As the latest national node to join the International Barcode of Life Consortium (iBOL), its main task is to coordinate, support, and promote DNA barcoding research in Bulgaria.
Logo of the Bulgarian Barcode of Life (BgBOL), a Bulgarian DNA barcoding consortium and the latest national node to join the International Barcode of Life Consortium (iBOL).
By becoming the latest national node to join the International Barcode of Life Consortium (iBOL), the main task before BgBOL will be to coordinate, support, and promote DNA barcoding research in Bulgaria, with a primary focus on the study and preservation of the country’s biodiversity.
“The Bulgarian Barcode of Life opens up new horizons and opportunities to study and understand the biodiversity in Bulgaria,”
DNA barcoding is a method to identify individual organisms based on nucleotide sequences captured from short, predefined and standardised segments of DNA.
Dr Georgi Bonchev explains the DNA barcoding method at the specialised symposium held on 27 September 2023 at the Bulgarian Academy of Sciences. Photo by theBulgarian Academy of Sciences.
Prof. Lyubomir Penev joined the symposium with a talk on the publication, dissemination and management of DNA barcoding data. His presentation also touched on the relevant biodiversity data workflows and tools currently in development at Pensoft with the support of the Horizon 2020-funded project BiCIKL. Photo by the Bulgarian Academy of Sciences.
As part of the event, Pensoft’s founder and CEO Prof. Lyubomir Penev led a discussion on the publication, dissemination and management of DNA barcoding data. His presentation also touched on the relevant biodiversity data workflows and tools currently in development at Pensoft with the support of the Horizon 2020-funded project BiCIKL (abbreviation for Biodiversity Community Integrated Knowledge Library).
“I’d like to congratulate everyone involved in the establishment of the Bulgarian Barcode of Life! This is a huge step forward in advancing DNA barcoding research in Bulgaria and, ultimately, the preservation of the country’s amazing biodiversity,”
The International Barcode of Life Consortium is a research alliance undertaking the largest global biodiversity science initiative: create a digital identification system for life that is accessible to everyone.
iBOL is working to establish an Earth observation system that will discover species, reveal their interactions, and establish biodiversity baselines. The consortium is tracking ecosystems across the planet and exploring symbiomes – the distinct fungal, plant, and animal species associated with host organisms. Our goal is to complete this research and establish baseline data for science and society’s benefit.
Today, 16 September 2023, we are celebrating our tenth anniversary: an important milestone that has prompted us to reflect on the incredible journey thatBiodiversity Data Journal (BDJ) has been through.
From the very beginning, our mission was clear: to revolutionise the way biodiversity data is shared, accessed, and harnessed. This journey has been one of innovation, collaboration, and a relentless commitment to making biodiversity data FAIR – Findable, Accessible, Interoperable, and Reusable.
Over the past 10 years, BDJ, under the auspices of our esteemed publisher Pensoft, has emerged as a trailblazing force in biodiversity science. Our open-access platform has empowered researchers from around the world to publish comprehensive papers that seamlessly blend text with morphological descriptions, occurrences, data tables, and more. This holistic approach has enriched the depth of research articles and contributed to the creation of an interconnected web of biodiversity information.
In addition, by utilising ARPHA Writing Tool and ARPHA Platform as our entirely online manuscript authoring and submission interface, we have simplified the integration of structured data and narrative, reinforcing our commitment to simplifying the research process.
One of our most significant achievements is democratising access to biodiversity data. By dismantling access barriers, we have catalysed the emergence of novel research directions, equipping scientists with the tools to combat critical global challenges such as biodiversity loss, habitat degradation, and climate fluctuations.
We firmly believe that data should be openly accessible to all, fostering collaboration and accelerating scientific discovery. By upholding the FAIR principles, we ensure that the datasets accompanying our articles are not only discoverable and accessible, but also easy to integrate and reusable across diverse fields.
As we reflect on the past decade, we are invigorated by the boundless prospects on the horizon. We will continue working on to steer the global research community towards a future where biodiversity data is open, accessible, and harnessed to tackle global challenges.
Ten years of biodiversity research
To celebrate our anniversary, we have curated some of our most interesting and memorable BDJ studies from the past decade.
Recently, news outlets were quick to cover a new species of ‘snug’ published in our journal.
“Life Beneath the Ice”, a short musical film about light and life beneath the Antarctic sea-ice by Dr. Emiliano Cimoli
We extend our heartfelt gratitude to our authors, reviewers, readers, and the entire biodiversity science community for being integral parts of this transformative journey. Together, we have redefined scientific communication, and we will continue to push the boundaries of knowledge.
Novel nanopublication workflows and templates for associations between organisms, taxa and their environment are the latest outcome of the collaboration between Knowledge Pixels and Pensoft.
Nanopublications complement human-created narratives of scientific knowledge with elementary, machine-actionable, simple and straightforward scientific statements that prompt sharing, finding, accessibility, citability and interoperability.
By making it easier to trace individual findings back to their origin and/or follow-up updates, nanopublications also help to better understand the provenance of scientific data.
With the nanopublication format and workflow, authors make sure that key scientific statements – the ones underpinning their research work – are efficiently communicated in both human-readable and machine-actionable mannerin line with FAIR principles. Thus, their contributions to science are better prepared for a reality driven by AI technology.
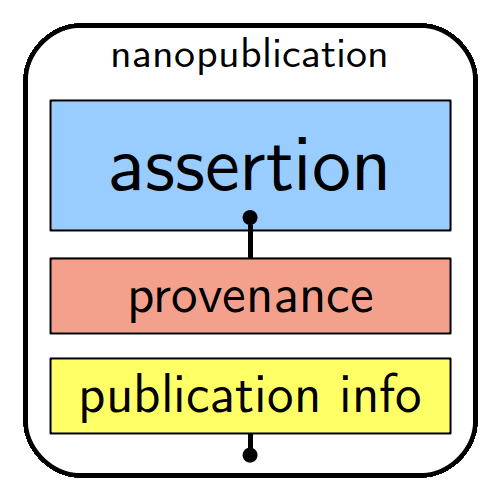
The machine-actionability of nanopublications is a standard due to each assertion comprising a subject, an object and a predicate (type of relation between the subject and the object), complemented by provenance, authorship and publication information. A unique feature here is that each of the elements is linked to an online resource, such as a controlled vocabulary, ontology or standards.
Now, what’s new?
As a result of the partnership between high-tech startup Knowledge Pixels and open-access scholarly publisher and technology provider Pensoft, authors in Biodiversity Data Journal (BDJ) can make use of three types of nanopublications:
Nanopublications associated with a manuscript submitted to BDJ. This workflow lets authors add a Nanopublications section within their manuscript while preparing their submission in the ARPHA Writing Tool (AWT). Basically, authors ‘highlight’ and ‘export’ key points from their papers as nanopublications to further ensure the FAIRness of the most important findings from their publications.
Standalone nanopublication related to any scientific publication, regardless of its author or source. This can be done via the Nanopublications page accessible from the BDJ website. The main advantage of standalone nanopublication is that straightforward scientific statements become available and FAIR early on, and remain ready to be added to a future scholarly paper.
Nanopublications as annotations to existing scientific publications. This feature is available from several journals published on the ARPHA Platform, including BDJ. By attaching an annotation to the entire paper (via the Nanopublication tab) or a text selection (by first adding an inline comment, then exporting it as a nanopublication), a reader can evaluate and record an opinion about any article using a simple template based on the Citation Typing Ontology (CiTO).
Nanopublications for biodiversity data?
At Biodiversity Data Journal (BDJ), authors can now incorporate nanopublications within their manuscripts to future-proofthe most important assertions on biological taxa and organisms or statements about associations of taxa or organisms and their environments.
On top of being shared and archived by means of a traditional research publication in an open-access peer-reviewed journal, scientific statements using the nanopublication format will also remain ‘at the fingertips’ of automated tools that may be the next to come looking for this information, while mining the Web.
Using the nanopublication workflows and templates available at BDJ, biodiversity researchers can share assertions, such as:
So far, the available biodiversity nanopublication templates cover a range of associations, including those between taxa and individual organisms, as well as between those and their environments and nucleotide sequences.
Nanopublication template customised for biodiversity research publications available from Nanodash.
As a result, those easy-to-digest ‘pixels of knowledge’ can capture and disseminate information about single observations, as well as higher taxonomic ranks.
The novel domain-specific publication format was launched as part of thecollaboration betweenKnowledge Pixels – an innovative startup tech company aiming to revolutionise scientific publishing and knowledge sharing and the open-access scholarly publisherPensoft.
Basically, a nanopublication – unlike a research article – is a tiny snippet of a precise and structured scientific finding (e.g. medication X treats disease Y), which exists as a reusable and cite-able pieces of a growing knowledge graph stored on a decentralised server network in a format that it is readable for humans, but also “understandable” and actionable for computers and their algorithms.
These semantic statements expressed in community-agreed terms, openly available through links to controlled vocabularies, ontologies and standards, are not only freely accessible to everyone in both human-readable and machine-actionable formats, but also easy-to-digest for computer algorithms and AI-powered assistants.
In short, nanopublications allow us to browse and aggregate such findings as part of a complex scientific knowledge graph. Therefore, nanopublications bring us one step closer to the next revolution in scientific publishing, which started with the emergence and increasing adoption of knowledge graphs.
“As pioneers in the semantic open access scientific publishing field for over a decade now, we at Pensoft are deeply engaged with making research work actually available at anyone’s fingertips. What once started as breaking down paywalls to research articles and adding the right hyperlinks in the right places, is time to be built upon,”
By letting computer algorithms access published research findings in a structured format, nanopublications allow for the knowledge snippets that they are intended to communicate to be fully understandable and actionable. With nanopublications, each of those fragmentsof scientific information is interconnected and traceable back to its author(s) and scientific evidence.
A nanopublication is a tiny snippet of a precise and structured scientific finding (e.g. medication X treats disease Y), which exists within a growing knowledge graph stored on a decentralised server network in a format that it is readable for humans, but also “understandable” and actionable for computers and their algorithms. Illustration by Knowledge Pixels.
By building on shared knowledge representation models, these data become Interoperable (as in the Iin FAIR), so that they can be delivered to the right user, at the right time, in the right place , ready to be reused (as per the R in FAIR) in new contexts.
Another issue nanopublications are designed to address is research scrutiny. Today, scientific publications are produced at an unprecedented rate that is unlikely to cease in the years to come, as scholarship embraces the dissemination of early research outputs, including preprints, accepted manuscripts and non-conventional papers.
A network of interlinked nanopublications could also provide a valuable forum for scientists to test, compare, complement and build on each other’s results and approaches to a common scientific problem, while retaining the record of their cooperation each step along the way.
***
We encourage you to try the nanopublications workflow yourself when submitting your next biodiversity paper to Biodiversity Data Journal.
Community feedback on this pilot project and suggestions for additional biodiversity-related nanopublication templates are very welcome!
On the journal website: https://bdj.pensoft.net/, you can find more about the unique features and workflows provided by the Biodiversity Data Journal (BDJ), including innovative research paper formats (e.g. Data Paper, OMICS Data Paper, Software Description, R Package, Species Conservation Profiles, Alien Species Profile), expert-provided data audit for each data paper submission, automated data export and more.
Don’t forget to also sign up for the BDJ newsletter via the Email alert form on the journal’s homepage and follow it on Twitter and Facebook.
Earlier this year, Knowledge Pixels and Pensoft presented several routes for readers and researchers to contribute to research outputs – either produced by themselves or by others – through nanopublications generated through and visualised in Pensoft’s cross-disciplinary Research Ideas and Outcomes (RIO) journal, which uses the same nanopublication workflows.
BKH is a one-stop portal that allows users to access FAIR and interlinked biodiversity data and services in a few clicks. BKH was designed to support a new emerging community of users over time and across the entire biodiversity research cycle providing its services to anybody, anywhere and anytime.
The Knowledge Hub is the main product from our BiCIKL consortium, and we are delighted with the result!
BKH can easily be seen as the beginning of the major shift in the way we search interlinked biodiversity information.”
Biodiversity researchers, research infrastructures and publishers interested in fields ranging from taxonomy to ecology and bioinformatics can now freely use BKH as a compass to navigate the oceans of biodiversity data. BKH will do the linkages.
says Prof. Lyubomir Penev,BiCIKL’s Project coordinator and Founder of Pensoft Publishers.
The BKH is designed to serve a new emerging community of users over time and across the entire biodiversity research cycle.
We have invested our best energies and resources in the development of BKH and the Fair Data Place (FDP), which is the beating heart of the portal,”
BKH has been designed to support a new emerging community of users across the entire biodiversity research cycle.
Its purpose goes beyond the BiCIKL project itself: we are thrilled to say that BKH is meant to stay, aiming to reshape the way biodiversity knowledge is accessed and used.
The BKH outlines how users can navigate and access the linked data, tools and services of the infrastructures cooperating in BiCIKL.
By revealing how they harvest, liberate and reuse data, these increasingly integrated sources enable researchers in the natural sciences to move more seamlessly between specimens and material samples, genomic and metagenomic data, scientific literature, and taxonomic names and units.
For an eighth year in a row, all conference abstracts will be submitted to TDWG via the Association’s own journal: Biodiversity Information Science and Standards (BISS Journal), published by Pensoft and powered by the end-to-end publishing platform ARPHA. Using the ‘mini-paper’ format, participants are not only openly and efficiently sharing their work with the world, but they also get to enjoy many features typically exclusive to ‘standard’ research papers, including DOI registration on Crossref, semantic enrichment and structural elements (e.g., tables, figures), all of which are stored as easily exported data.
Apart from an abstract submission portal, BISS Journal also serves as a permanent, openly accessible scholarly source for all contributions concerning the creation, maintenance, and promotion of open community-driven data standards to enable sharing and use of biodiversity data for all.
As in previous years, the abstracts will be published ahead of the event itself to provide the community with a sneak preview of the conference. The 2023 collection of abstracts, will allow readers to explore the abstracts by session (e.g., symposia, posters, contributed presentations, keynotes). Sometime after the conference, check out the media tab on most abstracts for slides presented and a link to session video when it is posted on TDWG’s YouTube channel.
***
Visit the TDWG 2023 conference website for more information about the scientific program, registration, abstract submission and more. Ahead, during and after the conference, join the conversation on Twitter and Mastodon via #tdwg2023.
Welcomed are taxonomic and other biodiversity-related research articles, which demonstrate the advantages and novel approaches in accessing and (re-)using linked biodiversity data
The EU-funded project BiCIKL (Biodiversity Community Integrated Knowledge Library) will support free of charge publications*submitted to the dedicated topical collection: “Linking FAIR biodiversity data through publications: The BiCIKL approach” in the Biodiversity Data Journal, demonstrating advanced publishing methods of linked biodiversity data, so that they can be easily harvested, distributed and re-used to generate new knowledge.
BiCIKL is dedicated to building a new community of key research infrastructures, researchers and citizen scientists by using linked FAIR biodiversity data at all stages of the research lifecycle, from specimens through sequencing, imaging, identification of taxa, etc. to final publication in novel, re-usable, human-readable and machine-interpretable scholarly articles.
Achieving a culture change in how biodiversity data are being identified, linked, integrated and re-used is the mission of the BiCIKL consortium. By doing so, BiCIKL is to help increase the transparency, trustworthiness and efficiency of the entire research ecosystem.
The new article collection welcomes taxonomic and other biodiversity-related research articles, data papers, software descriptions,and methodological/theoretical papers. These should demonstrate the advantages and novel approaches in accessing and (re-)using linked biodiversity data.
To be eligible for the collection, a manuscript must comply with at least two of the conditions listed below. In the submission form, the author needs tospecify the condition(s) applicable to the manuscript. The author should provide the explanation in a cover letter, using the Notes to the editor field.
All submissions must abide by the community-agreed standards for terms, ontologies and vocabularies used in biodiversity informatics.
Conditions for publication in the article collection:
The authors are expected to use explicit Globally Unique Persistent and Resolvable Identifiers (GUPRI) or other persistent identifiers (PIDs), where such are available, for the different types of data they use and/or cite in the manuscripts (specimens IDs, sequence accession numbers, taxon name and taxon treatment IDs, image IDs, etc.)
Global taxon reviews in the form of “cyber-catalogues” are welcome if they contain links of the key data elements (specimens, sequences, taxon treatments, images, literature references, etc.) to their respective records in external repositories. Taxon names in the text should not be hyperlinked. Instead, under each taxon name in the catalogue, the authors should add external links to, for example, Catalogue of Life, nomenclators (e.g. IPNI, MycoBank, Index Fungorum, ZooBank), taxon treatments in Plazi’s TreatmentBank or other relevant trusted resources.
Taxonomic papers (e.g. descriptions of new species or revisions) must contain persistent identifiers for the holotype, paratypes and at least most of the specimens used in the study.
Specimen records that are used for new taxon descriptions or taxonomic revisions and are associated with a particular Barcode Identification Number (BIN) or Species Hypothesis (SH) should be imported directly from BOLD or PlutoF, respectively, via the ARPHA Writing Tool data-import plugin.
More generally, individual specimen records used for various purposes in taxonomic descriptions and inventories should be imported directly into the manuscript from GBIF, iDigBio, or BOLD via the ARPHA Writing Tool data-import plugin.
In-text citations of taxon treatments from Plazi’s TreatmentBank are highly welcome in any taxonomic revision or catalogue. The in-text citations should be hyperlinked to the original treatment data at TreatmentBank.
Hyperlinking other terms of importance in the article text to their original external data sources or external vocabularies is encouraged.
Tables that list gene accession numbers, specimens and taxon names, should conform to the Biodiversity Data Journal’s linked data tables guidelines.
Theoretical or methodological papers on linking FAIR biodiversity data are eligible for the BiCIKL collection if they provide real examples and use cases.
Data papers or software descriptions are eligible if they use linked data from the BiCIKL’s partnering research infrastructures, or describe tools and services that facilitate access to and linking between FAIR biodiversity data.
Articles that contain nanopublications created or added during the authoring process in Biodiversity Data Journal. A nanopublication is a scientifically meaningful assertion about anything that can be uniquely identified and attributed to its author and serve to communicate a single statement, for example biotic relationship between taxa, or habitat preference of a taxon. The in-built workflow ensures the linkage and its persistence, while the information is simultaneously human-readable and machine-interpretable.
Manuscripts that contain or describe any other novel idea or feature related to linked or semantically enhanced biodiversity data will be considered too.
We recommend authors to get acquainted with these two papers before they decide to submit a manuscript to the collection:
Here are several examples of research questions that might be explored using semantically enriched and linked biodiversity data:
(1) How does linking taxon names or Operational Taxonomic Units (OTUs) to related external data (e.g. specimen records, sequences, distributions, ecological & bionomic traits, images) contribute to a better understanding of the functions and regional/local processes within faunas/floras/mycotas or biotic communities?
(2) How could the production and publication of taxon descriptions and inventories – including those based mostly on genomic and barcoding data – be streamlined?
(3) How could general conclusions, assertions and citations in biodiversity articles be expressed in formal, machine-actionable language, either to update prior work or express new facts (e.g. via nanopublications)?
(4) How could research data and narratives be re-used to support more extensive and data-rich studies?
(5) Are there other taxon- or topic-specific research questions that would benefit from richer, semantically enhanced FAIR biodiversity data?
Once published, specimen records data are being exported in Darwin Core Archive to GBIF.
The data and taxon treatments are also exported to several additional data aggregators, such as TreatmentBank, the Biodiversity Literature Repository, and SiBILS amongst others. The full-text articles are also converted to Linked Open Data indexed in the OpenBiodiv Knowledge Graph.
All articles will need to acknowledge the BiCIKL project, Grant No 101007492 in the Acknowledgements section.
* The publication fee (APC) is waived for standard-sized manuscripts (up to 40,000 characters, including spaces) normally charged by BDJ at € 650. Authors of larger manuscripts will need to cover the surplus charge (€10 for each 1,000 characters above 40,000). See more about the APC policy at Biodiversity Data Journal, or contact the journal editorial team at: bdj@pensoft.net.
Follow the BiCIKL Project on Twitter and Facebook.Join the conservation on via #BiCIKL_H2020.
You can also follow Biodiversity Data Journal on Twitter and Facebook.
The publications so far include the grant proposal; conference abstracts, a workshop report, guidelines papers and deliverables submitted to the Commission.
The dynamic open-science project collection of BiCIKL, titled “Towards interlinked FAIR biodiversity knowledge: The BiCIKL perspective” (doi: 10.3897/rio.coll.105), continues to grow, as the project progresses into its third year and its results accumulate ever so exponentially.
Following the publication of three important BiCIKL deliverables: the project’s Data Management Plan, its Visual identity package and a report, describing the newly built workflow and tools for data extraction, conversion and indexing and the user applications from OpenBiodiv, there are currently 30 research outcomes in the BiCIKL collection that have been shared publicly to the world, rather than merely submitted to the European Commission.
Shortly after the BiCIKL project started in 2021, a project-branded collection was launched in the open-science scholarly journal Research Ideas and Outcomes(RIO). There, the partners have been publishing – and thus preserving – conclusive research papers, as well as early and interim scientific outputs.
The publications so far also include the BiCIKL grant proposal, which earned the support of the European Commission in 2021; conference abstracts, submitted by the partners to two consecutive TDWG conferences; a project report that summarises recommendations on interoperability among infrastructures, as concluded from a hackathon organised by BiCIKL; and two Guidelines papers, aiming to trigger a culture change in the way data is shared, used and reused in the biodiversity field.
At the time of writing, the top three of the most read papers in the BiCIKL collection is completed by the grant proposal and the second Guidelines paper, where the partners – based on their extensive and versatile experience – present recommendations about the use of annotations and persistent identifiers in taxonomy and biodiversity publishing.
Access to data and services along the entire data and research life cycle in biodiversity science. The figure was featured in the BiCIKL grant proposal, now made available from the BiCIKL project collection in RIO Journal.
What one might find quite odd when browsing the BiCIKL collection is that each publication is marked with its own publication source, even though all contributions are clearly already accessible from RIO Journal.
This is because one of the unique features of RIOallows for consortia to use their project collection as a one-stop access point for all scientific results, regardless of their publication venue, by means of linking to the original source via metadata. Additionally, projects may also upload their documents in their original format and layout, thanks to the integration between RIO and ARPHA Preprints. This is in fact how BiCIKL chose to share their latest deliverables using the very same files they submitted to the Commission.
“In line with the mission of BiCIKL and our consortium’s dedication to FAIRness in science, we wanted to keep our project’s progress and results fully transparent and easily accessible and reusable to anyone, anywhere,”
explains Prof Lyubomir Penev, BiCIKL’s Project Coordinator and founder and CEO of Pensoft.
“This is why we opted to collate the outcomes of BiCIKL in one place – starting from the grant proposal itself, and then progressively adding workshop reports, recommendations, research papers and what not. By the time BiCIKL concludes, not only will we be ready to refer back to any step along the way that we have just walked together, but also rest assured that what we have achieved and learnt remains at the fingertips of those we have done it for and those who come after them,” he adds.
OpenBiodiv is a biodiversity database containing knowledge extracted from scientific literature, built as an Open Biodiversity Knowledge Management System.
Apart from coordinating the Horizon 2020-funded project BiCIKL, scholarly publisher and technology provider Pensoft has been the engine behind what is likely to be the first production-stage semantic system to run on top of a reasonably-sized biodiversity knowledge graph.
OpenBiodiv is a biodiversity database containing knowledge extracted from scientific literature, built as an Open Biodiversity Knowledge Management System.
As of February 2023, OpenBiodiv contains 36,308 processed articles; 69,596 taxon treatments; 1,131 institutions; 460,475 taxon names; 87,876 sequences; 247,023 bibliographic references; 341,594 author names; and 2,770,357 article sections and subsections.
In fact, OpenBiodiv is a whole ecosystem comprising tools and services that enable biodiversity data to be extracted from the text of biodiversity articles published in data-minable XML format, as in the journals published by Pensoft (e.g. ZooKeys, PhytoKeys, MycoKeys, Biodiversity Data Journal), and other taxonomic treatments – available from Plazi and Plazi’s specialised extraction workflow – into Linked Open Data.
“I believe that OpenBiodiv is a good real-life example of how the outputs and efforts of a research project may and should outlive the duration of the project itself. Something that is – of course – central to our mission at BiCIKL.”
explains Prof Lyubomir Penev, BiCIKL’s Project Coordinator and founder and CEO of Pensoft.
“The basics of what was to become the OpenBiodiv database began to come together back in 2015 within the EU-funded BIG4 PhD project of Victor Senderov, later succeeded by another PhD project by Mariya Dimitrova within IGNITE. It was during those two projects that the backend Ontology-O, the first versions of RDF converters and the basic website functionalities were created,”
he adds.
At the time OpenBiodiv became one of the nine research infrastructures within BiCIKL tasked with the provision of virtual access to open FAIR data, tools and services, it had already evolved into a RDF-based biodiversity knowledge graph, equipped with a fully automated extraction and indexing workflow and user apps.
Currently, Pensoft is working at full speed on new user apps in OpenBiodiv, as the team is continuously bringing into play invaluable feedback and recommendation from end-users and partners at BiCIKL.
As a result, OpenBiodiv is already capable of answering open-ended queries based on the available data. To do this, OpenBiodiv discovers ‘hidden’ links between data classes, i.e. taxon names, taxon treatments, specimens, sequences, persons/authors and collections/institutions.
Thus, the system generates new knowledge about taxa, scientific articles and their subsections, the examined materials and their metadata, localities and sequences, amongst others. Additionally, it is able to return information with a relevant visual representation about any one or a combination of those major data classes within a certain scope and semantic context.
Users can explore the database by either typing in any term (even if misspelt!) in the search engine available from the OpenBiodiv homepage; or integrating an Application Programming Interface (API); as well as by using SPARQL queries.
On the OpenBiodiv website, there is also a list of predefined SPARQL queries, which is continuously being expanded.
“OpenBiodiv is an ambitious project of ours, and it’s surely one close to Pensoft’s heart, given our decades-long dedication to biodiversity science and knowledge sharing. Our previous fruitful partnerships with Plazi, BIG4 and IGNITE, as well as the current exciting and inspirational network of BiCIKL are wonderful examples of how far we can go with the right collaborators,”
In 2018, NHM London’s digitisation team started a project to digitise non-type herbarium material from the legume family. A recent data paper in the Biodiversity Data Journal reports on the outcomes.
You can find the original blog post by the Natural History Museum of London, reposted here with minor edits.
Legumes are a group of plants that include soybeans, peas, chickpeas, peanuts and lentils. They are a significant source of protein, fibre, carbohydrates, and minerals in our diet and some, like the cowpea, are resistant to droughts.
The project’s outcomes were published in a data paper in the Biodiversity Data Journal. Within the project, the digitisation team aimed to collectively digitise non-type herbarium material from the legume family. This includes rosewood trees (Dalbergia), padauk trees (Pterocarpus) and the Phaseolinae subtribe that contains many of the beans cultivated for human and animal food.
Guinea, Ethiopia, Sudan, Kenya, Uganda, Tanzania, Mozambique, Malawi and Madagascar
Asian
Bangladesh, Myanmar, Nepal, New Guinea and India
Southern and Central American
Guatemala, Honduras, El Salvador, Nicaragua, Bolivia, Argentina and Brazil
ODA-listed Countries
The legume groups: Dalbergia, Pterocarpus and Phaseolinae,were chosen for digitisation to support the development of dry beans as a sustainable and resilient crop, and to aid conservation and sustainable use of rosewood and padauk trees. Some of these beans, especially cow pea and pigeon pea, are sustainable and resilient crops, as they can be grown in poor-quality soils and are drought stress resistant. This makes them particularly suitable for agricultural production where the growing of other crops would be difficult.
Digitally discoverable herbarium specimens can provide important information about the distribution of individual species, as well as highlighting which species occur naturally together.
While there have been collaborative efforts between herbaria in the past, these have tended to prioritise digitisation of type specimens: the example specimens for which a species is named.
Types are important to identification, but being individual specimens, they don’t offer insights into species distribution over time. By focusing on the non-types across the world and over the last 200 years, we have released a brand-new resource to the global scientific community.
Searching for beans
This collection was digitised by creating an inventory record for each specimen, attaching images of each herbarium sheet, and then transcribing more data and georeferencing the specimens, providing an accurate locality in space and time for their collection.
We originally had four months and three members of staff to digitise over 11,000 specimens. The Covid-19 lockdown was ironically rather lucky for this project as it enabled us to have more time to transcribe and georeference all of the records.
say the researchers behind the digitisation project.
Map showing breakdown of records by country.
“We were able to assign country-level data to 10,857 out of the total number of 11,222 records. We were also able to transcribe the collectors’ names from the majority of our specimen labels (10,879 out of 11,222). Only 770 out of the 2,226 individuals identified during this project collected their specimens in ODA listed countries. The highest contributors were: Richard Beddome (130 specimens), Charles Clarke (110), Hans Schlieben (98) and Nathaniel Wallich (79). The breakdown of records by ODA country can be seen in the chart below. “
Map showing breakdown of records by country and pie chart showing distribution by ODA listed countries.
From our data, we can see the peak decade of collection was the 1930s, with almost half (4,583 specimens or 49,43%) collected between 1900 and 1950 (Fig. 10).
This peak can be attributed to three of our most prolific collectors: Arthur Kerr, John Gossweiler and Georges Le Testu, all of whom were most active in the 1930s. The oldest specimen (BM013713473) was collected by Mark Catesby (1683-1749) in the Bahamas in 1726.
they explain.
An interesting, but perhaps unsurprising, finding is that our collection is strongly male-dominated.
There are only two women (Caroline Whitefoord and Ynes Mexia) in the list of our top 50 plant collectors and they are not close to the most prolific collectors.
We identified more women in the rest of our records, but their contribution is on average less than 25 specimens per person in the dataset consisting of more than 10,000 specimens. In contrast, the top five male collectors contributed 10% of our collection.
they continued
Releasing Rosewoods
Both the Pterocarpus and Dalbergia genera include species that are used as expensive good quality timber that is prone to illegal logging. Many species such as Pterocarpus tinctorius are also listed on the International Union for Conservation of Nature (IUCN) Red List of Threatened Species. By releasing this new resource of information on all these plants from three of the biggest herbaria in the world, we can share this datа with the people who are taking care of biodiversity in these countries. The data can be used to identify hotspots, where the tree is naturally growing and protect these areas. These data would also allow much closer attention to be paid to areas that could be targets for illegal logging activity.
Pterocarpus tinctorius is a species of padauk tree that is listed as endangered on the IUCN Red List.
Cowpea (Vigna unguiculata) is a food and animal feed crop grown in the semi-arid tropics.
The ODA-listed countries are economically impoverished and disproportionately prone to be disadvantaged with the changing climate whether from flood or drought or increase in temperature.
Using data to identify good, nutritious plant species that can be grown in such conditions can therefore benefit local communities, potentially reducing dependence on imports, aid and on less resilient crops.
the team adds in conclusion.
***
This dataset is now openly available on the Museum’s Data Portal and a data paper about this work has been released in the Biodiversity Data Journal.
***
Stay in touch with the Digitisation team by following us on Instagram and Twitter.
Don’t forget to also follow the Biodiversity Data Journal on Twitter and Facebook.
Key figures from Naturalis Biodiversity Center, Plazi and Pensoft were amongst the first to sign the Declaration at the closing session of the First International Conference on FAIR Digital Objects (FDO2022)
Several of the BiCIKL partners signed the Leiden Declaration on FAIR Digital Objects, thereby committing to “a new environment that works as a truly meaningful data space,” as framed by the organisers of the conference, whose first instalment turned out to be the perfect occasion for the formal publication of the pact.
The conference brought together key international technical, scientific, industry and science-policy stakeholders with the aim to boost the development and implementation of FAIR Digital Objects (FDOs) worldwide. It was organised by the FDO Forum, an initiative supported by major global initiatives and by a variety of regional and national initiatives with the shared goal to achieve a better coherence amongst the increasing number of initiatives working on FDO-based designs and implementations.
By joining the Declaration’s signees, the BiCIKL partners formally committed to:
Support the FAIR guiding principles to be applied (ultimately) to each digital object in a web of FAIR data and services;
Support open standards and protocols;
Support data and services to be as open as possible, and only as restricted as necessary;
Support distributed solutions where useful to achieve robustness and scalability, but recognise the need for centralised approaches where necessary;
Support the restriction of standards and protocols to the absolute minimum;
Support freedom to operate wherever possible;
Help to avoid monopolies and provider lock-in wherever possible.
During the event, Plazi and Pensoft held a presentation demonstrating how their Biodiversity Literature Repository turns taxonomic treatments ‘locked’ in legacy scientific literature into FAIR Digital Objects. As a result of the collaboration between Plazi and Pensoft – a partnership long-preceding their involvement in BiCIKL – this workflow has also been adapted to modern-day publishing, in order to FAIRify data as soon as it is published.
A slide from the Plazi presentation at the FDO2022, Leiden, the Netherlands. Credit: Plazi.
***
Ahead of FDO2022, all submitted conference abstracts – including the one associated with Plazi’s presentation – were made publicly available in a collection of their own in Pensoft’s open-science journal Research Ideas and Outcomes (RIO). Thus, not only did the organisers make the conference outputs available to the participants early on, so that they can familiarise themselves with the upcoming talks and topics in advance, but they also ensure that the contributions are permanently preserved and FAIR in their own turn.
The conference collection, guest edited by Tina Loo (Naturalis Biodiversity Center), contains a total of 51 conference abstracts, where each is published in HTML, XML and PDF formats, and assigned with its own persistent identifier (DOI) just like the collection in its entirety (10.3897/rio.coll.190).
***
Read more about the declaration and sign it yourself from this link. You can also follow the FDO Forum on Twitter (@FAIRDOForum).