rather than quality criteria”.
There are also several alternative OA models designed to lessen the burden of publication costs for both individual researchers, libraries and journal owners. However, each comes with its own drawbacks. Here – we believe – is where the freedom of choice is perhaps most needed, in order to keep researchers’ and publishers’ best interests at heart.
One of those alternatives is open-source publishing platforms, which – by design – are well-positioned to deliver actual Diamond OA for journals, while maintaining independence from commercial publishers. However, the operational model of this type of publishing and hosting platforms would most often only provide a basic infrastructure for editors to publish and preserve content. As a result, the model might require extra staff and know-how, while remaining prone to human errors. Additionally, a basic technological infrastructure could impede the FAIRness of the published output, which demands advanced and automated workflows to appropriately format, tag semantically and export scientific outputs promptly after publication.
Similarly, large funders and national consortia have put their own admirable efforts to step up and provide another option for authors of research and their institutions. Here, available funds are allocated to in-house Diamond OA publishing platforms that have originally been designed according to the policies and requirements of the respective funding programme or state. However, this type of support – while covering a large group of authors (e.g. based in a certain country, funded under a particular programme, and/or working in a specific research field) – still leaves many behind, including multinational or transdisciplinary teams. Additionally, due to the focus on ‘mass supply’, most of these OA publishing platforms have so far been unable to match their target user base with the appropriate scale of services and support.
What we have devised and developed at Pensoft with the aim to contribute to the pool of available choices is an OA publishing model, whose aim is to balance cost affordability, functionality, reliability, transparency and long-term sustainability.
To do so, we work with journal owners, institutions and societies to create their own business and operational model for their journals that matches two key demands of the community: (1) free to read and free to publish OA model, and, (2) services and infrastructure suited for Diamond OA at a much lower cost, compared to those offered by major commercial publishers.
In our opinion, independent small publishers differentiate from both large commercial publishers and publicly funded providers by relying to a greater extent on innovative technology and close employee collaboration.
As a result, they are capable of delivering significantly more customisable solutions – including complete packages of automated and human-provided services – and, ultimately, achieving considerably lower-cost publishing solutions. Likewise, they might be better suited to provide much more flexible business models, so that libraries and journal owners can easily support (subsets of or all) authors to the best of their capabilities.
While we realise that there is no faultless way to high-quality, transparent, open and equitable scholarly publishing, we are firm supporters of an environment, where healthy competition prompts the continuous invention and evolution of tools and workflows.
Our own motivation to invest in scholarly publishing technology and its continuous refinement and advancement, coupled with a number of in-house and manually provided services, which is reflected in our APC policies, aligns with the Council’s statement that “scientific practices for ensuring reproducibility, transparency, sharing, rigour and collaboration are important means of achieving a publishing system responsive to the challenges of democratic, modern and digitalised societies.”
Our thinking is that – much like in any other industry – what drives innovation and revolutionary technologies is competition. To remain healthy and even self-policing, however, this competition needs to embrace transparency, equity and inclusivity.
Last, but not least, researchers need to have the freedom to choose from plenty of options when deciding where and how to publish their work!
To bridge the gap between authors and their readers or fellow researchers – whether humans or computers – Knowledge Pixels and Pensoft launched workflows to link scientific publications to nanopublications.
A new pilot project by Pensoft and Knowledge Pixels breaks scientific knowledge into FAIR and interlinked snippets of precise information
As you might have already heard, Knowledge Pixels: an innovative startup tech company aiming to revolutionise scientific publishing and knowledge sharing by means of nanopublications – recently launched a pilot project with the similarly pioneering open-science journal Research Ideas and Outcomes (RIO), in a first of several upcoming collaborations between the software developer and the open-access scholarly publisher Pensoft.
“The way how science is performed has dramatically changed with digitalisation, the Internet, and the vast increase in data, but the results are still shared in basically the same form and language as 300 years ago: in narrative text, like a story. These narratives are not precise and not directly interpretable by machines, thereby not FAIR. Even the latest impressive AI tools like ChatGPT can only guess (and sometimes ‘hallucinate’) what the authors meant exactly and how the results compare,”
said Philipp von Essen and Tobias Kuhn, the two founders of Knowledge Pixels in a press announcement.
So, in order to bridge the gap between authors and their readers and fellow researchers – whether humans or computers – the partners launched several workflows to bi-directionally link scientific publications from RIO Journal to nanopublications. We will explain and demonstrate these workflows in a bit.
Now, first, let’s see what nanopublications are and how they contribute to scientific knowledge, researchers and scholarship as a whole.
Basically, a nanopublication – unlike a research article – is just a tiny snippet of a scientific finding (e.g. medication X treats disease Y), which exists as a complete and straightforward piece of information stored on a decentralised server network in a specially structured format, so that it is readable for humans, but also “understandable” and actionable for computers and their algorithms.
A nanopublication may also be an assertion related to an existing research article meant to support, comment, update or complement the reported findings.
In fact, nanopublications as a concept have been with us for quite a while now. Ever since the rise of the Semantic Web, to be exact. At the end of the day, it all boils down to providing easily accessible information that is only a click away from additional useful and relevant content. The thing is, technological advancement has only recently begun to catch up with the concept of nanopublications. Today, we are one step closer to another revolution in scientific publishing, thanks to the emergence and increasing adoption of what we call knowledge graphs.
Second time I hear about nanopublications in biodiversity in 3 days -1st by @rdmpage + now by @Pensoft#ECN2016
“As pioneers in the semantic open access scientific publishing field for over a decade now, at Pensoft we are deeply engaged with making research work actually available at anyone’s fingertips. What once started as breaking down paywalls to research articles and adding the right hyperlinks in the right places, is time to be built upon,”
said Prof. Lyubomir Penev, founder and CEO at Pensoft: the open-access scholarly publisher behind the very first semantically enhanced research article in the biodiversity domain, published back in 2010 in the ZooKeys journal.
Why nanopublications?
Apart from enabling computer algorithms with wholesome access to published research findings, nanopublications allow for the knowledge snippets that they are intended to communicate to be fully understandable and actionable. With nanopublications, each byte of knowledge is interconnected and traceable back to its author(s) and scientific evidence.
Nanopublications present a complete and straightforward piece of information stored on a decentralised server network in a specially structured format, so that it is readable for humans, but also “understandable” and actionable for computers and their algorithms. Illustration by Knowledge Pixels.
By granting computers the capability of exchanging information between users and platforms, these data become Interoperable (as in the Iin FAIR), so that they can be delivered to the right user, at the right time, in the right place.
Another issue nanopublications are designed to address is research scrutiny. Today, scientific publications are produced at an unprecedented rate that is unlikely to cease in the years to come, as scholarship embraces the dissemination of early research outputs, including preprints, accepted manuscripts and non-conventional papers.
By linking assertions to a publication by means of nanopublications allows the original authors and their fellow researchers to keep knowledge up to date as new findings emerge either in support or contradiction to previous information.
A network of interlinked nanopublications could also provide a valuable forum for scientists to test, compare, complement and build on each other’s results and approaches to a common scientific problem, while retaining the record of their cooperation each step along the way.
A scientific issue that would definitely benefit from an additional layer of provenance and, specifically, a workflow allowing for new updates to be linked to previous publications is the biodiversity domain, where species treatments, taxon names, biotic interactions and phylogenies are continuously being updated, reworked and even discarded for good. This is why an upcoming collaboration between Pensoft and Knowledge Pixels will also involve the Biodiversity Data Journal (stay tuned!)
What can you do in RIO?
Now, let’s have a look at the *nano*opportunities already available at RIO Journal.
The integration between RIO and Nanodash: the environment developed by Knowledge Pixels where users edit and publish their nanopublications is available at any article published in the journal.
Add reaction to article
This function allows any reader to evaluate and record an opinion about any article using a simple template. The opinion is posted as a nanopublication displayed on the article page, bearing the timestamp and the name of the creator.
All one needs to do is go to a paper, locate the Nanopubs tab in the menu on the left and click on the Add reaction command to navigate to the Nanodash workspace accessible to anyone registered on ORCiD.
To access the Nanodash workspace, where you can fill in a ready-to-use, partially filled in nanopublication template, simply go to the Nanopubs tab in the menu of any article published in RIO Journal and click Add reaction to this article (see example).
Within the simple Nanodash workspace, the user can provide the text of the nanopublication; define its relation to the linked paper using the Citation Typing Ontology (CiTO); update its provenance and add information (e.g. licence, extra creators) by inserting extra elements.
To do this, the Knowledge Pixels team has created a ready-to-use nanopublication template, where the necessary details for the RIO paper and the author that secure the linkage have already been pre-filled.
Post an inline comment as a nanopublication
Another opportunity for readers and authors to add further meaningful information or feedback to an already published paper is by attaching an inline comment and then exporting it to Nanodash, so that it becomes a nanopublication. To do this, users will simply need to select some text with a left click, type in the comment, and click OK. Now, their input will be available in the Comment tab designed to host simple comments addressing the authors of the publication.
While RIO has long been supporting features allowing for readers to publicly share comments and even CrossRef-registered post-publication peer reviews along the articles, the nanopublications integration adds to the versatile open science-driven arsenal of feedback tools. More precisely, the novel workflow is especially useful for comments that provide a particularly valuable contribution to a research topic.
To make a comment into a nanopublication the user needs to locate the comment in the tab, and click on the Post as Nanopub command to access the Nanodash environment.
Add a nanopublication while writing your manuscript
A functionality available from ARPHA Writing Tool – the online collaborative authoring environment that underpins the manuscript submission process at several journals published by Pensoft, including RIO Journal – allows for researchers to create a list of nanopublications within their manuscripts.
By doing so, not only do authors get to highlight their key statements in a tabular view within a separate pre-designated Nanopublications section, but they also make it easier for reviewers and scientific editors to focus on and evaluate the very foundations of the paper.
By incorporating a machine algorithm-friendly structure for the main findings of their research paper, authors ensure that AI assistants, for example, will be more likely to correctly ‘read’, ‘interpret’ and deliver the knowledge reported in the publication for the next users and their prompts. Furthermore, fellow researchers who might want to cite the paper will also have an easier time citing the specific statement from within the cited source, so that their own readers – be it human, or AI – will make the right links and conclusions.
Within a pre-designated article template at RIO – regardless of the paper type selected – authors have the option to either paste a link to an already available nanopublication or manage their nanopublication via the Nanodash environment by following a link. Customised for the purposes of RIO, the Nanodash workspace will provide them with all the information needed to guide them through the creation and publication of their nanopublications.
Why Research Ideas and Outcomes, a.k.a. RIO Journal?
Why did Knowledge Pixels and Pensoft opt to run their joint pilot at no other journal within the Pensoft portfolio of open-access scientific journals but the Research Ideas and Outcomes (RIO)?
Well, one may argue that there simply was no better choice than an academic outlet that was initially designed to serve as “the open-science journal”: something it has been honourably recognised for by SPARC in 2016, only one year since its launch.
Innovative since day #1, back in 2015, RIO surfaced as an academic outlet to publish a whole lot of article types, reporting on scientific work from across the research process, starting from research ideas, grant proposals and workshop reports.
After all, back in 2015, when it was only a handful of funders who required Data and Software Management Plans to be made openly and publicly, RIO was already providing a platform to publish those as easily citable research outputs, complete with DOI and registration on Crossref. In the spirit of transparency, RIO has always operated an open and public by default peer review policy.
More recently, RIO introduced a novel collections workflow which allows, for example, project coordinators, to provide a one-stop access point for publications and all kinds of valuable outputs resulting from their projects regardless of their publication source.
Bottom line is, RIO has always stood for innovation, transparency, openness and FAIRness in scholarly publishing and communication, so it was indeed the best fit for the nanopublication pilot with Knowledge Pixels.
***
We encourage you to try the nanopublications workflow yourself by going to https://riojournal.com/articles, and posting your own assertion to an article of your choice!
Don’t forget to also sign up for the RIO Journal’s newsletter via the Email alert form on the journal’s website and follow it on Twitter, Facebook, Linkedin and Mastodon.
On this occasion full of sweet memories, we are also inviting you to complete this 3-minute survey. We would deeply appreciate your invaluable feedback!
It was in late 1992 when biologist and ecologist Prof Dr Lyubomir Penev in a collaboration with his friend Prof. Sergei Golovatch established Pensoft: a scholarly publisher with the ambition to contribute to novel and even revolutionary methods in academic publishing by applying its own approach to how science is published, shared and used. Inspired by the world’s best practices in the field, Pensoft would never cease to view the issues and gaps in scholarly publishing in line with its slogan: “by scientists, for scientists”.
As we celebrate the 30th anniversary of Pensoft, we are asking ourselves: What’s a tree without its roots?
That’s why we’ve put up an attractive timeline of Pensoft’s milestones on our website, and complemented it with some key figures, in an attempt to translate those years into numbers. Yet, one can say only that much in figures. Below, we’ll give a bit more context and background about Pensoft’s key milestones.
1994: Pensoft publishes its first book & book series
In time for New Year’s Day in 1994, we published the first book bearing the name of Pensoft. The catalogue of the sheet weaver spiders (Lyniphiidae) of Northern Asia did not only set the beginning of the publishing activities of Pensoft, but also started the extensive Pensoft Series Faunistica, which continues to this day, and currently counts over 120 titles.
2003: Pensoft joins its first EU-funded research project
By 2003, we were well-decided to expand our activities toward participation in collaborative, multinational projects, thereby building on our mission to shed light and communicate the latest scientific work done.
By participating in the FP6-funded project ALARM (abbreviation for Assessing LArge-scale environmental Risks with tested Methods), coordinated by Dr. Joseph Settele from the Helmholtz Centre for Environmental Research (Germany), we would start contributing to the making of science itself in close collaboration with another 67 institutions from across Europe. Our role at ALARM during the five years of the duration of the project was to disseminate and communicate the project outcome. At the end of the project, we also produced the highly appreciated within the community Atlas of Biodiversity Risk.
As for today, 19 years later, Pensoft has taken part in 40 research projects as a provider of various services ranging from data & knowledge management and next-generation open access publishing; to communication, dissemination and (web)design; to stakeholder engagement; consultations; and event and project management.
Our project activities culminated last year, when we became the coordinator of a large and exciting BiCIKL project, dedicated to access to and linking of biodiversity data along the entire data and research life cycle.
2008: Pensoft launches its first scholarly journal to revolutionise & accelerate biodiversity research
Openly accessible and digital-first since the very start, the ZooKeys journal was born on a sunny morning in California during the Entomological Society of America meeting in 2007, when Prof Lyubomir Penev and his renowned colleague Dr Terry Erwin from the Smithsonian Institution agreed over breakfast that zoologists from around the world could indeed use a new-age taxonomic journal. What the community at the time was missing was a scholarly outlet that would not only present a smooth fast track for their research papers, while abiding by the highest and most novel standards in the field, but do so freely and openly to any reader at any time and in any place. Fast forward to 2021, ZooKeys remains the most prolific open-access journal in zoology.
With over 1,100 volumes published to date, ZooKeys is one of our most renowned journals with its own curious and intriguing history. You can find more about it in the celebratory blog post we published on the occasion of the journal’s 1,000th volume in late 2020.
At the time of writing, Pensoft has 21 journals under its own belt, co-publishes another 16, and provides its self-developed journal management platform ARPHA to another 35 scholarly outlets.
2010a: Pensoft launches its first journal publishing platform
By 2010, we realised that the main hurdle holding our progress as a next-age publisher of scientific knowledge was posed by the technology – or lack thereof – underlying the publishing process. We figured that – in our position of users – we were best equipped to figure what exactly this backbone structure should be made of.
This is when we released the publishing platform TRIADA, which was able to support both the editorial and the publication processes at our journals. This was also the point in time when we added “technology provider” to the Pensoft’s byline. Surely, we had so many ideas in our mind and TRIADA was only the beginning!
2010b: In the 50th issue of ZooKeys, Pensoft publishes the first semantically enhanced biodiversity research papers
Later the same year, TRIADA let us write some history. The 50th volume of ZooKeys wasn’t only special because of its number. It contained the first scholarly papers in the study of biodiversity featuring semantic enrichments.
The novelty that keeps a taxon only a click away from a list of related data, including its occurrences, genomics data, treatments, literature etc. is a feature that remains a favourite to our journals’ users to this very day. Unique to date, this workflow is one of the many outcomes of our fantastic long-time collaboration and friendship with Plazi.
2011: Journal of Hymenoptera Research becomes the first society journal to move to Pensoft
Three years after the launch of the very first Pensoft journal, we received a request from the International Society of Hymenopterists who wanted for their own journal: the Journal of Hymenoptera Research to follow the example of ZooKeys and provide to their authors, editors and readers a similar set of services and features designed to streamline biodiversity knowledge in a modern, user-friendly and highly efficient manner.
Ever since, the journal has been co-published by the Society and Pensoft, and enjoyed growing popularity and appeal amongst hymenopterists from around the world.
Impact Factor and CiteScore trend for Journal of Hymenoptera Research since 2015.
2013: Pensoft replaces TRIADA with its own in-house built innovative ARPHA Platform
As we said, TRIADA was merely the crude foundation of what was to become the ARPHA publishing platform: a publishing solution providing a lot more than an end-to-end entirely online environment to support the whole publishing process on both journal and article level.
On top of that, ARPHA’s publishing package includes a variety of automated and manually provided services, web service integrations and highly customisable features. With all of those, we aimed at one thing only: create a comprehensive scholarly publishing solution to our own dearest journals and all their users.
Having just unveiled ARPHA Platform, we were quite confident that we have developed a pretty all-in publishing solution. Our journals would be launched, set up, hosted and upgraded safely under our watchful eye, while authors, editors and reviewers would need to send not a single email or a file outside of our collaborative environment from the moment they submit a manuscript to the moment they see it published, indexed and archived at all relevant databases.
Yet, we could still spot a gap left to bridge. The Pensoft Writing Tool (or what is now known as the ARPHA Writing Tool or AWT) provides a space where researchers can do the authoring itself prior to submitting a manuscript straight to the journal. It all happens within the tool, with co-authors, external collaborators, reviewers and editors all able to contribute to the same manuscript file. Due to the XML technology underlying AWT, various data(sets) and references can be easily imported in a few clicks, while a list of templates and content management features lets researchers spend their time and efforts on their scientific work rather than format requirements.
2015: Pensoft launches the open-science RIO Journal
Six years ago, amid heated discussions over the pros and cons of releasing scientific knowledge freely to all, we felt it’s time to push the boundaries even further.
No wonder that, at the time, a scholarly journal with the aim to bring to light ‘alternative’ research outputs from along the whole research process, such as grant proposals, project and workshop reports, data management plans and research ideas amongst many others, was seen as quite brave and revolutionary. Long story short, a year after its launch, RIO earned the honorary recognition from the Scholarly Publishing and Academic Resources Coalition (SPARC) to be named an Open Science Innovator.
Learn about the key milestones and achievements at RIO Journal to date – in addition to its future goals – in the special blog post and the editorial published on the occasion of the journal’s fifth anniversary.
2016: Pensoft provides ARPHA Platform as a white-label journal publishing solution for the first time
Led by our intrinsic understanding for scholars and smaller publishers, we saw the need of many journals and their owners to simultaneously secure a user-friendly and sustainable publishing solution for their scientific outlets. This is why we decided to also offer our ARPHA Platform as a standalone package of technology, services and features, dissociated with Pensoft as a publisher. This option is particularly useful for university presses, learned societies and institutions who would rather stick to exclusivity when it comes to their journal’s branding and imprint.
Another step forward to encompassing the whole spectrum of research outputs was to take care after conference materials: proceedings and abstracts. Once again, our thinking was that all scientific work and efforts need to be made openly available, accessible, reusable and creditable.
Both ARPHA Conference Abstracts and ARPHA Proceedings allow for organisers to conveniently bring the publications together in a conference-branded collection, thereby providing a one-stop permanent access point to all content submitted and presented at a particular event, alongside associated data, images, videos and multimedia, video recordings of conference talks or graphic files of poster presentations.
Publications at both platforms benefit from all key advantages available to conventional research papers at a Pensoft journal, such as registration at Crossref and individual DOI; publication in PDF, semantically enhanced HTML and data-minable XML formats; indexing and archiving at multiple major databases; science communications services.
2019: Pensoft develops the OpenBiodiv Knowledge Graph
As firm believers in the power and future of linked and FAIR data, at Pensoft we realise there is still a great gap in the way biodiversity data is collated, stored, accessed and made available to researchers and key stakeholders for further reuse.
In fact, this is an area within biodiversity research that is in dire need of a revolutionary mechanism to provide a readily available and convenient hub that allows a researcher to access all related data via multi-directional links interconnecting various and standardised databases, in accordance with the Web 2.0 principles.
As the first step in that direction, in 2019, we launched the OpenBiodiv Knowledge Graph, which began to collate various types of biodiversity data as extracted from semantically enhanced articles published by Pensoft and taxonomic treatments harvested by Plazi.
Since then, the OpenBiodiv Knowledge Graph has evolved into the Open Biodiversity Knowledgement Management System (OBKMS), which also comprises a Linked Open Dataset, an ontology and а website. Our work on the OBKMS continues to this day, fueled by just as much enthusiasm as in those early days in 2019.
By 2020, a number of factors and issues that had long persisted within scholarly publishing and academia had already triggered the emergence of multiple preprint servers. Yet, the onset of the unprecedented for our age COVID-19 pandemic, seemed like the final straw that made everyone realise we needed to start uncovering early scientific work, and we needed to do that fast.
At the time, we had already been considering applying the Pensoft approach to preprints. So, we came up with a solution that could seamlessly blend into our existing infrastructure.
Offered as an opt-in service to journals published on the ARPHA Platform, ARPHA Preprints allows for authors to check a box and post their manuscripts as a preprint as they are filling in the submission form at a participating journal.
Learn more about ARPHA Preprints on the ARPHA blog.
2021a: RIO Journal expands into a project-driven knowledge hub
Ever since its launch, RIO had been devised as the ultimate scholarly venue to share the early, intermediate and final results of a research project. While collections at the journal had already been put in good use, we still had what to add, so that we could provide a one-stop place for consortia to permanently store their outputs and make them easily discoverable and accessible long after their project had concluded.
With the upgraded collections, their owners received the oppotunity to also add various research publications – including scholarly articles published elsewhere, author-formatted documents and preprints. In the former case, the article is visualised within the collection at RIO via a link to its original source, while in the latter, it is submitted and published via ARPHA Preprints.
Over the years, we have been partnering with many like-minded innovators and their institutions from across the natural science community. Surely, we hadn’t successfully developed all those technologies and workflows without their invaluable feedback and collaborations.
In 2021, our shared passion and vision about the future of research data availability and usage culminated in the project BiCIKL (abbreviation for Biodiversity Community Integrated Knowledge Library), which was granted funding by the European Commission and will run until April 2024.
Within BiCIKL, our team of 14 European institutions are deploying and improving our own and partnering infrastructures to bridge gaps between each other’s biodiversity data types and classes with the ultimate goal to provide flawless access to data across all stages of the research cycle. By the end of the project, together we will have created the first-of-its-kind Biodiversity Knowledge Hub, where a researcher will be able to retrieve a full set of linked and open biodiversity data.
Naturally, being a coordinator of such a huge endeavour towards revolutionising biodiversity science is a great honour by itself.
For us, though, this project has a special place in our hearts, as it perfectly resonates with the very reason why we are here: publishing and sharing science in the most efficient and user-friendly manner.
By Mariya Dimitrova, Georgi Zhelezov, Teodor Georgiev and Lyubomir Penev
The use of written language to record new knowledge is one of the advancements of civilisation that has helped us achieve progress. However, in the era of Big Data, the amount of published writing greatly exceeds the physical ability of humans to read and understand all written information.
More than ever, we need computers to help us process and manage written knowledge. Unlike humans, computers are “naturally fluent” in many languages, such as the formats of the Semantic Web. These standards were developed by the World Wide Web Consortium (W3C) to enable computers to understand data published on the Internet. As a result, computers can index web content and gather data and metadata about web resources.
To help manage knowledge in different domains, humans have started to develop ontologies: shared conceptualisations of real-world objects, phenomena and abstract concepts, expressed in machine-readable formats. Such ontologies can provide computers with the necessary basic knowledge, or axioms, to help them understand the definitions and relations between resources on the Web. Ontologies outline data concepts, each with its own unique identifier, definition and human-legible label.
Matching data to its underlying ontological model is called ontology population and involves data handling and parsing that gives it additional context and semantics (meaning). Over the past couple of years, Pensoft has been working on an ontology population tool, the Pensoft Annotator, which matches free text to ontological terms.
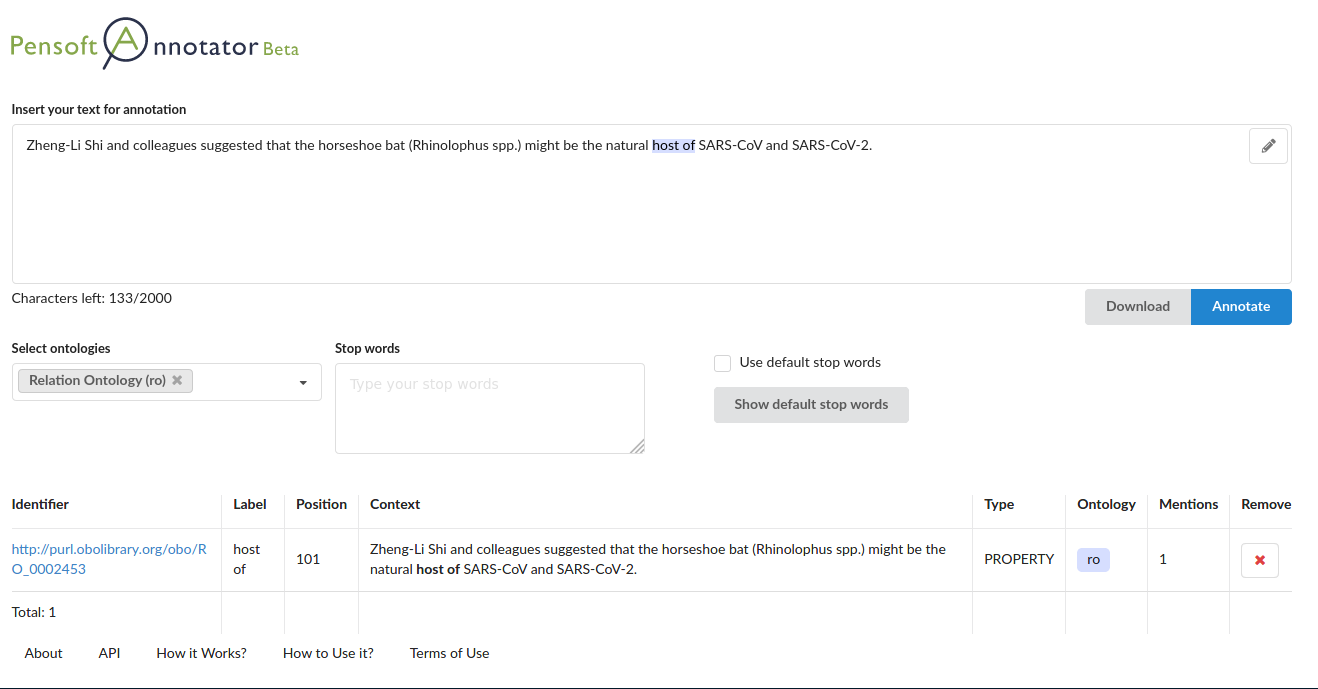
The Pensoft Annotator is a web application, which allows annotation of text input by the user, with any of the available ontologies. Currently, they are the Environment Ontology (ENVO) and the Relation Ontology (RO), but we plan to upload many more. The Annotator can be run with multiple ontologies, and will return a table of matched ontological term identifiers, their labels, as well as the ontology from which they originate (Fig. 1). The results can also be downloaded as a Tab-Separated Value (TSV) file and certain records can be removed from the table of results, if desired. In addition, the Pensoft Annotator allows to exclude certain words (“stopwords”) from the free text matching algorithm. There is a list of default stopwords, common for the English language, such as prepositions and pronouns, but anyone can add new stopwords.
Figure 1. Interface of the Pensoft Annotator application
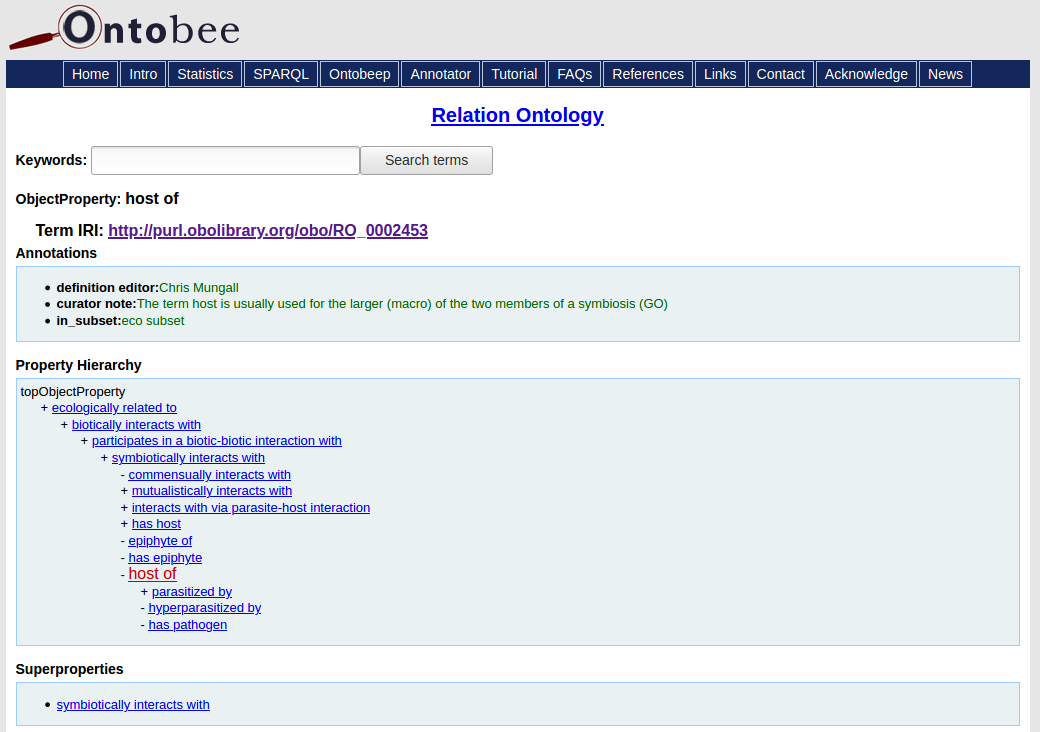
In Figure 1, we have annotated a sentence with the Pensoft Annotator, which yields a single matched term, labeled ‘host of’, from the Relation Ontology (RO). The ontology term identifier is linked to a webpage in Ontobee, which points to additional metadata about the ontology term (Fig. 2).
Figure 2. Web page about ontology term
Such annotation requests can be run to perform text analyses for topic modelling to discover texts which contain host-pathogen interactions. Topic modelling is used to build algorithms for content recommendation (recommender systems) which can be implemented in online news platforms, streaming services, shopping websites and others.
At Pensoft, we use the Pensoft Annotator to enrich biodiversity publications with semantics. We are currently annotating taxonomic treatments with a custom-made ontology based on the Relation Ontology (RO) to discover treatments potentially describing species interactions. You can read more about using the Annotator to detect biotic interactions in this abstract.
The Pensoft Annotator can also be used programmatically through an API, allowing you to integrate the Annotator into your own script. For more information about using the Pensoft Annotator, please check out the documentation.
by Mariya Dimitrova, Jorrit Poelen, Georgi Zhelezov, Teodor Georgiev, Lyubomir Penev
Fig. 1. Pensoft-GloBI workflow for indexing biotic interactions from scholarly literature
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species, etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 2 in Fig. 1).. We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as json to a GitHub repository, from where they could be accessed by GloBI.
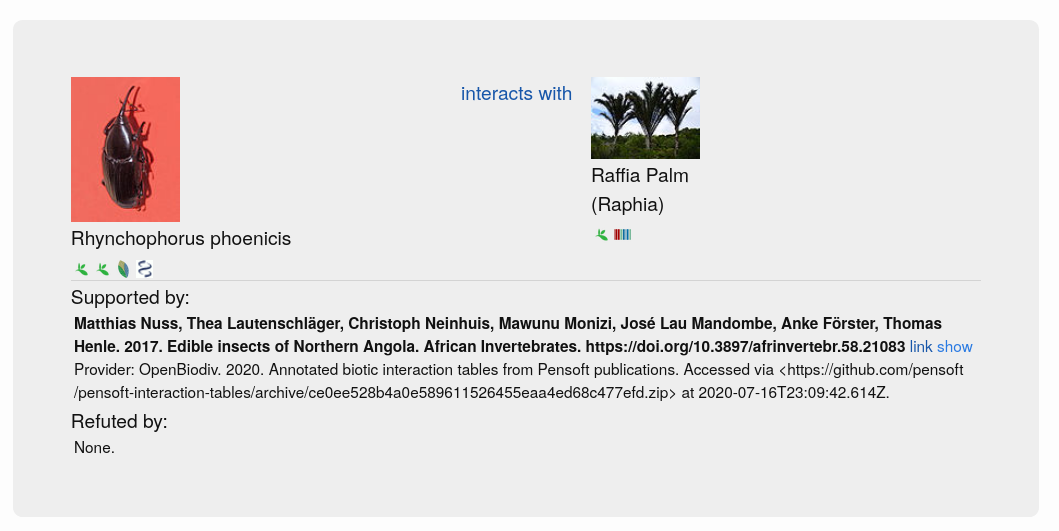
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ (Fig. 2) because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
Fig. 2. Example of a biotic interaction indexed by GloBI.
Examples of species interactions provided by OpenBiodiv and indexed by GloBI are available on GloBI’s website.
In the future we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
Tables published in scholarly literature are a rich source of primary biodiversity data. They are often used for communicating species occurrence data, morphological characteristics of specimens, links of species or specimens to particular genes, ecology data and biotic interactions between species etc. Tables provide a structured format for sharing numerous facts about biodiversity in a concise and clear way.
Inspired by the potential use of semantically-enhanced tables for text and data mining, Pensoft and Global Biotic Interactions (GloBI) developed a workflow for extracting and indexing biotic interactions from tables published in scholarly literature. GloBI is an open infrastructure enabling the discovery and sharing of species interaction data. GloBI ingests and accumulates individual datasets containing biotic interactions and standardises them by mapping them to community-accepted ontologies, vocabularies and taxonomies. Data integrated by GloBI is accessible through an application programming interface (API) and as archives in different formats (e.g. n-quads). GloBI has indexed millions of species interactions from hundreds of existing datasets spanning over a hundred thousand taxa.
The workflow
First, all tables extracted from Pensoft publications and stored in the OpenBiodiv triple store were automatically retrieved (Step 1 in Fig. 1). There were 6,993 tables from 21 different journals. To identify only the tables containing biotic interactions, we used an ontology annotator, currently developed by Pensoft using terms from the OBO Relation Ontology (RO). The Pensoft Annotator analyses free text and finds words and phrases matching ontology term labels.
We used the RO to create a custom ontology, or list of terms, describing different biotic interactions (e.g. ‘host of’, ‘parasite of’, ‘pollinates’) (Step 1 in Fig. 1). We used all subproperties of the RO term labeled ‘biotically interacts with’ and expanded the list of terms with additional word spellings and variations (e.g. ‘hostof’, ‘host’) which were added to the custom ontology as synonyms of already existing terms using the property oboInOwl:hasExactSynonym.
This custom ontology was used to perform annotation of all tables via the Pensoft Annotator (Step 3 in Fig. 1). Tables were split into rows and columns and accompanying table metadata (captions). Each of these elements was then processed through the Pensoft Annotator and if a match from the custom ontology was found, the resulting annotation was written to a MongoDB database, together with the article metadata. The original table in XML format, containing marked-up taxa, was also stored in the records.
Thus, we detected 233 tables which contain biotic interactions, constituting about 3.4% of all examined tables. The scripts used for parsing the tables and annotating them, together with the custom ontology, are open source and available on GitHub. The database records were exported as JSON to a GitHub repository, from where they could be accessed by GloBI.
GloBI processed the tables further, involving the generation of a table citation from the article metadata and the extraction of interactions between species from the table rows (Step 4 in Fig. 1). Table citations were generated by querying the OpenBiodiv database with the DOI of the article containing each table to obtain the author list, article title, journal name and publication year. The extraction of table contents was not a straightforward process because tables do not follow a single schema and can contain both merged rows and columns (signified using the ‘rowspan’ and ‘colspan’ attributes in the XML). GloBI were able to index such tables by duplicating rows and columns where needed to be able to extract the biotic interactions within them. Taxonomic name markup allowed GloBI to identify the taxonomic names of species participating in the interactions. However, the underlying interaction could not be established for each table without introducing false positives due to the complicated table structures which do not specify the directionality of the interaction. Hence, for now, interactions are only of the type ‘biotically interacts with’ because it is a bi-directional one (e.g. ‘Species A interacts with Species B’ is equivalent to ‘Species B interacts with Species A’).
In the future, we plan to expand the capacity of the workflow to recognise interaction types in more detail. This could be implemented by applying part of speech tagging to establish the subject and object of an interaction.
In addition to being accessible via an API and as archives, biotic interactions indexed by GloBI are available as Linked Open Data and can be accessed via a SPARQL endpoint. Hence, we plan on creating a user-friendly service for federated querying of GloBI and OpenBiodiv biodiversity data.
This collaborative project is an example of the benefits of open and FAIR data, enabling the enhancement of biodiversity data through the integration between Pensoft and GloBI. Transformation of knowledge contained in existing scholarly works into giant, searchable knowledge graphs increases the visibility and attributed re-use of scientific publications.
References
Jorrit H. Poelen, James D. Simons and Chris J. Mungall. (2014). Global Biotic Interactions: An open infrastructure to share and analyze species-interaction datasets. Ecological Informatics. https://doi.org/10.1016/j.ecoinf.2014.08.005.
Additional Information
The work has been partially supported by the International Training Network (ITN) IGNITE funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 764840.
Pensoft creates a specialised data paper article type for the omics community within Biodiversity Data Journal to reflect the specific nature of omics data. The scholarly publisher and technology provider established a manuscript template to help standardise the description of such datasets and their most important features.
By Mariya Dimitrova, Raïssa Meyer, Pier Luigi Buttigieg, Lyubomir Penev
Data papers are scientific papers which describe a dataset rather than present and discuss research results. The concept was introduced to the biodiversity community by Chavan and Penev in 2011 as the result of a joint project of GBIF and Pensoft.
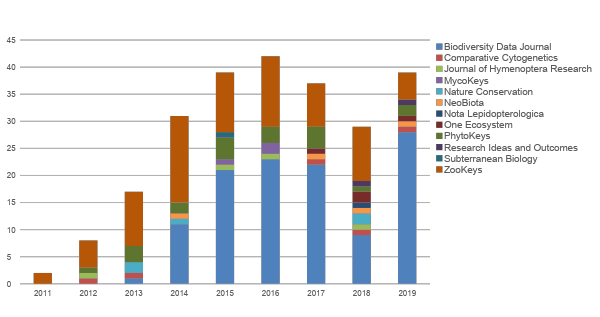
Since then, Pensoft has implemented the data paper in several of its journals (Fig. 1). The recognition gained through data papers is an important incentive for researchers and data managers to author better quality metadata and to make it Findable, Accessible, Interoperable and Re-usable (FAIR). High quality and FAIRness of (meta)data are promoted through providing peer review, data audit, permanent scientific record and citation credit as for any other scholarly publication. One can read more on the different types of data papers and how they help to achieve these goals in the Strategies and guidelines for scholarly publishing of biodiversity data (https://doi.org/10.3897/rio.3.e12431).
Fig. 1 Number of data papers published in Pensoft’s journals since 2011.
The data paper concept was initially based on the standard metadata descriptions, using the Ecological Metadata Language (EML). Apart from distinguishing a specialised place for dataset descriptions by creating a data paper article type, Pensoft has developed multiple workflows for streamlined import of metadata from various repositories and their conversion into data paper a manuscripts in Pensoft’s ARPHA Writing Tool (AWT). You can read more about the EML workflow in this blog post.
Similarly, we decided to create a specialised data paper article type for the omics community within Pensoft’s Biodiversity Data Journal to reflect the specific nature of omics data. We established a manuscript template to help standardise the description of such datasets and their most important features. This initiative was supported in part by the IGNITE project.
How can authors publish omics data papers?
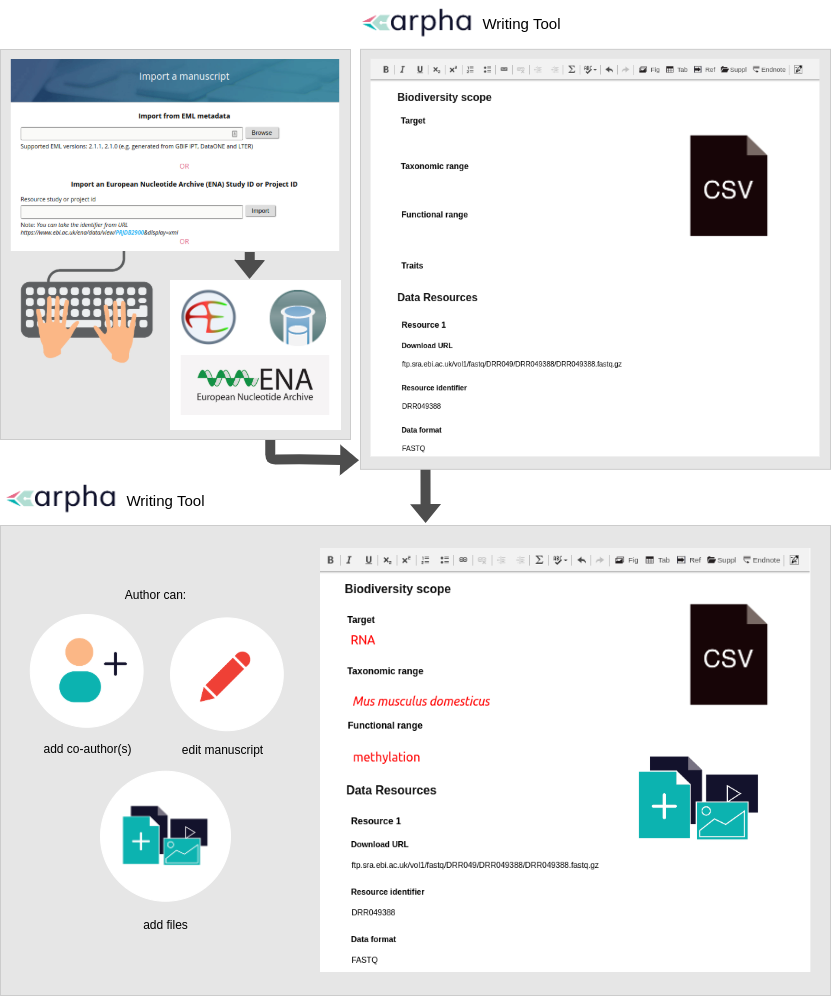
There are two ways to do publish omics data papers – (1) to write a data paper manuscript following the respective template in the ARPHA Writing Tool (AWT) or (2) to convert metadata describing a project or study deposited in EMBL-EBI’s European Nucleotide Archive (ENA) into a manuscript within the AWT.
The first method is straightforward but the second one deserves more attention. We focused on metadata published in ENA, which is part of the International Nucleotide Sequence Database Collaboration (INSDC) and synchronises its records with these of the other two members (DDBJ and NCBI). ENA is linked to the ArrayExpress and BioSamples databases, which describe sequencing experiments and samples, and follow the community-accepted metadata standards MINSEQE and MIxS. To auto populate a manuscript with a click of a button, authors can provide the accession number of the relevant ENA Study of Project and our workflow will automatically retrieve all metadata from ENA, as well as any available ArrayExpress or BioSamples records linked to it (Fig. 2). After that, authors can edit any of the article sections in the manuscript by filling in the relevant template fields or creating new sections, adding text, figures, citations and so on.
An important component of the OMICS data paper manuscript is a supplementary table containing MIxS-compliant metadata imported from BioSamples. When available, BioSamples metadata is automatically converted to a long table format and attached to the manuscript. The authors are not permitted to edit or delete it inside the ARPHA Writing Tool. Instead, if desired, they should correct the associated records in the sourced BioSamples database. We have implemented a feature allowing the automatic re-import of corrected BioSamples records inside the supplementary table. In this way, we ensure data integrity and provide a reliable and trusted source for accessing these metadata.
Fig. 2 Automated generation of omics data paper manuscripts through import and conversion of metadata associated with the Project ID or Study ID at ENA
Here is a step-by-step guide for conversion of ENA metadata into a data paper manuscript:
The author has published a dataset to any of the INSDC databases. They copy its ENA Study or Project accession number.
The author goes to the Biodiversity Data Journal (BDJ) webpage, clicks the “Start a manuscript” buttоn and selects OMICS Data Paper template in the ARPHA Writing Tool (AWT). Alternatively, the author can also start from the AWT website, click “Create a manuscript”, and select “OMICS Data Paper” as the article type, the Biodiversity Data Journal will be automatically marked by the system. The author clicks the “Import a manuscript” button at the bottom of the webpage.
The author pastes the ENA Study or Project accession number inside the relevant text box (“Import an European Nucleotide Archive (ENA) Study ID or Project ID”) and clicks “Import”.
The Project or Study metadata is converted into an OMICS data paper manuscript along with the metadata from ArrayExpress and BioSamples if available. The author can start making changes to the manuscript, invite co-authors and then submit it for technical evaluation, peer review and publication.
Our innovative workflow makes authoring omics data papers much easier and saves authors time and efforts when inserting metadata into the manuscript. It takes advantage of existing links between data repositories to unify biodiversity and omics knowledge into a single narrative. This workflow demonstrates the importance of standardisation and interoperability to integrate data and metadata from different scientific fields.
We have established a special collection for OMICS data papers in the Biodiversity Data Journal. Authors are invited to describe their omics datasets by using the novel streamlined workflow for creating a manuscript at a click of a button from metadata deposited in ENA or by following the template to create their manuscript via the non-automated route.
To stimulate omics data paper publishing, the first 10 papers will be published free of charge. Upon submission of an omics data paper manuscript, do not forget to assign it to the collection Next-generation publishing of omics data.
Pensoft’s journals introduce a standard appendix template for primary biodiversity data to provide direct harvesting and conversion to interlinked FAIR data
by Lyubomir Penev, Mariya Dimitrova, Iva Kostadinova, Teodor Georgiev, Donat Agosti, Jorrit Poelen
Linking open data is far from being a “new” or “innovative” concept ever since Tim Berners-Lee published his “5-Star Rating of Linked Open Data (LOD)” in 2006. The real question is how to implement it in practice, especially when most data are still waiting to be liberated from the narratives of more than 2.5 million scholarly articles published annually? We are still far from the dream world of linked and re-usable open data, not least because the inertia in academic publishing practices appears much stronger than the necessary cultural changes.
Already, there are many exciting tools and projects that harvest data from large corpora of published literature, including historical papers, such as PubMedCentral in biomedicine or Biodiversity Heritage Library in biodiversity science. Yet, finding data elements within the text of these corpora and linking data to external resources, even with the help of AI tools, is still in its infancy and is presently only half way there.
Data should not only be extracted, they should be semantically enriched and linked to both their original resources (e.g. accession numbers for sequences need to be linked to GenBank), but also between each other, as well as with data from other domains. Only then, the data can be made FAIR: Findable, Accessible, Interoperable and Re-usable. There are already research infrastructures, which provide extraction, liberation and semantic enrichment of data from the published narratives, for example, the Biodiversity Literature Repository, established at Zenodo by the digitisation company Plazi and the science publisher and technology provider Pensoft.
Quick access to high-quality Linked Open Data can become vitally important in cases like the current COVID-19 pandemic, when scientists need re-usable data from different research fields to come up with healthcare solutions. To complete the puzzle, they need data related to the taxonomy and biology of viruses, but also data taken from their potential hosts and vectors in the animal world, like bats or pangolins. Therefore, what could publishers do to facilitate the re-usability and interoperability of data they publish?
In a recently published paper by Patterson et al. (2020) on the phylogenetics of Old World Leaf-nosed bats in the journal ZooKeys, the authors and the publisher worked together to present the data on the studied voucher specimens of bats in an Appendix table, where each row represents a set of valuable links between the different data related to a specimen (see Fig. 1).
Fig. 1. Screenshot of the Appendix table with data on 324 specimens of bats (Patterson et al. 2020).
Specimens in natural history collections, for instance, have their so-called human-readable Specimen codes, for example, FMNH 221308 translates to a specimen with Catalogue No 221308, which is preserved in the collection of the Field Museum of Natural History Chicago (FMNH). When added to a collection, such voucher specimens are also assigned Globally Unique Identifiers (GUIDs). For example, the GUID of the above-mentioned specimen looks like this:
25634cae-5a0c-490b-b380-9cabe456316a
and is available from the Global Biodiversity Information Facilities (GBIF) under Original Occurrence ID (Fig. 2), from where computer algorithms can locate various types of data associated with the GUID of a particular specimen, regardless of where these data are stored. Examples for data types and relevant repositories, besides the occurrence record of the specimen available from the GBIF, are specimen data stored at the US-based natural history collection network iDigBio, specimen’s genetic sequences at GenBank, images or sound recordings stored in other third-party databases (e.g. MorphoSource, BioAcustica) and others.
The complex digital environment of various information linked to the globally unique identifier of a physical specimen in a collection together constitutes its “openDS digital specimen” representation, recently formulated within the EU project ICEDIG. Nevertheless, this complex linking could occur more easily and at a modest cost if only the GUIDs were always submitted to the respective data repositories together with the data about that particular specimen. Unfortunately, this is too rarely the case, hence we have to look for other ways to link these fragmented data.
Fig. 2. The representation of the specimen FMNH 221308 on GBIF. The Global Unique Identifier (GUID) of the specimen is shown in the Original Occurrence ID field.
Next to the Specimen code in the table (Fig. 1), there are one or more columns containing accession numbers of different gene sequences from that specimen, linked to their entries in GenBank. There is also a column for the species names associated with the specimens, linked through the Pensoft Taxon Profile (PTP) tool to several trusted international resources, in whose data holdings it appears, such as GBIF, GenBank, Biodiversity Heritage Library, PubMedCentral and many more (see example for the bat species Hipposideros ater). The next column contains the country where the specimen has been collected. The last columns contain the geo-coordinated locations of the collecting spot.
The structure of such a specimen-based table is not fixed and can also have several other data elements, for example, resolvable persistent identifiers for the deposition of MicroCt or other images of the specimen at a repository (e.g. MorphoSource) or of a tissue sample from where a virus has been isolated (see the sample table template below).
So far, so good, but what would the true value of those interlinked data be, besides that a reader could easily click on to a linked data item and see immediately more information about that particular element? What other missinglinks can we include to bring extra value to the data, so that these can be put together and re-used by the research community? Moreover, from where do we take these missing links?
The missing links are present in the table rows!
Firstly, if we open the GBIF record for the specimen in question (FMNH 221308), we see a lot of additional information there (Fig.2), which can be read by humans and retrieved by computers through GBIF’s Application Programming Interface (API). However, the links to the GenBank accession numbers KT583829 of the cyt-b gene sequenced from that specimen are missing, probably because, at the time of deposition of this specimen data in GBIF, its sequences had not yet been submitted to GenBank.
Now, we would probably wish to determine the specimen from which a particular gene has been sequenced and deposited in GenBank and where this specimen is preserved? We can easily click on any accession number in the table but, again, while we find a lot of useful information about the gene, for example, about the methods of sequencing, its taxon name etc., the voucher specimen’s GUID is actually missing (see KT583829 accession number of the specimen FMNH 221308, Fig. 3). How could we then locate the GUID of that specimen and the additional information linked to it? By publishing all this information in the Appendix in the way described here, we can easily locate this missing link between the specimen’s GUID and its sequence, either “by hand” or through API call requests provided by computers.
Fig. 3. GenBank record for the accession number KT583829 of the voucher specimen FMNH 221308. The GUID for the voucher specimen is not present in the record.
While biodiversity researchers are used to working with taxon names, these names are far from being stable entities. Names can either change over time or several different names could be associated with the same “thing” (synonyms) or identical names (homonyms) may be used for different “things”. The biodiversity community needs to resolve this problem by agreeing in the future Catalogue of Life on taxon names that are unambiguously identified with GUIDs through their taxon concepts (the content behind each name, according to a particular author who has already used that name in a publication, for example, Hipposideros vittatus (Peters, 1852) is used in the work of Patterson et al. (2020). Here comes another missing link that the table could provide – the link between the specimen, the taxon name to which it belongs and the taxon concept of that name, according to the article in which this name has been used and published.
Now, once we have listed all available linked information about several specimens belonging to a number of different species in a table, we can continue by adding some other important data, such as the biotic interactions between specimens or species. For example, we can name the table we have already constructed “Source specimens/species” and add to it some more columns under the heading “Target specimens/species”. The linking between the two groups of specimens or species in the extended biotic interaction table can be modelled using the OBO Relations Ontology, especially its list of terms, in a drop-down menu provided in the table template. Observed biotic interactions between specimens or species of the type “pathogen of”, “preys on”, “has vector” etc. can then be easily harvested and recorded in the Global Biotic Interactions database GloBI (see example on interactions between specimens).
As a result, we could have a table like the one below, where column names and data elements linked in the rows follow simple but strict rules:
Appendix A. Specimen data table. Legend: 1 – Two groupings of specimen/species data (Source and Target); 2 – Data type groups – not changeable, linked to the appropriate ontology terms, whenever possible; 3- Column names – not changeable, linked to the appropriate ontology terms, whenever possible; 4- Linked to; 5 – Linked by.
As one can imagine, some columns or cells provided in the table could be empty, as the full completion of this kind of data is rarely possible. For the purposes of a publication, the author can remove all empty columns or add additional columns, for example, for listing more genes or other types of data repository records containing data about a particular specimen. What should not be changed, though, are the column names, because they give the semantic meaning of the data in the table, which allows computers to transform them into machine-readable formats.
At the end of the publishing process, this table is published, not only for humans, but also in a code language, called Extensive Markup Language (XML), which makes the data in the table “understandable” for computers. At the moment of publication, tables published in XML contain not only data, but also information about what these data mean (semantics) and how they could be identified. Thanks to these two features, an algorithm can automatically convert the data into another machine-readable language: Resource Description Framework (RDF), which, in turn, makes the data compatible (interoperable) with other data that can be linked together, using any of the identifiers of the data elements in the table. Such converted data are represented as simple statements, called “RDF triples” and stored in special triple stores, such as OpenBiodiv or Ozymandias, from where knowledge graphs can be created and used further. As an example, one can search and access data associated with a particular specimen, but deposited at various data repositories, for example, other research groups might be interested in having together all pathogens that have been extracted from particular tissues from specimens belonging to a particular host species within a specific geographical location and so on.
Finding and preserving links between the different data elements, for example, between a Specimen, Tissue, Sequence, Taxon name and Location, is by itself a task deserving special attention and investments. How could such bi- and multilateral linking work? Having the table above in place alongside all relevant tools and competences, one can run, for example, the following operations via scripts and APIs:
Locate the GUID for Specimen Code at GBIF (= OccurrenceID)
Lookup sequence data associated with that GUID at GenBank
Represent the link between the GUID and Sequence accession numbers in a series of RDF triples
Link and express in RDF the presentation of the specimen on GBIF with the article where it has been published.
Automatically inform institutions/collections for published materials containing data on their holdings (specimens, authors, publications, links to other research infrastructures, etc.).
Semantic representation of data found in such an Appendix Specimen Data Table allows the utilisation of the Linked Open Data model to map and link several data elements to each other, including the provenance record, that is the original source (article) from where these links have been extracted (Fig. 4).
Fig. 4. Example of a semantic representation between some of the data elements from the Appendix Specimen Data Table. The proposed schema for mapping these elements uses mostly Darwin Core terms to maintain interoperability across different platforms. The link between the specimen GUID, GBIF occurrence, GenBank sequence and scientific name is marked in red.
At the very end, we will be able to construct a new “virtual super-table“ of semantic links between the data elements associated with a specimen, which, in the ideal case, would provide the fully-linked information on data and metadata along and across the lines:
Species A: Specimen <> Tissue sample <> Sequence <> Location <> Taxon name <> Habitat <> Publication source
↑↓
Species B: Specimen <> Tissue sample <> Sequence <> Location <> Taxon name <> Habitat <> Publication source
Retrieving such additional information, for example, about an occurrence from GBIF or sequence information from GenBank through APIs and linking these pieces of information together in one dataset opens new possibilities for data discovery and re-use, as well as to the reproducibility of the research results.
An example for how data from different resources could be put and represented together is the visualisation of the host-parasite interactions between species, such as those between bats and coronaviruses, indexed by the Global Biotic Interactions (GloBI) (Fig. 5). Various other interactions, such as pollination, feeding, co-existence and others, are stored in GloBI’s database which is also available in the form of a Linked Open Dataset, openly accessible through files or through a SPARQL endpoint.
Fig. 5. Visualisation resulting from querying biotic interactions existing between a bat species from order Chiroptera (Plecotus auritus) and bat coronavirus.
The technology of Linked Open Data is already widely used across many fields, so data scientists will not be tremendously impressed by the fact that all of the above is possible. The problem is how to get there. One of the most obvious ways seems to be for publishers to start publishing data in a standard, community-agreed format so that these can easily be handled by machines with little or no human intervention. Will they do that? Some will, but until it becomes routine practice, most of the published data, i.e. high-quality, peer-reviewed data vetted by the act of publishing, will remain hardly accessible, hence unusable.
This pilot was elaborated as a use case published as the first article in a free-to-publish special issue on the biology of bats and pangolins as potential vectors for Coronaviruses in the journal ZooKeys. An additional benefit from the use case is the digitisation and data liberation from many articles on bats contained in the bibliography of the Patterson et al. article by Plazi. The use case is also a contribution to the recently opened COVID-19 Joint Task Force of the Consortium of European Taxonomic Facilities (CETAF), the Distributed System for Scientific Collections (DiSSCo) and the Integrated Digitized Biocollections (iDigBio).
To facilitate the quick adoption of the improved data table standards, Pensoft invites all who would like to test and see how their data are distributed and re-used after publication to submit manuscripts containing specimen data and biotic interaction tables, following the standard described above. The authors would be provided with a template table for completion of all fields relevant to their study while conforming to the standard used by Pensoft.
This initiative was supported in part by the IGNITE project.
Information:
Pensoft Publishers
Field Museum of Natural History Chicago
References:
Patterson BD, Webala PW, Lavery TH, Agwanda BR, Goodman SM, Kerbis Peterhans JC, Demos TC (2020) Evolutionary relationships and population genetics of the Afrotropical leaf-nosed bats (Chiroptera, Hipposideridae). ZooKeys 929: 117-161. https://doi.org/10.3897/zookeys.929.50240
Jorrit H. Poelen, James D. Simons and Chris J. Mungall. (2014). Global Biotic Interactions: An open infrastructure to share and analyze species-interaction datasets. Ecological Informatics. https://doi.org/10.1016/j.ecoinf.2014.08.005.
Hardisty A, Ma K, Nelson G, Fortes J (2019) ‘openDS’ – A New Standard for Digital Specimens and Other Natural Science Digital Object Types. Biodiversity Information Science and Standards 3: e37033. https://doi.org/10.3897/biss.3.37033
While digital curation, publication and dissemination of data have been steadily picking up in recent years in scientific fields ranging from biodiversity and ecology to chemistry and aeronautics, so have imminent concerns about their quality, availability and reusability. What’s the use of any dataset if it isn’t FAIR (i.e. findable, accessible, interoperable and reusable)?
With the all-too-fresh memory of researchers like Elizabeth “Lizzie” Wolkovich who would spend a great deal of time chasing down crucial and impossible-to-replicate data by means of pleading to colleagues (or their successors) via inactive email addresses and literally dusting off card folders and floppy disks, it is easy to imagine that we could be bound to witness history repeating itself once more. At the end of yet another day in today’s “Big Data” world, data loss caused by accidental entry errors or misused data standards seems even more plausible than an outdated contact or a drawer that has suddenly caught fire.
When a 2013 study, which looked into 516 papers from 1991 to 2011, reported that the chances of associated datasets to be available for reuse fell by 17% each year starting from the publication date, it cited issues mostly dealing with the data having simply been lost through the years or stored on currently inaccessible storage media. However, the researcher of today is increasingly logging their data into external repositories, where datasets are swiftly provided with a persistent link via a unique digital object identifier (DOI), while more and more publishers and funders require from authors and project investigators to make their research data openly available upon the publication of the associated paper. Further, we saw the emergence of the Data Paper, a research article type later customised for the needs of various fields, including biodiversity, launched in order to describe datasets and facilitate their reach to a wider audience. So, aren’t data finally here to last?
Today, biodiversity scientists publish and deposit biodiversity data at an unprecedented rate and the pace is only increasing, boosted by the harrowing effects of climate change, species loss, pollution and habitat degradation among others. Meanwhile, the field is yet to adopt universal practices and standards for efficiently linking all those data together – currently available from rather isolated platforms – so that researchers can indeed navigate through the available knowledge and build on it, rather than duplicate unknowingly the efforts of multiple teams from across the globe. Given the limited human capabilities as opposed to the unrestricted amounts of data piling up by the minute, biodiversity science is bound to stagnate if researchers don’t hand over the “data chase” to their computers.
Truth be told, a machine that stumbles across ‘messy’ data – i.e. data whose format and structure have been compromised, so that the dataset is no longer interoperable, i.e. it fails to be retrieved from one application to another – differs little from a researcher whose personal request to a colleague is being ignored. Easily missable details such as line breaks within data items, invalid characters or empty fields could lead to data loss, eventually compromising future research that would otherwise build on those same records. Unfortunately, institutionally available data collections are just as prone to ‘messiness’, as evidenced by data expert and auditor Dr Robert Mesibov.
“Proofreading data takes at least as much time and skill as proofreading text,” says Dr Mesibov. “Just as with text, mistakes easily creep into data files, and the bigger the data file, the more likely it has duplicates, disagreements between data fields, misplaced and truncated (cut-off) data items, and an assortment of formatting errors.”
Snapshot from a data audit report received by University of Cordoba’s Dr Gloria Martínez-Sagarra and Prof Juan Antonio Devesa while preparing their data paper, which describes the herbarium dataset for the vascular plants in COFC.
Similarly to research findings and conclusions which cannot be considered truthful until backed up by substantial evidence, the same evidence (i.e. a dataset) should be of questionable relevance and credibility if its components are not easily retrievable for anyone wishing to follow them up, be it a human researcher or a machine. In order to ensure that their research contribution is made in a responsible fashion in compliance with good scientific practices, scientists should not only care to make their datasets openly available online, but also ensure they are clean and tidy, therefore truly FAIR.
With the kind help of Dr Robert Mesibov, Pensoft has implemented mandatory data audit for all data paper manuscripts submitted to the relevant journals in its exclusively open access portfolio to support responsibility, efficiency and FAIRness in biodiversity science. Learn more about the workflow here. The workflow is illustrated in a case study, describing the experience of University of Cordoba’s Dr Gloria Martínez-Sagarra and Prof Juan Antonio Devesa, while preparing their data paper later published in PhytoKeys. A “Data Quality Checklist and Recommendations” is accessible on the websites of the relevant Pensoft journals, including Biodiversity Data Journal.